对抗知识焦虑,从看懂这条开始
App 下载
把VR远程会面的带宽砍去七成,清华团队做到了
3D重建|视频压缩|VR远程会面|GS-SCNet|清华大学|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载3D重建|视频压缩|VR远程会面|GS-SCNet|清华大学|多模态视觉|人工智能
想象你戴着VR眼镜,远在千里的同事正凑在你耳边讨论方案——你甚至能看清他指尖的纹路。这是6G承诺的「终极远程呈现」,但此前它卡在一个死循环里:要传清晰的3D画面,就得把几十路视频压缩到极致;但压缩后的画面,又没法还原出精准的3D场景。直到2026年4月,清华和澳门理工的团队拿出了GS-SCNet:它把视频压缩和3D重建拧成了同一件事,直接砍掉了70%以上的带宽消耗,还让画面更稳更快。为什么之前没人这么干?这得从那个死循环的根源说起。
传统VR远程呈现的流程,像极了两个人同时搬同一块砖:发送端先把多角度视频压缩成码流,这一步要反复比对不同视角的画面,去掉重复内容;接收端解码出2D画面后,3D重建模型又要再做一遍比对,把平面画面拼成立体场景。
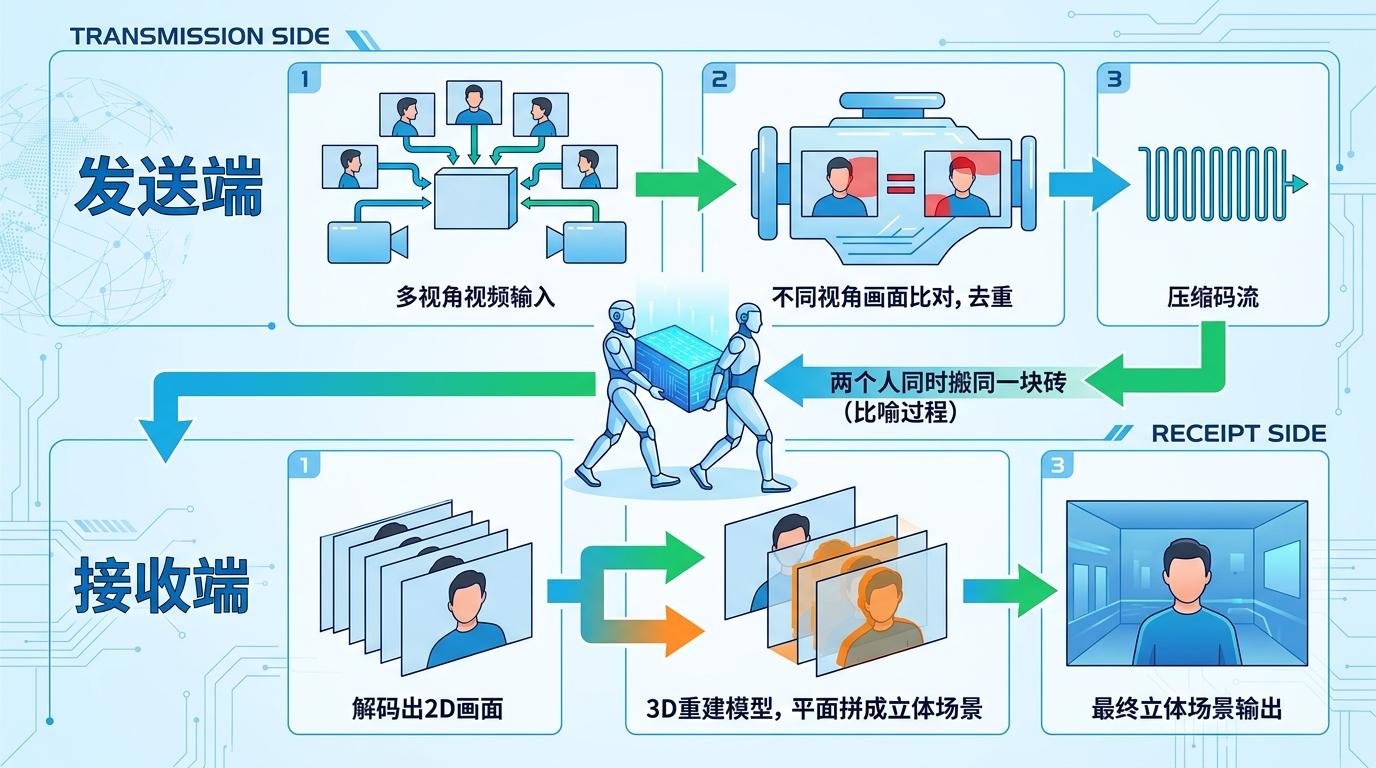
更糟的是,这两个环节的目标完全拧巴:视频压缩只关心「解码后的像素和原图像不像」,哪怕为了保住无关紧要的纹理细节浪费带宽;但3D重建要的是「新视角渲染的画面真不真」,像素完美的画面,可能因为几何信息丢失,一到重建就变成模糊的鬼影。
