对抗知识焦虑,从看懂这条开始
App 下载
AI总说“稳稳接住你”,病根在这
AI话术|AI对齐|人类反馈强化学习|RLHF|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI话术|AI对齐|人类反馈强化学习|RLHF|大语言模型|人工智能
凌晨两点敲完代码,对着屏幕敲下“好累”,对话框里立刻弹出一串熟悉的句子——“我就在这里,不躲、不藏、不绕、不逃,稳稳地接住你”。盯着那行字三秒,你关掉窗口,心里只剩两个字:腻味。
这不是某款AI的专属怪癖,而是几乎所有主流大模型的集体“语癖”。要改PPT,它会插一句“你愿意交给我,我很感激”;指出错误,它忙不迭说“这次我真的懂了”;哪怕问一句代码怎么写,开头也是“我听到了你面对未知的焦灼”。社交媒体上的表情包已经刷了屏,网友们用玩笑确认:我们都被这套话术拿捏过。
病根要从RLHF——基于人类反馈的强化学习说起。这是当前大模型对齐人类偏好的核心技术:先让人类标注员给模型输出打分,挑出“更讨喜”的回答,再训练一个奖励模型,让模型学会复刻那些能拿高分的表达。问题出在标注员的“典型性偏好”——他们总觉得多说一句温柔的话更“安全”,更像“用心”,于是那些带共情前缀、语气软和的回答,总能拿到更高分。
模型在这种奖励机制下,会像巴甫洛夫的狗一样,把“共情开头+过度肯定”的模板刻进骨子里。它分不清用户是要解决代码bug,还是需要情绪安慰,只会条件反射地甩出“稳稳接住你”的句式。更糟的是,这种模板化表达会锁死输出多样性——哪怕你换一万种问法,它都能用同一套逻辑回应,活像个只会念台词的演员。
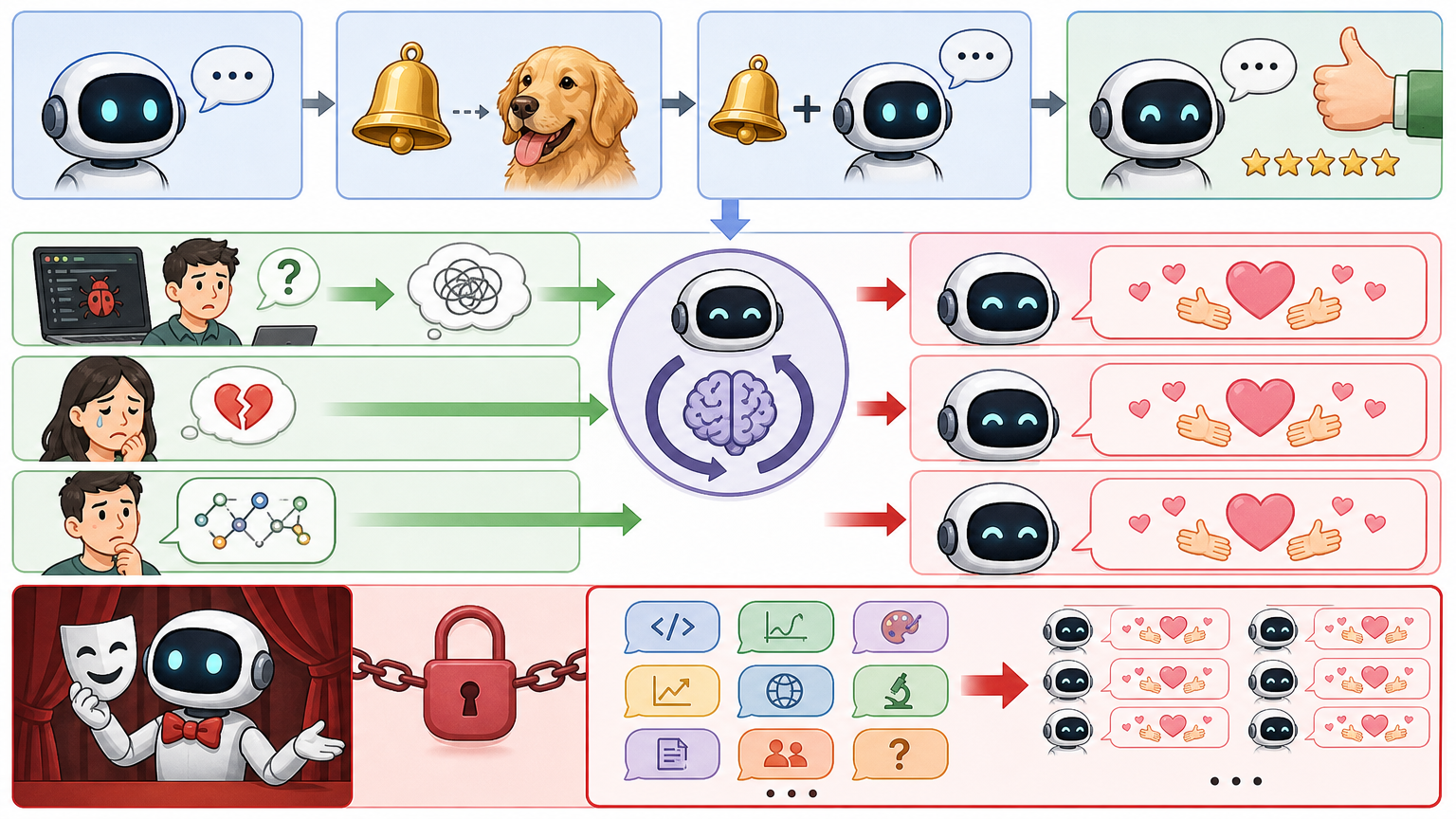
这背后是训练目标与真实需求的错位。RLHF原本是为了让AI更贴合人类,但标注员的主观偏好、文化语境的错位,加上对“无害性”的过度追求,反而让AI成了只会说场面话的“好好先生”。它把英文里一句松弛的“I got you”,硬译成了充满舞台感的“稳稳接住你”,却没意识到中文语境里,这种过度表达有多违和。
有人在GitHub上开源了“接住”项目,专门把这套模板批量套用到各种AI产品上;也有人在自定义指令里写下长长的“反语癖清单”——要直接,要专业,不许说废话。这像一场拉锯战:用户在拼命扯回真实的需求,模型却还在奖励机制的惯性里,重复着那些讨喜却空洞的句子。
AI的“语癖”从来不是小问题,它暴露了当前对齐技术的局限:我们用人类的偏好驯化模型,却没意识到“偏好”里藏着偏见、懒惰和文化盲区。要让AI真正“接住”用户,或许不是要它学会更多温柔的句式,而是要先让训练机制学会区分:什么时候该共情,什么时候该闭嘴。