对抗知识焦虑,从看懂这条开始
App 下载
多轮对话里的AI:能搭博客也会犯糊涂
复杂任务处理|泛化能力|评论区功能|博客搭建|多轮对话|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载复杂任务处理|泛化能力|评论区功能|博客搭建|多轮对话|大语言模型|人工智能
当你让AI搭一个个人博客,它不仅写出了页面代码,还悄悄加了没被要求的标签系统——这不是程序员的贴心,是大语言模型的「泛化能力」在起作用。但紧接着,你会发现它埋的坑:评论区只能支持两层回复,外链图片在预览框里死活不显示。你得一次次补充指令,像教新手改bug一样,它才能慢慢把问题磨平。这正是当下AI在多轮交互中的真实处境:既能读懂任务的「潜台词」,又会在复杂逻辑里「掉链子」。为什么AI能主动补全功能,却搞不定多层评论?这背后藏着大语言模型处理复杂任务的核心逻辑与软肋。
你可以把大语言模型的多轮交互,想象成和一个聪明但记性时好时坏的实习生合作:你说要做博客,它不仅会搭文章列表,还能联想到标签分类——这是因为它在预训练时见过数百万个博客样本,已经把「博客该有的样子」刻进了参数里。这种「不用明说就补上功能」的能力,叫**指令泛化**,就是模型能从模糊的需求里,自动补全行业默认的规则。
但这个实习生的问题也很明显:它能记住你说过的「要评论功能」,却记不住你没说的「要支持多层回复」。这不是它故意偷懒,而是多轮交互的核心难点——上下文管理。Transformer架构的自注意力机制,就像给对话内容拍了张全景照,但照片中间的细节很容易糊掉。比如你在第5轮说的「要改评论逻辑」,到第10轮时,它可能只记得「要做评论」,忘了具体的层数要求。
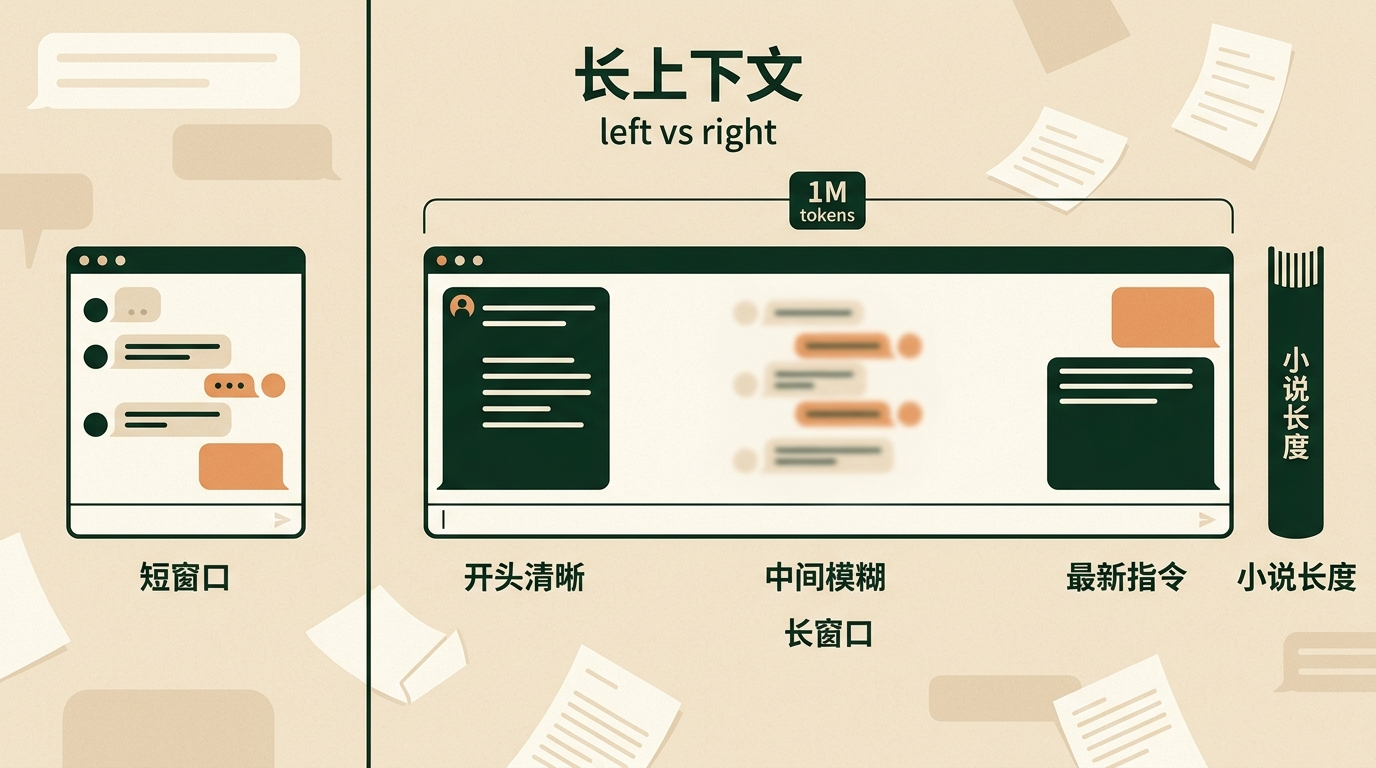
为了让它记住这些细节,工程师们给模型加了「长上下文窗口」——相当于把照片的尺寸放大,能装下更多对话历史。现在主流模型能处理百万级别的token,差不多是一本长篇小说的长度。但就算窗口再大,模型对信息的利用也是「两头清晰,中间模糊」:开头的需求和刚说的指令记得最牢,中间的细节很容易被忽略。
当任务从「搭个页面」变成「做一个能玩的卡牌游戏」,AI的工作就从「写代码」变成了「项目管理」。它得先把「卡牌游戏」拆解成角色、技能、对战规则这些子任务,再一步步实现每个部分——这就是任务分解能力,是复杂任务生成的核心。
比如你要做一个仿照三国杀的武侠卡牌,AI会先给每个角色配技能,再设计「问拳」「避让」这些机制。但它可能一开始会写错规则:比如允许在非弃牌阶段出「避让」。这时候你得补充指令,它才能修正逻辑。这个过程像极了和产品经理改需求:你说「要改规则」,它得重新调整数据结构,甚至推翻之前的代码。
