对抗知识焦虑,从看懂这条开始
App 下载
AI没学过3D,却比谁都懂空间
生成模型|空间理解|百度|华中科技大学|VEGA-3D框架|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载生成模型|空间理解|百度|华中科技大学|VEGA-3D框架|多模态视觉|人工智能
你有没有想过,一个只会画2D视频的AI,其实在脑子里偷偷建了个3D世界?当它生成一段镜头旋转的视频时,沙发不会突然变成长椅,杯子不会穿透桌面——这些我们觉得理所当然的细节,背后是它对物体遮挡、透视规律、空间距离的精准理解。
华中科技大学与百度的联合团队最近捅破了这层窗户纸:那些在海量视频里训练出来的生成模型,根本不需要人类喂给它3D点云、深度图这类昂贵标注,早就悄悄把物理世界的空间逻辑刻进了参数里。他们用一个叫VEGA-3D的框架,把这些藏在模型里的「空间密码」挖了出来,结果让AI的3D理解能力直接跳了一个台阶。这一切,居然没用到哪怕一份额外的3D标注数据。
过去要让AI理解3D空间,就像教孩子学几何——得先给它一堆点云、深度图当课本,再塞进复杂的3D重建模块当练习册。但高质量3D标注数据的成本,比给整个城市做一次CT扫描还贵,而且模型学出来的东西,换个场景就容易「水土不服」。
这次的研究团队反其道而行之:既然视频生成模型为了画出连贯的画面,必须搞懂「物体在不同视角下的样子」「移动时怎么遮挡背景」这些空间规则,那为什么不直接把它脑子里的知识「抠」出来用?
