
1 天前
1 天前
当你刷到AI生成的1分钟高清视频时,可能以为技术已经触达天花板——但事实是,这只是AI模拟真实世界的「热身运动」。我们需要的不是几十秒的视觉奇观,而是能像《西部世界》那样,持续推演物理规律、响应实时交互的「世界模拟器」:让机器人在虚拟空间预演复杂操作,让自动驾驶在仿真街景里练会应对极端路况,让游戏NPC根据你的选择生成连贯剧情。可现在的AI视频模型,就像一台油耗惊人的超跑,酷是酷,却开不远、跑不快。香港大学2026年的一篇综述论文,终于把这台「超跑」的改装方案拆解得明明白白。
你可以把普通AI视频生成模型理解成「高级画师」——它能根据描述画出连贯画面,但不知道画面里的球为什么会落地,不知道推开门时门轴应该怎么转。而「世界模拟器」是「导演+物理学家」:它脑子里装着一套对世界规律的理解,能根据过去的场景和你给出的动作,推演未来的每一种可能。
这种「理解」来自三个关键能力:首先是通过海量视频训练出的「涌现物理规律」——不用硬编码牛顿定律,它能自己学会流体怎么流动、刚体怎么碰撞;其次是在「潜在空间」里推演,就像用思维导图代替全幅油画,大幅降低计算成本;最后是统一的推理框架,同一个模型既能做电影特效,也能给自动驾驶当仿真工具。
