对抗知识焦虑,从看懂这条开始
App 下载
改AI图像不再毁背景,靠的是这步对齐
背景保真|图像反演|AI图像编辑|误差累积|DirectEdit|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载背景保真|图像反演|AI图像编辑|误差累积|DirectEdit|多模态视觉|人工智能
你一定有过这种崩溃:想用AI把照片里的狗换成猫,结果猫是换了,沙发却歪成了波浪线,窗外的树也糊成了一团马赛克——就像整幅图被无形的手揉过。这不是AI偷懒,是它得了一种叫「误差累积」的慢性病:每一步编辑的微小偏差都会像滚雪球一样放大,最后把原本好好的背景彻底带歪。直到2026年5月,DirectEdit的出现给这个顽疾开出了药方:它没有去修正那些滚大的雪球,而是从一开始就让每一步都走在精准的轨道上。
要理解这个问题,得先搞懂AI编辑图像的基本逻辑:它会先把原图「反演」成一堆噪声,再从噪声出发,按照你的指令生成新图。就像把一幅画拆成颜料粉,再用这些粉重新画画。 但问题出在「拆画」的过程里。AI没法精准算出每一步该怎么拆,只能用近似值代替,每一步都差那么一点点——就像你拼图时每块都偏了1毫米,100块拼完,整幅图就歪出了半尺。这种「步骤级误差」会在后续的重建过程中不断累积,最后背景扭曲、细节丢失,变成你不想看到的样子。 过去的方法要么用更精密的「拆图工具」减少单步误差,要么在拼完后手动修正,但都没解决根本问题:只要拆和拼的轨道不一样,偏差就一定会越来越大。
DirectEdit的思路简单到让人拍大腿:既然修正拆图的轨道太难,那就让拼图的轨道完全跟着拆图的走。 它在「拆图」(反演)时,会记录下每一步噪声变化的「残差」——也就是这一步实际走的轨道和理想轨道的差值。等到「拼图」(重建)时,它会把这些残差一步步加回去,让每一步的拼图轨道和拆图轨道严丝合缝。