他们把训练好的视频扩散模型冻住,当成一个「潜在世界模拟器」——就像一个装着物理规则的黑箱子。通过在模型去噪的中间阶段注入特定噪声,提取出它在「半梦半醒」状态下的时空特征:这时候的特征刚好平衡了底层纹理和高层抽象,没有被表面细节干扰,藏着最纯粹的3D结构先验。
怎么证明生成模型真的懂3D?团队找到了一个关键指标:多视角一致性。
简单说就是,给模型看同一个物体的不同视角照片,它脑子里对应这个物体的特征得是一致的——就像你从正面和侧面看一个杯子,知道这是同一个东西。如果模型做不到这一点,说明它只是在记像素的组合,根本没理解物体的3D结构。
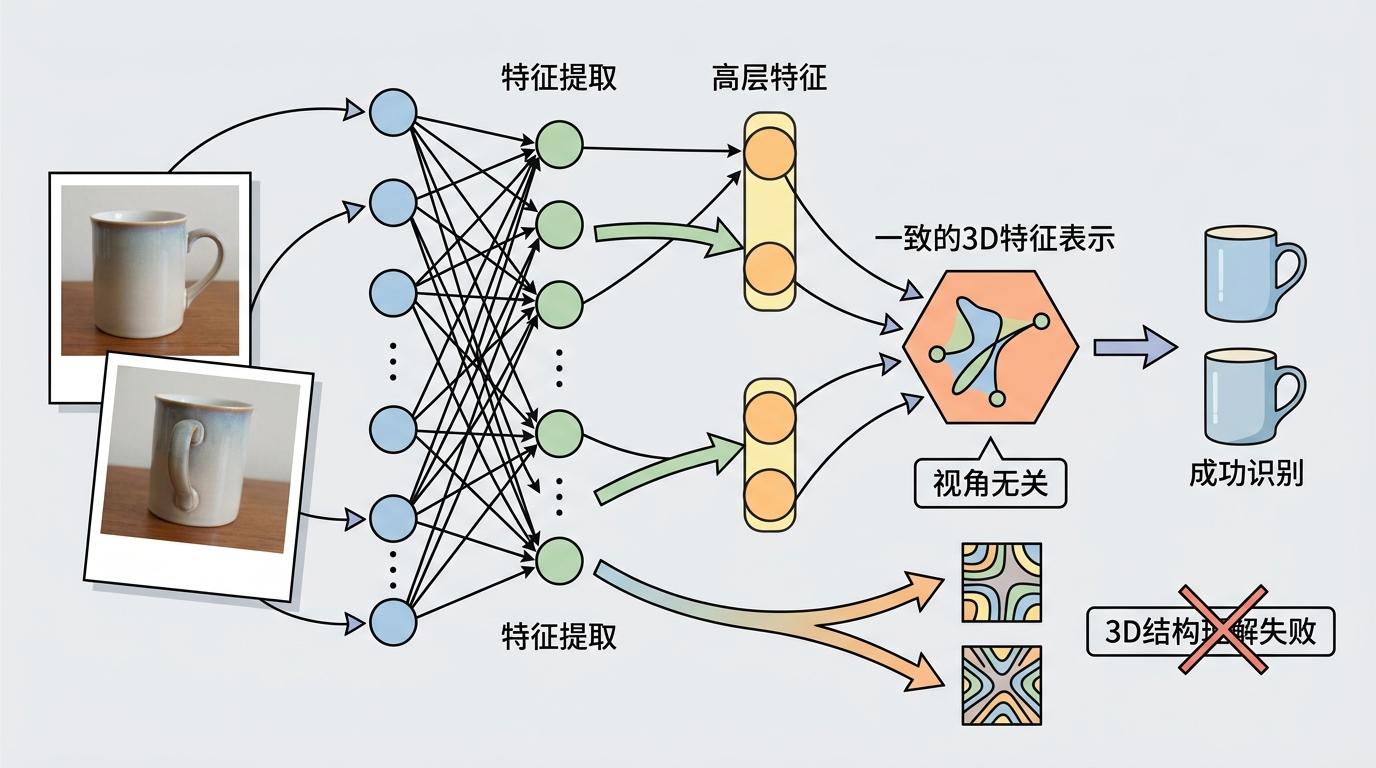
实验数据给了最直接的答案:传统判别式模型的多视角一致性得分最高只有77%左右,而视频生成模型Wan2.1的得分超过了97%。更重要的是,这个得分和AI在3D理解任务上的表现高度正相关——得分越高,定位物体、回答空间问题的准确率就越高。
VEGA-3D的核心,就是把这些多视角一致的特征,和AI原有的语义特征融合起来。这里的关键是一个「Token级自适应门控」:就像给每个信息片段装了个智能开关,当AI需要回答「这是什么」时,就多开一点语义特征的门;当需要回答「它在哪里」时,就多开一点空间特征的门,完美解决了两种特征的「语义-几何鸿沟」。
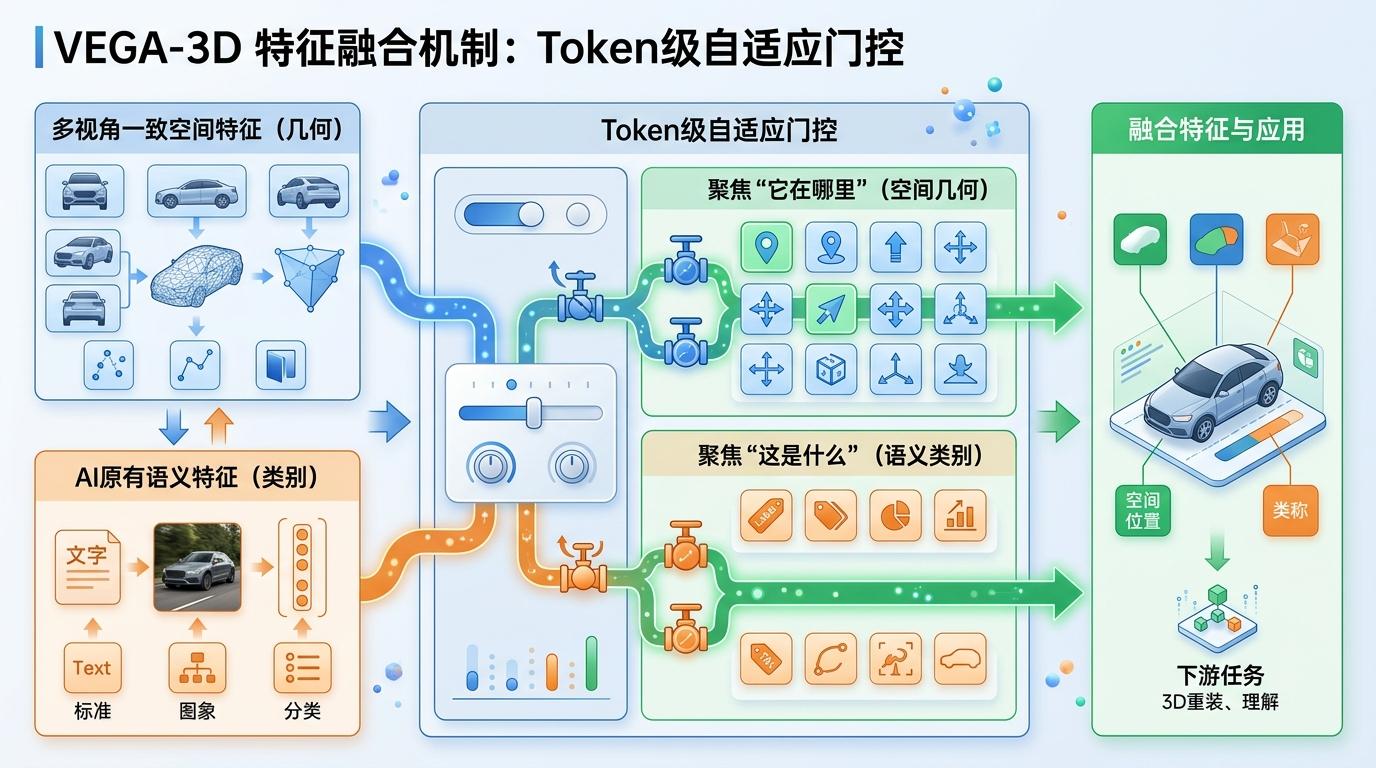
