
14 天前
14 天前
2026年GTC大会上,黄仁勋的一句话让AI圈炸开了锅——他要把单集群GPU数量从72颗直接拉到1152颗。要知道,就在两年前,他还坚称光互连太耗电,是铜缆的坚定支持者。而现在,他一口气砸了60亿美元给三家光学公司,赌的就是光互连能打破铜缆画下的算力牢笼。这背后藏着AI超级计算的核心困境:当我们需要训练万亿参数模型、跑通通用AI时,铜缆的物理极限,已经成了AI算力增长的天花板。为什么铜缆突然不够用了?光互连又凭本事能接棒?
你可以把AI集群的互连系统想象成城市的道路网:GPU是办公楼,数据是车流,而铜缆就是连接它们的街道。在NVL72机柜里,5000多根铜缆像毛细血管一样缠满整个机架,总长超过3.2公里,占了机柜1.36吨自重的大头。之所以要把9块NVSwitch交换机死死卡在机柜正中央,是因为铜缆里的电信号在1.8TB/s的带宽下,跑不了1米就会开始衰减——就像车流在窄巷里挤得寸步难行,必须让每个GPU到交换机的距离都最短。
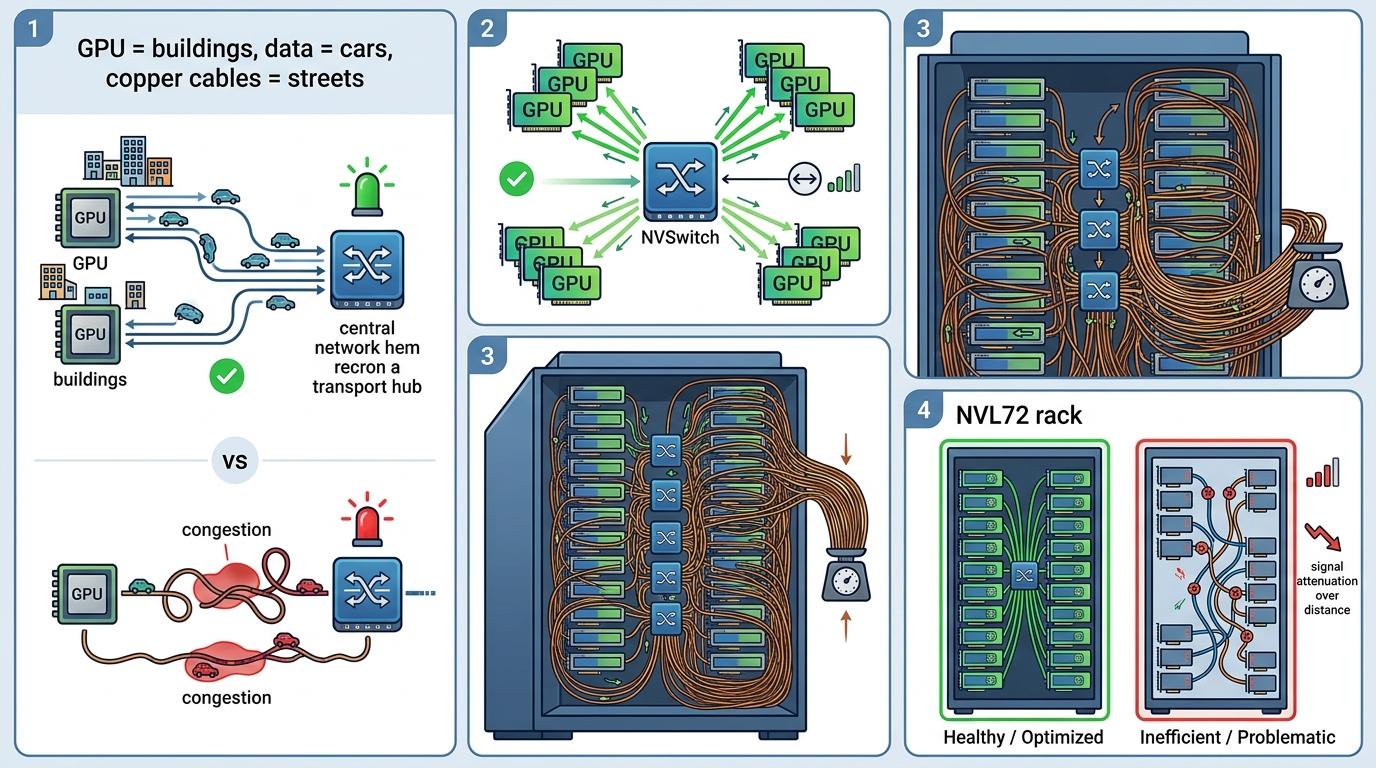
铜缆曾是无可争议的最优解:它便宜,无源器件几乎不耗电,还不像光模块那样有激光器老化的问题,在百万级链路的集群里故障率极低。NVL72靠这套铜缆方案,把72颗GPU拧成了一个超级计算单元,推理速度比上一代快30倍。但问题也摆在眼前:铜缆的传输距离就像城市道路的长度上限,再宽的巷子也只能在小区里打转,连不成跨区的高架。当AI模型需要几千颗GPU协同计算时,铜缆就成了把算力困在笼子里的那把锁。
