
1 天前
1 天前
某企业客服团队为了压Token成本,把所有对话都切到最便宜的轻量模型,结果客户投诉率飙升30%——每解决一个工单的实际成本反而涨了2倍。这不是个例:2026年全球Token消耗量同比暴涨10倍,企业一边盯着账单叫苦,一边陷入“省Token=降成本”的误区。当你还在抠每百万Token的单价时,头部公司已经在算“每解决一个业务问题花了多少Token”。这场从“数Token”到“算价值”的转向,才是AI成本治理的核心。
你可以把大模型的分层路由想象成公司的部门分工:CEO(前沿大模型)只做战略决策,基础行政(简单任务)交给实习生(轻量模型)。这种“任务-模型”的精准匹配,能直接砍掉40%-60%的无效成本。
具体来说,就是建立三层模型梯队:Tier1的GPT-4o、Claude Opus这类顶尖模型,只负责复杂推理、长上下文综合、创造性写作这类高价值任务;Tier2的中端模型处理结构化数据提取、中等复杂度摘要、标准问答,承担企业70%-80%的日常业务;Tier3的开源小模型或专用微调模型,专门解决二分类、实体识别、格式转换这类机械性工作,成本甚至不到Tier1的1/10。
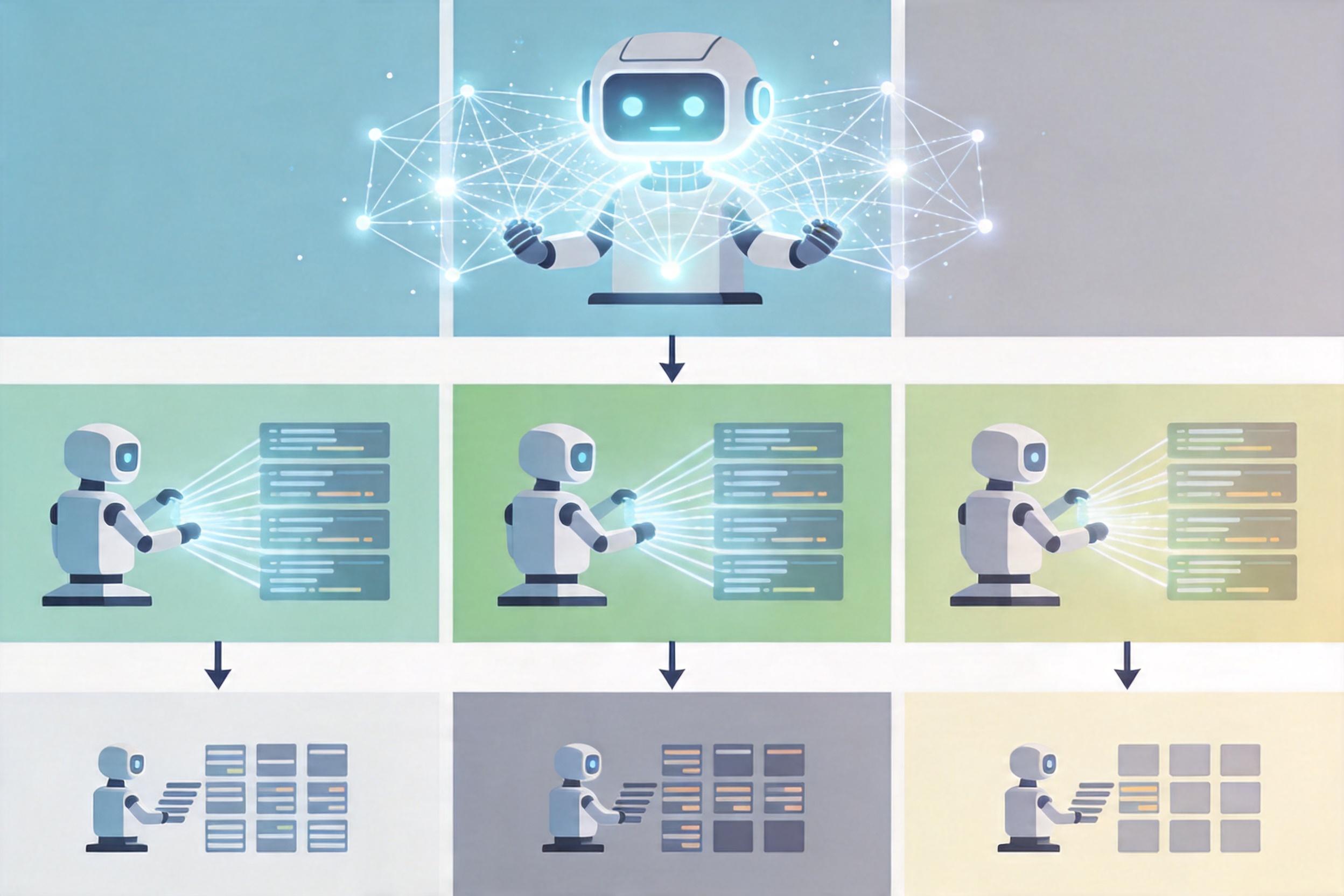
实现这种路由的关键是动态决策:用一个轻量模型先对输入任务做“复杂度打分”——比如判断是否需要多步推理、结果错误的容忍度有多高、上下文长度多少——再自动匹配到对应层级的模型。云天励飞的实践显示,这种策略让他们的Token成本直接下降了52%,同时核心任务的完成质量没有任何损失。
你有没有过这种经历:和AI聊了十几轮后,它的回复越来越慢,账单也悄悄涨了?这是因为每轮对话的上下文都会被完整传入模型,Token数像滚雪球一样累积——而KV缓存技术,就是给这个雪球装个刹车。