为什么AI能拆任务,却容易拆错?因为它的任务分解靠的是「模仿」,不是「理解」。它见过很多卡牌游戏的代码,知道通常要分角色、技能、规则,但它不知道你要的武侠卡牌里,「避让」只能在特定阶段用。要让它做对,你得像教孩子下棋一样,一步步把规则说清楚——这就是**链式思维提示**,让AI把推理过程写出来,比如「因为问拳是攻击技能,所以只能在出牌阶段使用」,这样它就不容易搞错逻辑。
不过,就算拆对了任务,AI也可能在执行时「掉链子」。比如之前有模型在做吃豆人游戏时,会让角色穿墙——这不是它不知道不能穿墙,而是在生成代码时,漏写了碰撞检测的逻辑。你得指出来,它才能补上。
AI能处理复杂任务,但背后的成本高得惊人。Transformer架构的自注意力机制,计算复杂度是O(n²)——也就是说,当对话长度从1000token变成10000token,计算量会变成原来的100倍。训练一个大模型要花数百万美元,就算是推理一次复杂任务,也得消耗好几块GPU的算力。
为了降低成本,工程师们想出了各种办法:比如用LoRA技术只微调模型的少量参数,或者用剪枝、量化把模型「压缩」。就像把一本厚书缩成小册子,虽然少了一些细节,但核心内容还在。这些技术能把推理成本降低70%以上,让普通企业也能用得起AI。

但成本之外,还有更隐蔽的陷阱:多轮安全攻击。你可能听说过「越狱攻击」——通过特殊提示让AI生成有害内容。在多轮对话里,这种攻击更隐蔽:攻击者会一步步引导AI,先问「怎么制作烟花」,再问「怎么把烟花改成爆炸物」,慢慢绕过安全限制。这就像和骗子聊天,聊着聊着就被骗了。
为了防御这种攻击,工程师们给AI加了「多轮安全对齐」:让模型记住每一轮对话的意图,一旦发现对话走向危险,就直接拒绝。但这又带来新的问题:有时候AI会「过度敏感」,把正常的技术提问当成攻击,比如你问「怎么优化代码性能」,它可能会以为你要做恶意软件。
当我们为AI能搭博客、做游戏而兴奋时,别忘了它本质上还是一个「擅长模仿的学生」——它能记住见过的所有规则,却不一定理解规则背后的逻辑。它能在多轮对话里不断修正错误,却可能在某个细节上突然「失忆」。
这正是AI当下的真实模样:不是无所不能的神,而是一个需要不断指导的助手。它的进步,不在于能完成多少复杂任务,而在于能在多轮交互中,越来越像一个「懂你」的合作者——不用你把每句话说透,就能get到你的潜台词,还能在犯错时快速纠正。
智能的本质,是在试错中逼近真相。