光互连不是新鲜事,数据中心的机柜之间早就用光纤传数据了,但要把光用到GPU内部的「小区道路」上,难度堪比把高铁轨道铺进胡同。传统的可插拔光模块就像带轮子的高铁车厢,不仅占地方,单个模块功耗10-15瓦,72颗GPU装下来要多耗20千瓦——对已经吃120千瓦电的机柜来说,这无疑是雪上加霜。
改变局面的是共封装光学(CPO)——简单说就是把光引擎直接焊在交换芯片的封装里,省掉了光模块的外壳、连接器和大部分信号处理电路,就像把高铁轨道直接接到了办公楼的地下室。电信号不用再走几十厘米的PCB线路,直接在毫米级的距离里转换成光信号,功耗一下子降了65%-73%,体积也缩小了一大半。
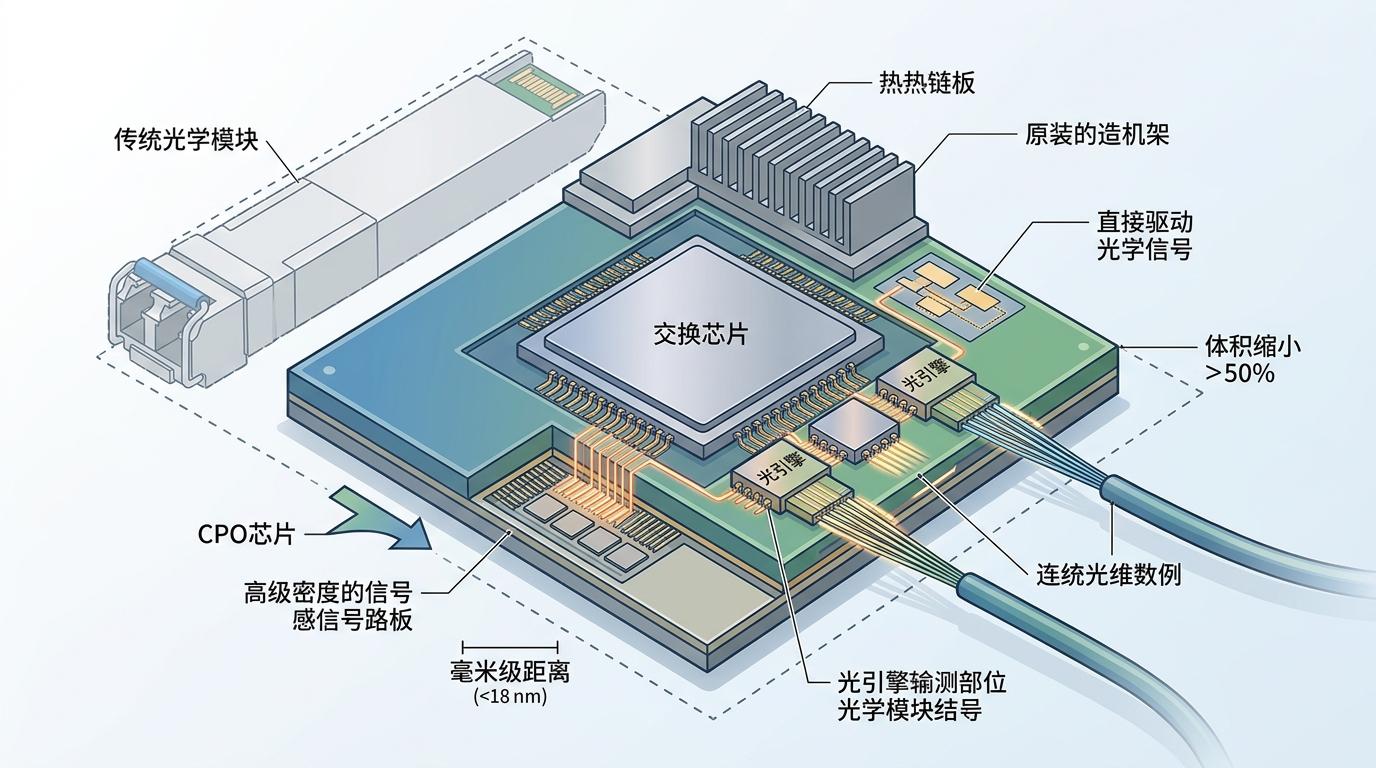
英伟达在2025年先把CPO用在了机柜间的「高架路」上,验证了技术可行性,现在要把它铺进GPU集群的「内部道路」。到2028年的Feynman系统,他们甚至计划把CPO直接集成到GPU封装里,让几千颗GPU之间的光信号传输像在同一个房间里递东西一样快。