这就导致了一个荒诞的结果:你花了大价钱买高带宽,传过去的却是对3D重建毫无用处的冗余信息,真正关键的几何细节,反而被压缩噪声冲得稀碎。
GS-SCNet的破局思路,说穿了就是「只搬一次砖」——它把视频压缩和3D重建的核心需求,统一成了「为渲染质量优化」。
你可以把整个流程想象成一场精准的接力:发送端先通过视差估计(简单说就是算左右眼画面的偏移量,直接对应物体的远近),把立体视频的几何信息提取出来;接着用这个视差信息当「向导」,把左右视角的语义特征融合,去掉重复内容后再压缩;接收端拿到解码后的语义特征,直接用一个轻量级预测器生成3D高斯泼溅的参数——不需要再重建像素画面,一步到位输出可渲染的3D场景。
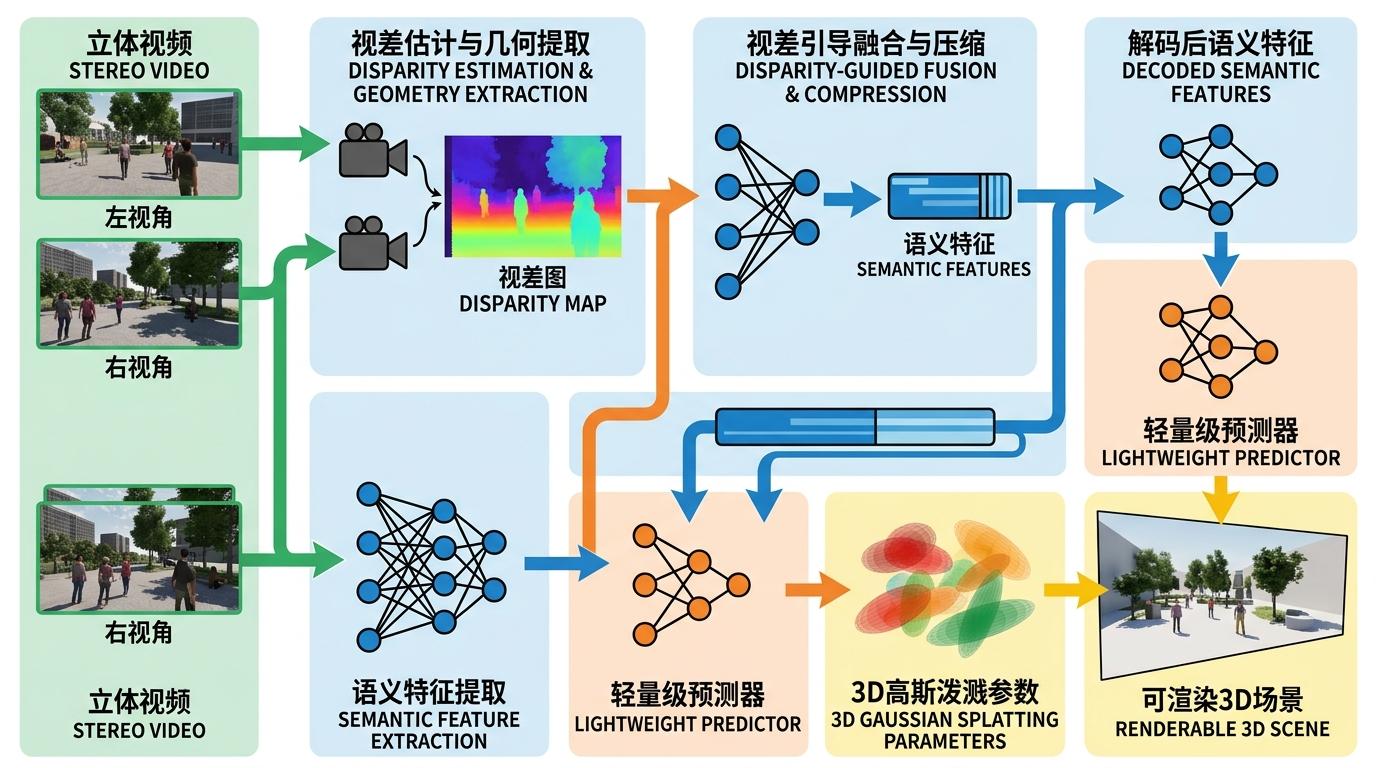
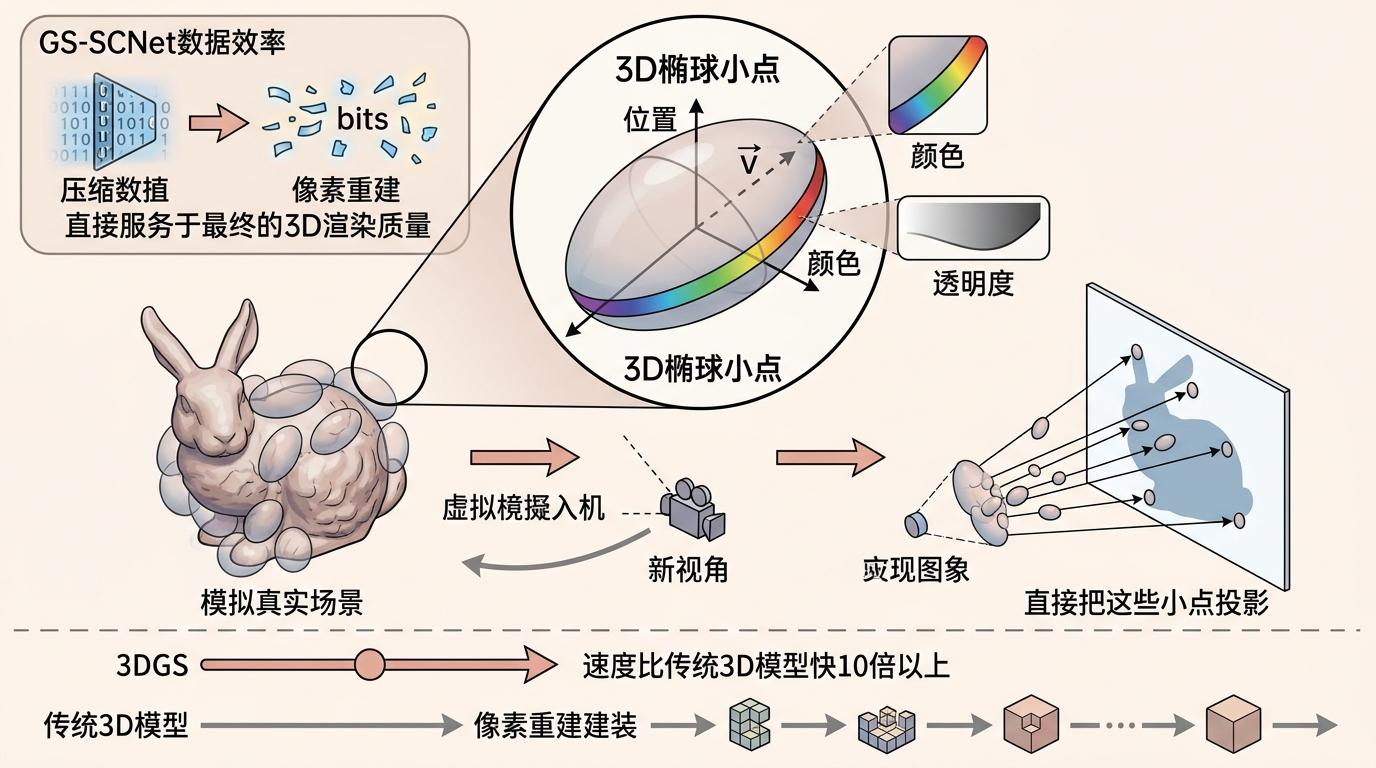
这里的关键是3D高斯泼溅(3DGS):它用无数个可调整的「3D椭球小点」来模拟真实场景,每个小点有位置、颜色、透明度等参数,渲染时直接把这些小点投影到新视角,速度比传统3D模型快10倍以上。GS-SCNet跳过了像素重建的环节,让压缩的每一个比特都直接服务于最终的3D渲染质量。
直给的技术逻辑是:
实验数据直白得惊人:在4D-DRESS、X-Humans等动态人体数据集上,它比传统MV-HEVC+GPS-Gaussian的组合,平均节省75%的码率,推理速度达到19.2 FPS,是传统方案的3倍多。
当然,GS-SCNet现在还不是「通用解决方案」。它目前只能处理已经标定好的立体视频对——也就是左右摄像头的位置、角度都提前校准过,这在户外或临时场景下很难实现。而且它需要大量标定好的立体视频数据来训练,采集和标注成本不低。
但这些局限,恰恰是它的价值所在:它证明了「把通信编码和3D重建端到端融合」这条路走得通。之前的研究要么盯着视频压缩,要么盯着3D重建,没人敢把两个领域的核心技术直接焊在一起——毕竟这意味着要推翻已经跑了几十年的成熟流程。
更重要的是,它的「率-渲染失真(RRD)」优化目标,为整个沉浸式通信领域指了个新方向:别再盯着像素了,用户要的不是「和原图一样的2D画面」,而是「能自由切换视角的真实3D体验」。
当我们谈论6G和元宇宙时,总喜欢说「身临其境」,但真正的瓶颈从来不是「画面够不够清晰」,而是「能不能用最少的资源,传递最关键的体验」。
GS-SCNet的意义,不止是砍掉了70%的带宽,更在于它打破了「先压缩再重建」的思维惯性——原来通信和渲染根本不是前后接力的两个环节,而是从一开始就该绑定的整体。
解耦的尽头,是融合。 这句话不仅适用于沉浸式通信,更适用于所有被传统流程困住的技术领域:当你发现两个环节在做重复的事,或许就是该把它们拧成一股绳的时候。