但这一切的前提是「效率」。视频是三维数据(时间×高度×宽度),复杂度随时长和分辨率呈立方级增长:生成1小时4K视频的计算量,是1分钟短视频的3600倍。没有效率优化,「世界模拟器」永远只能是实验室里的概念。
香港大学的论文把效率优化拆解成了三层,像给超跑做从引擎到车身的全面改装:
扩散模型是当前AI视频的主流技术,但它生成一帧要迭代去噪几十步,像用砂纸慢慢打磨一幅画。「扩散模型蒸馏」就是把这个过程压缩:训练一个「学生模型」,让它看一遍老师50步打磨的过程,自己学会用5步甚至1步达到同样效果。还有「流式因果扩散」,给模型戴上「只能看过去」的眼罩,让它像写小说一样逐帧生成,既保持扩散模型的画质,又能实现实时交互。
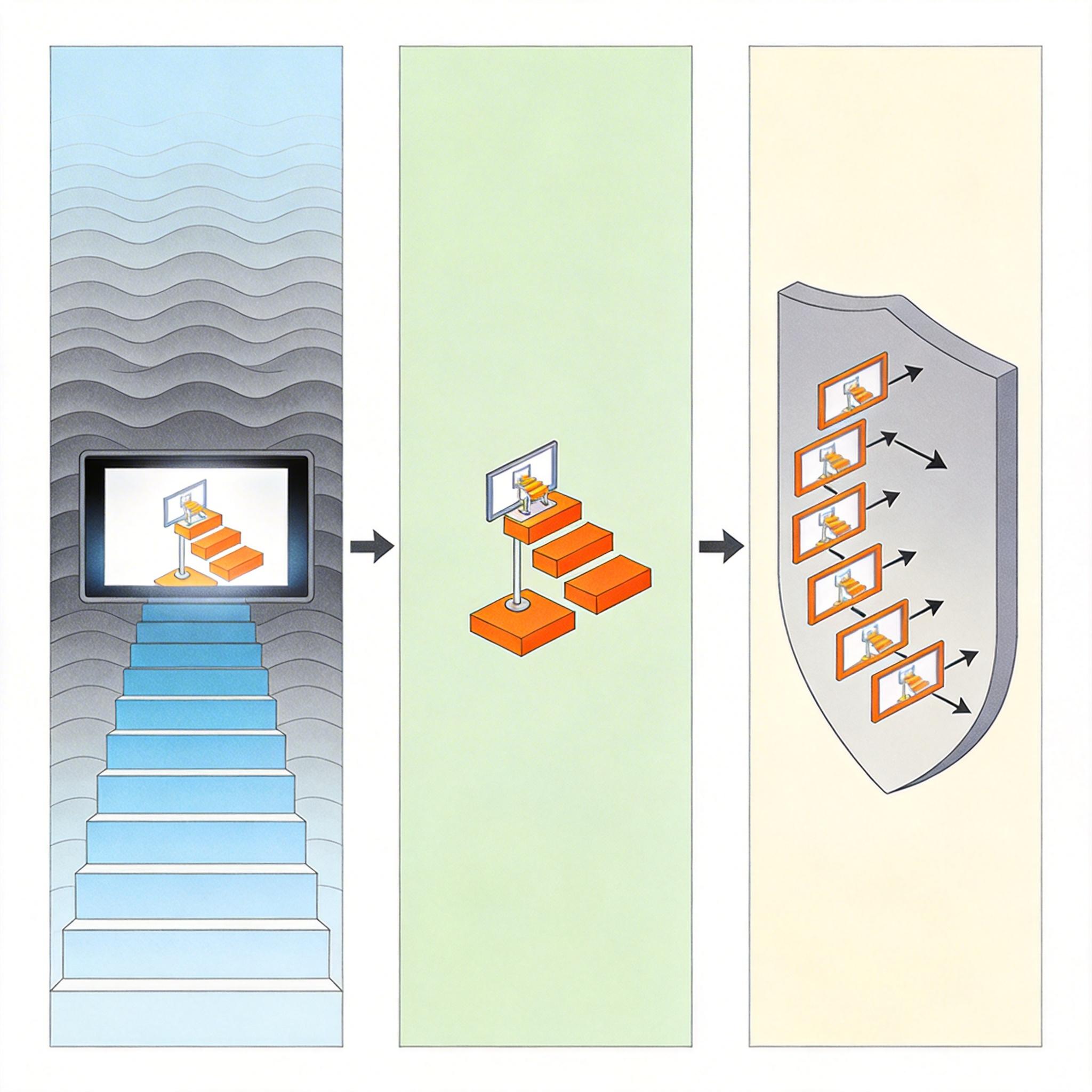
Transformer的全注意力机制,就像让司机同时看遍整条公路的每一个细节,计算量随视频长度呈平方级增长。「高效注意力机制」则让模型只看局部窗口,或者把相似的画面信息合并成一个「令牌」,大幅降低计算量。还有「分层生成」,先画低分辨率的场景草图,再逐步上采样到高清,避免一开始就在像素级做无用功。
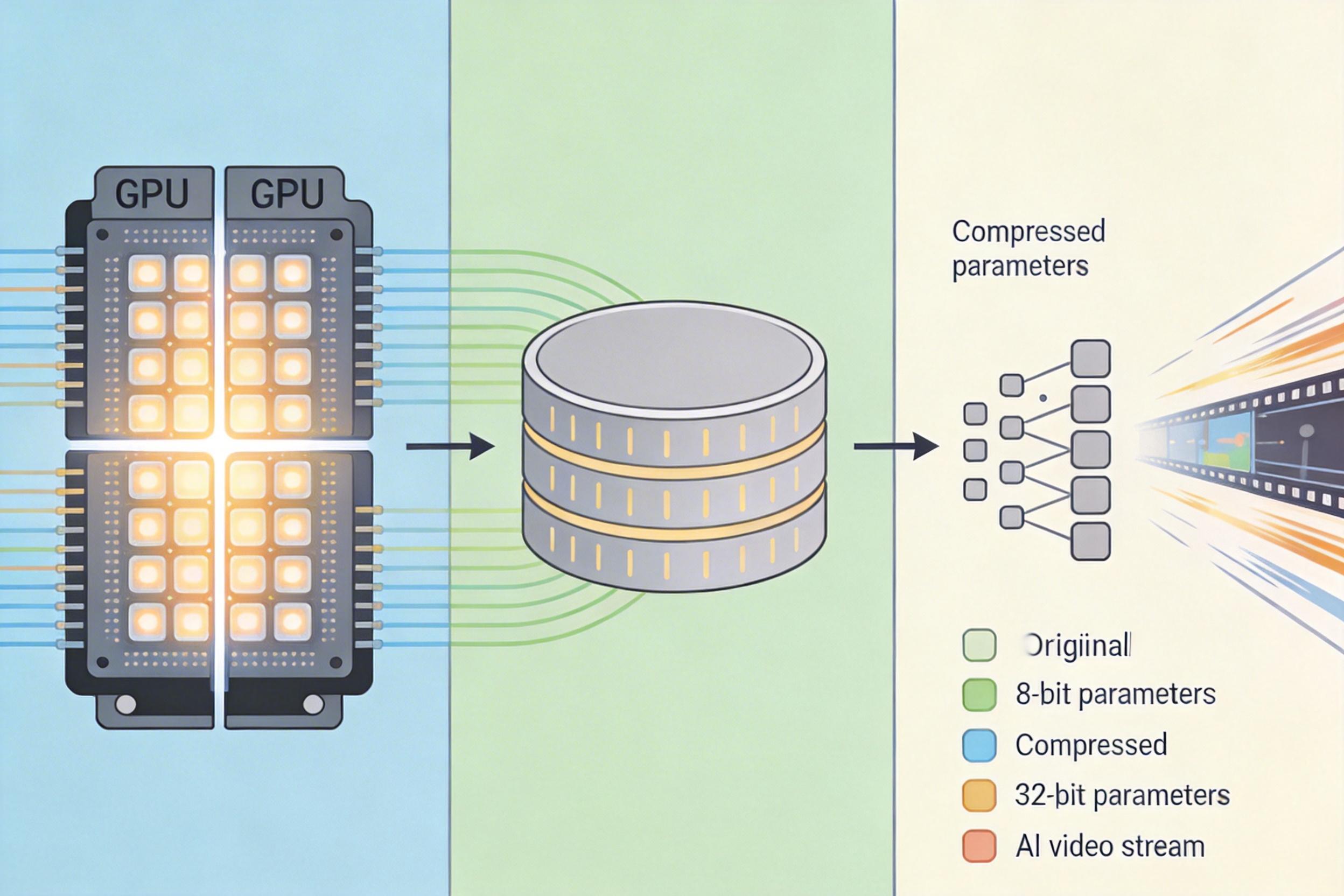
这是系统级的精打细算:用多GPU并行计算把任务拆分到多个核心,用缓存机制避免重复计算历史信息,用模型量化把32位浮点参数压缩到8位,在几乎不损失画质的前提下,把内存占用降低75%。这些优化让AI视频生成的速度提升了数倍甚至数十倍。
