对抗知识焦虑,从看懂这条开始
App 下载
低剂量CT去噪新解法:快且细的智能平衡术
医学影像降噪|潜在扩散模型|诺丁汉大学宁波校区|TAFG-MAN模型|低剂量CT|大语言模型|临床诊疗技术|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载医学影像降噪|潜在扩散模型|诺丁汉大学宁波校区|TAFG-MAN模型|低剂量CT|大语言模型|临床诊疗技术|医学健康|人工智能
当医生告诉你“用低剂量CT,辐射小一半”时,你大概率会欣然同意——直到拿到满是“雪花点”的片子。那些模糊的血管边缘、淡去的结节轮廓,可能让医生的诊断多了几分犹豫。这就是低剂量CT的死局:要安全就得降辐射,降辐射就丢细节。
诺丁汉大学宁波校区的团队刚拿出的TAFG-MAN模型,却在不增加计算时间的前提下,把细节捡了回来。它没靠堆算力,而是给AI装了个“智能开关”——这个开关到底是怎么让降噪和保细节握手言和的?
要理解TAFG-MAN的巧思,得先搞懂它的底层框架——潜在扩散模型。你可以把它想象成一套“高清视频压缩+智能修复”系统:
首先用一个“感知优化自编码器”把512×512的CT图压缩成32×32×16的“潜码”,就像把10G的电影压成1G的MP4,体积小了16倍,但器官轮廓、血管走向这些核心信息一点没丢。这个压缩器不只是算像素相似度,它还会用VGG网络模拟人类视觉,确保压缩后的“潜码”能还原出医生看得懂的细节。