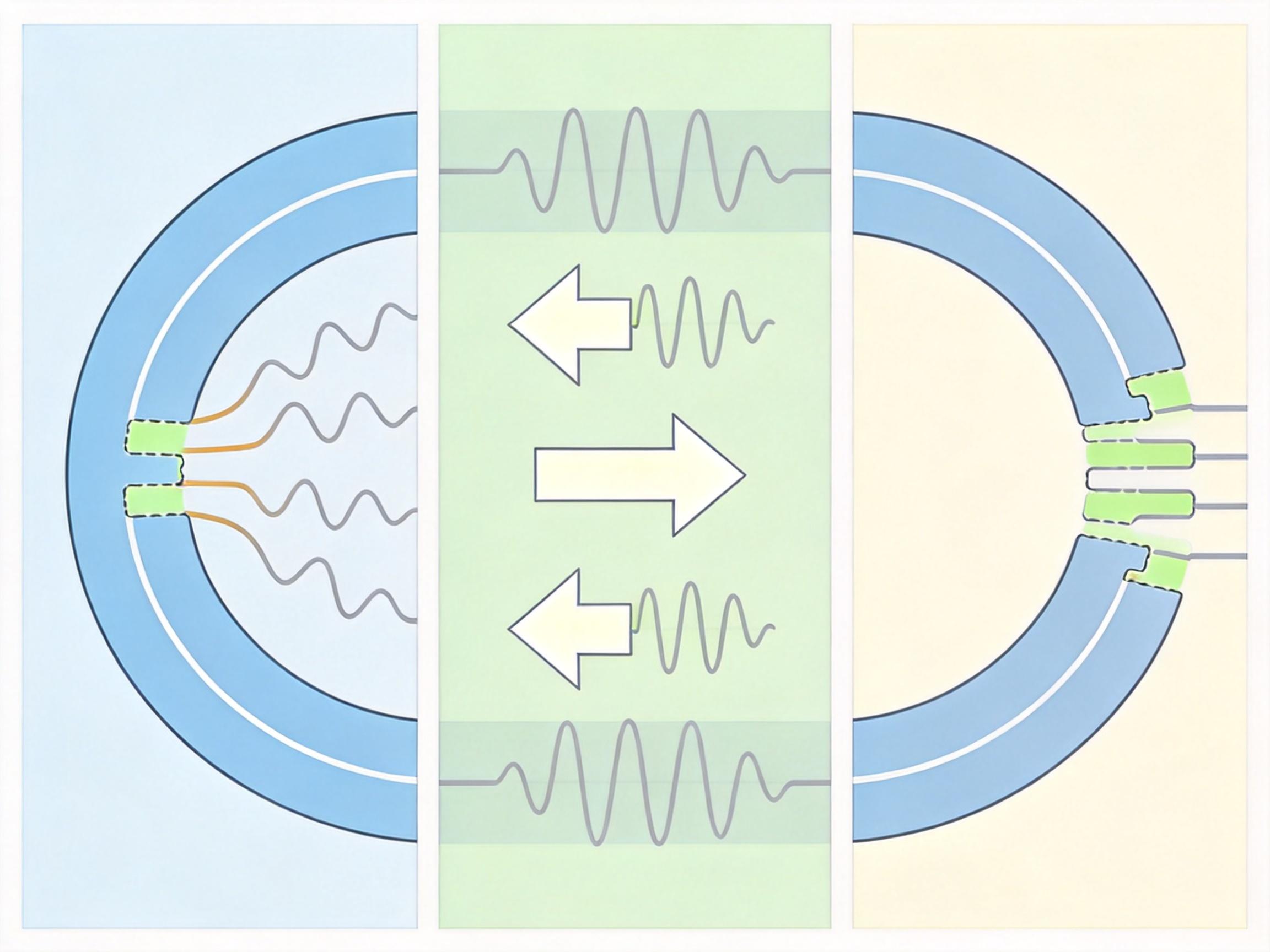
你可以把它想象成:拆画时在每块颜料粉上都做了标记,拼画时严格按照标记的位置摆放,每一块都不差。从数学上看,这直接保证了每一步的重建误差为零——仅受电脑浮点精度的影响,相当于从根源上掐断了误差累积的可能。 更难得的是,这个过程不需要额外训练模型,也不增加计算负担,只需要几行代码就能实现。
光有精准重建还不够,编辑得能「指哪打哪」。DirectEdit还加了两道保险: 第一道是「多分支掩码融合」。它会先用AI分析你的编辑指令,比如「把狗换成猫」,再用图像分割模型精准圈出狗的区域,生成一个「掩码」。重建时,非编辑区域(比如沙发、窗户)严格用原轨道的潜变量,保证背景丝毫不改;只有掩码圈出的区域用新指令生成的内容。

第二道是「注意力特征注入」。它会把原图的语义细节,比如猫的毛发纹理、眼神,注入到编辑区域的生成过程中,避免AI生成的猫和原图风格脱节。针对不同的模型架构,它还会调整注入的位置和次数,在保留细节和满足编辑需求之间找到平衡。 在PIE-Bench基准测试中,DirectEdit的背景保持指标全面领先:PSNR(峰值信噪比)比传统方法高出5个点,MSE(均方误差)仅为第二名的三分之一——也就是说,它生成的背景和原图几乎看不出差别。
当然,DirectEdit也不是万能的。它没法处理需要三维几何理解的编辑,比如把猫的体型放大一倍,或者把它从沙发上移到地上——这是底层流模型的局限,不是它的问题。而且它依赖AI生成掩码,如果AI没读懂你的指令,后续的编辑也会出错。 但不可否认,它给AI图像编辑指了一条新的路:与其在误差出现后拼命修正,不如从一开始就避免误差的累积。精准的轨道,比精密的修正更重要。这不仅是AI图像编辑的突破,也是所有技术创新的共通逻辑:找到问题的根源,往往比在表面上修修补补更有效。