对抗知识焦虑,从看懂这条开始
App 下载
点云AI大瘦身:快2倍还能打
CVPR|激光雷达|3D感知|点云处理|LitePT模型|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载CVPR|激光雷达|3D感知|点云处理|LitePT模型|多模态视觉|人工智能
当自动驾驶的激光雷达每秒吐出百万个3D点,当机器人要在堆满杂物的房间里抓准一个杯子,AI得先把这些混乱的点变成能读懂的信息——这就是点云处理,3D感知的核心难题。过去最先进的AI模型要啃下这块硬骨头,得堆上近5000万个参数,还得让GPU烧半天。但南京师范大学联合团队刚在CVPR发布的LitePT模型,把参数砍到了原来的1/3.6,推理速度快了2倍,内存占用减半,却在所有主流测试里跑赢了前辈。这不是简单的轻量化,而是一次对AI思考方式的重构。
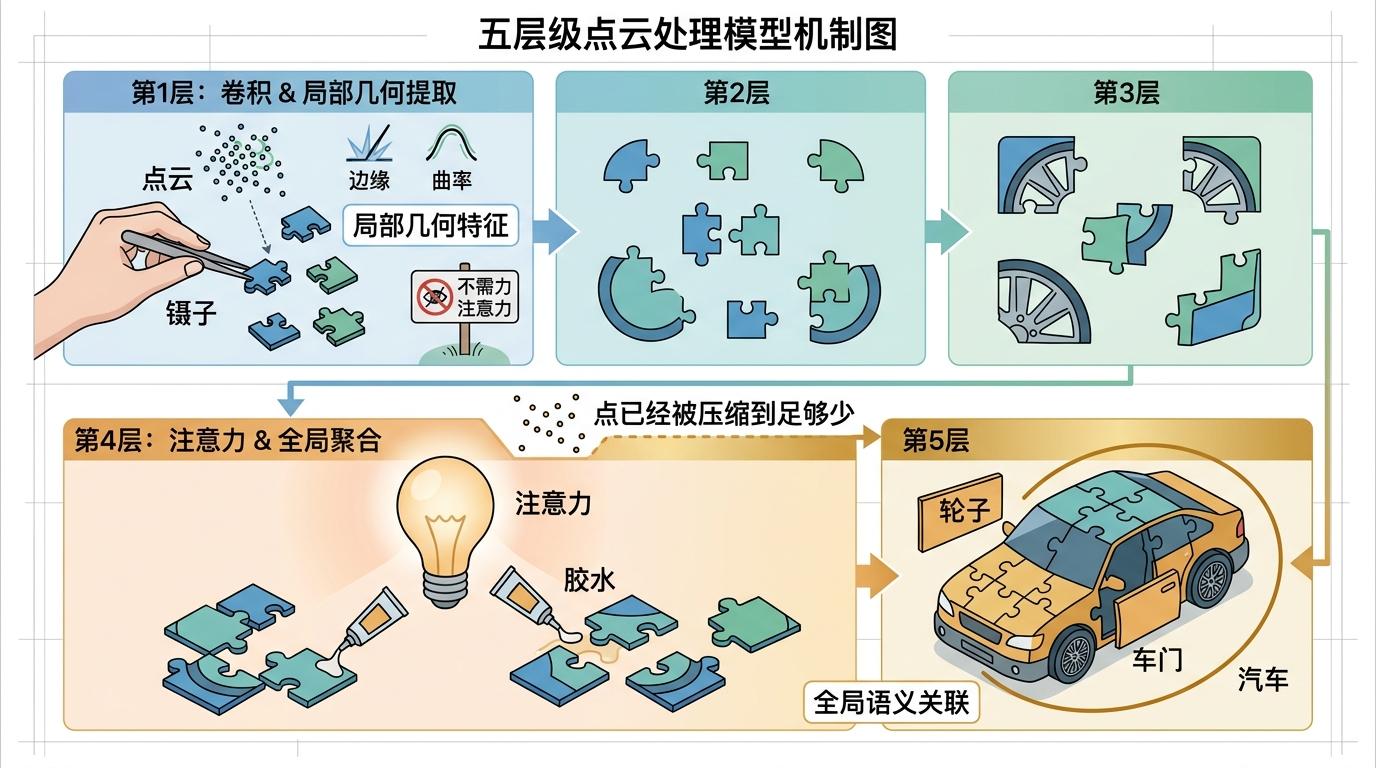
你可以把点云AI的工作想象成拼拼图:一开始要把零散的小色块拼成眼睛、鼻子这些局部细节,后来要把这些局部拼成完整的人脸,理解表情和情绪。过去的模型不管是拼细节还是拼整体,都同时用着两种工具——负责抓局部的「卷积」和负责连全局的「注意力」。
但LitePT团队拆了当前最好的Point Transformer V3模型才发现,这两种工具的使用完全搞反了场景:在拼细节的早期阶段,点的数量多到上百万,注意力机制要逐个计算点之间的关联,不仅慢,还对拼细节毫无帮助,纯纯是浪费算力;到了拼整体的后期,点已经被压缩到几万甚至几千个,卷积的局部视野又不够用,还会凭空堆出大量冗余参数。
团队做了个直白的实验:把早期的注意力模块删掉,模型性能几乎没降,但速度快了一大截;把后期的卷积模块删掉,参数少了2/3,性能反而还升了。原来大家默认的「混合搭配最优」,其实是让AI做了一半的无用功。
LitePT的核心逻辑说穿了很简单:让专业的工具干专业的活。