这套方法的效果,在实打实的任务里体现得淋漓尽致。
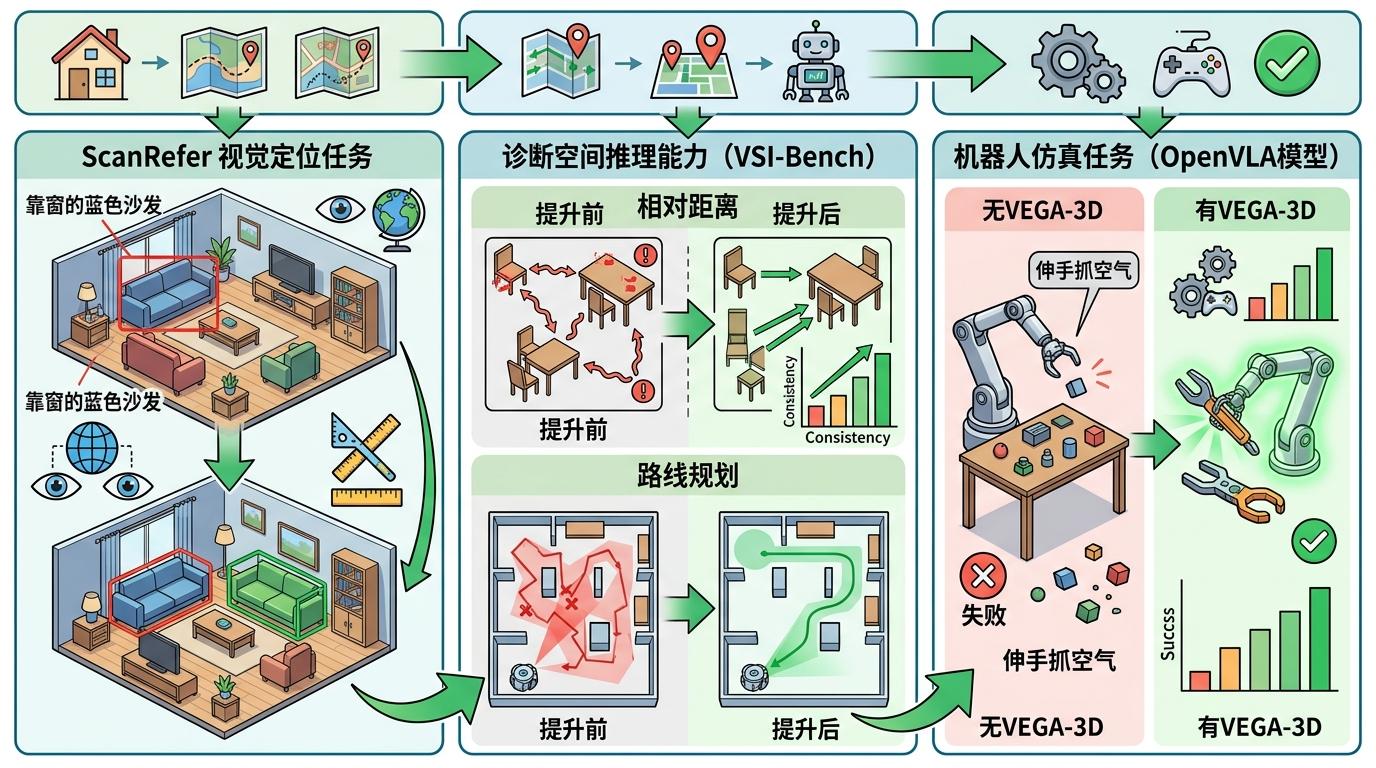
在ScanRefer视觉定位任务中,AI根据自然语言描述找物体的准确率,从51.7%直接跳到了56.2%——相当于在一个堆满家具的房间里,能更精准地定位到「靠窗的蓝色沙发」;在诊断空间推理能力的VSI-Bench上,AI在相对距离、路线规划等子任务上的表现一致性暴涨;最硬核的是机器人仿真任务,给OpenVLA模型装上VEGA-3D的空间先验后,它在复杂物体交互和长视野任务上的成功率直接冲到了97.3%,再也不会出现「伸手抓空气」的尴尬。
当然,这套方法也有局限:它高度依赖生成模型的质量,要是生成模型本身的空间认知就有偏差,挖出来的「宝藏」也会有问题。而且目前它还只能处理静态或慢动态场景,面对高速运动的物体,多视角一致性的特征提取还需要优化。
当我们还在纠结怎么给AI喂更多3D数据时,却忘了它早已在海量视频里偷偷学会了空间。VEGA-3D的意义,不只是提升了几个任务的准确率,更重要的是它打破了一个思维定势:AI的能力不一定非要人类手把手教,很多时候,我们只需要找到打开它「知识库」的钥匙。
好的AI,从来都是自己偷偷成长。 未来随着视频生成模型的进化,这些藏在参数里的空间、物理甚至常识知识,会成为AI理解世界的新底座——或许不用太久,我们就能看到一个真正能「看懂」三维世界的AI,在机器人、自动驾驶、元宇宙里大显身手。