效率优化已经让AI视频离「世界模拟器」更近了一步:Waymo用它生成高保真的自动驾驶仿真场景,把测试成本降低了90%;Genesis平台让机器人在「脑内」预演动作,把现实试错的风险降到了零;AI驱动的游戏已经能根据玩家的选择实时生成剧情画面。
但还有三道坎要跨:一是长视频的「漂移问题」——自回归生成就像传话游戏,误差会逐帧累积,几十分钟后可能人物变了样、场景出了界;二是「伪物理」难题——模型学会的是视觉关联,不是真正的物理规律,比如它知道球会落地,但不知道落地的速度和质量的关系;三是实时交互的「最后一公里」——单段生成做到实时不难,但要像游戏一样实现毫秒级响应,还需要系统级的延迟优化。
当我们谈论「世界模拟器」时,我们其实在谈论AI的「想象力」——不是凭空生成画面,而是像人类一样,用对世界的理解去推演未来。效率优化不是简单的「提速」,而是给AI装上了能持续思考的「大脑」,让它从「画一幅画」变成「演一整场戏」。
效率,是AI视频通往世界模拟器的门票。未来的某一天,当你在虚拟世界里推开门,门轴会发出真实的吱呀声,风吹动窗帘的弧度符合伯努利原理——那不是因为程序员写了代码,而是AI真的「懂」了这个世界。
点击催更,成为大圆镜下一个视频选题!