模型被分成了五个层级,前三层只保留卷积模块——就像拼图时先用镊子精准对齐小色块,高效抓牢点云里的边缘、曲率这些局部几何特征,这时候不需要注意力来凑热闹;到了后两层,点已经被压缩到足够少,再切换成注意力模块,像用胶水把拼好的局部零件粘成整体,高效捕捉全局的语义关联,比如把「轮子」「车门」这些特征拼成「汽车」。
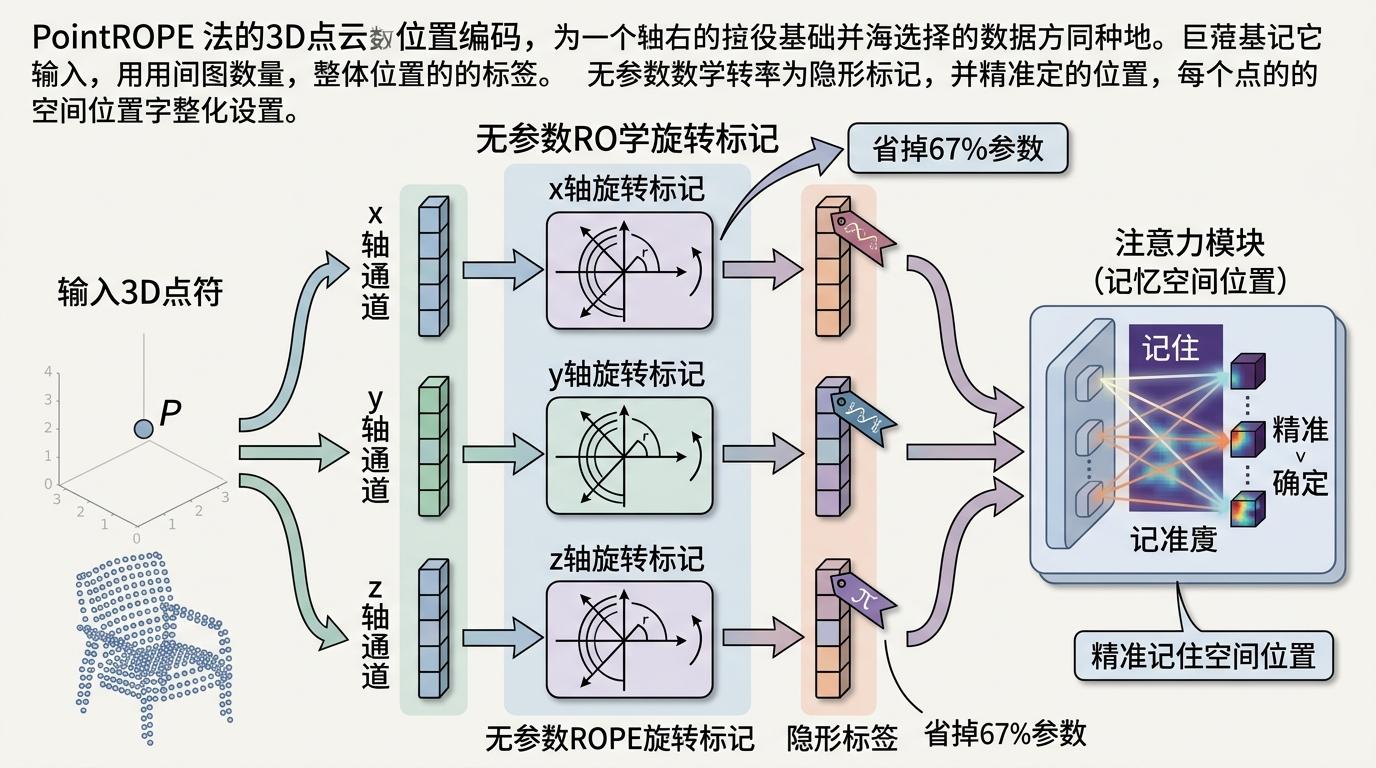
但这里有个问题:注意力机制天生没空间感,删掉卷积模块后,AI会忘了点的位置信息。团队于是给它配了个「免费导航」——PointROPE位置编码。
你可以把PointROPE理解成给每个点贴个带坐标的隐形标签:它把点的三维坐标分成x、y、z三个独立通道,用数学旋转的方式给每个通道的特征做标记,不需要训练任何参数,却能让注意力模块精准记住每个点的空间位置。相比之前用卷积做位置编码的方式,这一步直接省掉了67%的参数。
LitePT的厉害之处,在于它不是为了轻量化而牺牲性能,而是通过精准分工实现了双赢。在自动驾驶常用的Waymo数据集上,它的目标检测精度和Point Transformer V3持平,但推理速度快了2倍;在室内场景的ScanNet数据集上,它的语义分割精度反超了前辈,参数量却只有对方的1/4。
当然它也不是完美的。比如在极端稀疏的点云场景下,它的鲁棒性不如全注意力模型;如果要处理动态点云的实时动作识别,还得在分层切换的时机上做更精细的调整。但它最大的价值,是给3D感知AI指了一条新的路:与其堆参数、拼算力,不如先搞清楚AI在每个阶段到底需要什么。
就像人类干活时,不会用螺丝刀拧螺丝的同时还握着扳手——工具的价值,从来都不在于多,而在于用对地方。
当我们还在惊叹AI能处理越来越复杂的3D数据时,LitePT的出现提醒我们:AI的进化不止是变得更聪明,也可以是变得更高效。它的分层分工思路,其实暗合了人类认知世界的逻辑——先看细节,再拼整体,最后理解意义。
未来的3D感知AI,或许会像一个训练有素的工匠,手里的每一件工具都用在最该用的地方。用对工具,比用好工具更重要。而这种「精准效率」的思路,或许会成为AI从实验室走向真实世界的关键一步。