英伟达砸的60亿美元,其实是在抢光互连供应链的船票。CPO的核心瓶颈是激光器——就像高铁的发动机,全球能稳定供货的厂商屈指可数。英伟达给Coherent和Lumentum各投20亿美元,直接锁定了未来几年的激光器产能,相当于把高铁发动机的生产线包了下来;给Marvell的20亿美元,则是要拿下硅光子技术,把光信号的「铁轨」做得更宽更稳。
这套路像极了他们之前锁HBM内存和CoWoS封装的操作:在技术拐点到来前卡住上游,让竞争对手慢半拍。当AMD、Intel的开放互连标准UALink要到2027年才能规模部署时,英伟达的光互连集群已经能跑1152颗GPU了。更关键的是,光互连不仅是把GPU数量变多,更是让AI模型能真正实现「全局思考」——几千颗GPU像一个大脑的神经元那样协同,而不是各自为战的小作坊。
当然,铜缆并没有被淘汰。就像城市里依然需要小巷子,机柜内部的短距离连接,铜缆还是最经济可靠的选择。英伟达的路线图是「铜光混合」:短距离用铜,长距离用光,把两者的优势捏到一起。
当我们谈论AI算力的增长时,往往只盯着GPU的芯片架构,却忽略了连接它们的「神经纤维」。铜缆给AI带来了第一个黄金时代,但物理定律的天花板,终究要靠更精妙的技术突破。
从72到1152,数字的背后不是简单的数量叠加,而是AI超级计算从「单栋写字楼」到「整个城市」的跃迁。光互连不是要取代铜缆,而是要给AI算力搭起更辽阔的骨架——让万亿参数模型不再是实验室里的奢侈品,让通用AI的梦想能走得更远。
算力的边界,终究由连接定义。
点击充电,成为大圆镜下一个视频选题!