KV缓存的本质是“记忆复用”:Transformer模型在处理每一个新Token时,会把之前计算过的注意力结果(Key和Value)存在缓存里,不用每次都重新计算。但传统的KV缓存会把所有历史上下文都存下来,内存占用和Token消耗还是会持续增长。现在的优化方向是“动态缓存筛选”:用算法实时判断哪些上下文信息对当前任务没用,直接从缓存里删掉。比如在多轮客服对话中,用户半小时前提过的地址信息,在当前询问订单状态时完全不需要,就可以被剔除出缓存。
通义千问3.5这类模型已经把KV缓存压缩机制集成到了架构里,能自动剔除冗余的上下文信息。九章云极的测试数据显示,这种优化能让重复计算减少至少10%,长对话场景下的Token成本直接下降30%以上,同时响应速度提升了25%。
当企业的AI应用从“尝鲜”进入“规模化”,单纯的技术优化已经不够了——你需要一套像管理财务一样管理Token的机制,也就是AI FinOps。
云器科技的实践是,先给每个业务线建立“Token预算池”,实时监控Token消耗和业务成果的对应关系:比如客服团队的Token消耗要和工单解决率、客户满意度挂钩,研发团队的Token消耗要和代码生成效率、Bug修复率绑定。一旦发现某条业务线的“单位业务成果Token成本”异常升高,就触发优化流程:要么是提示词太冗余,要么是用了过高层级的模型,要么是业务流程有冗余。
还有一个容易被忽略的细节:数据格式对Token消耗的影响。同样一份用户数据,用JSON格式传输需要30个Token,换成专门的Token高效格式ToON只需要11个——百万级别的数据量下,这就是数百万Token的差距。现在已经有企业开始把“Token友好”作为数据格式选型的标准之一。
当你把Token当成“成本”时,看到的永远是账单上的数字;但当你把Token当成“生产资料”时,看到的是每个Token能创造的业务价值。
未来的AI成本治理,不会是一场“比谁的Token更便宜”的价格战,而是一场“比谁的Token效率更高”的价值竞赛。那些能把每个Token都用在刀刃上的企业,会在这场竞赛中跑在最前面。毕竟,Token的价值,从来不在数量,而在落地。
点击充电,成为大圆镜下一个视频选题!