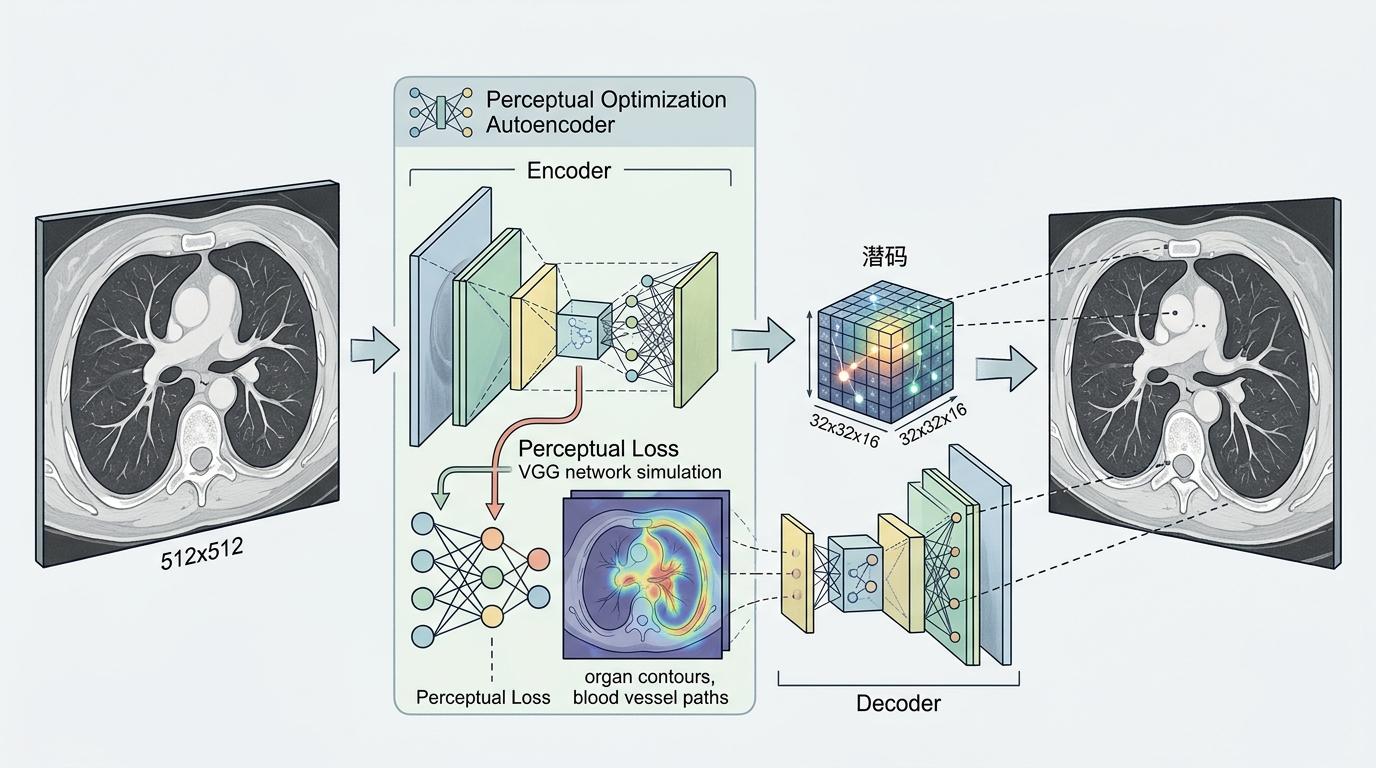
接下来的去噪就不在高清像素里折腾了,而是在这个迷你潜码空间里一步步“从噪声里捞干净图像”。再配合DDIM确定性采样,把原本要几百步的去噪过程压缩到30步,一张图的推理时间直接从几十分钟砍到18秒——终于快到能在临床上用了。
但问题还没解决:潜扩散能保住大结构,那些决定诊断的细微纹理,比如肿瘤的毛刺、血管的分叉,还是容易被当成噪声抹掉。这时候就轮到TAFG模块登场了。
TAFG的全称是“时间步自适应频率门控”,说白了就是让AI在不同去噪阶段“选择性失明”:
第一步,它先把输入的噪声CT图拆成两半:低频部分是稳定的器官轮廓、骨骼结构,这些是去噪的“骨架”;高频部分是混合了噪声的细节纹理,比如血管边缘、结节毛刺,这是要“小心提取”的精华。
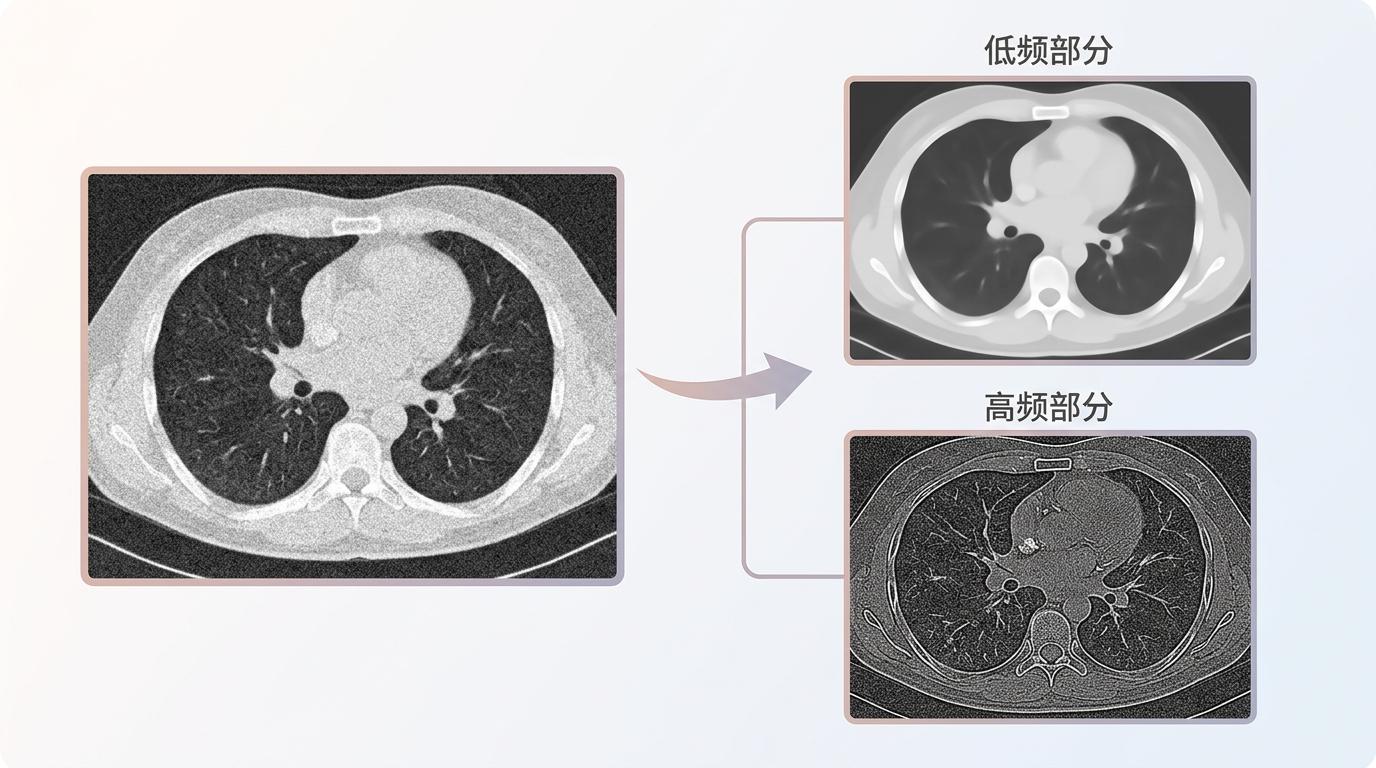
第二步,AI会根据当前的去噪进度,自动调整这两部分信息的使用强度:在去噪早期,图像还糊成一团,它会死死抓住低频信息,坚决屏蔽高频里的噪声;随着去噪推进,图像越来越清晰,它再慢慢调高高频信息的权重,把丢失的细节一点点补回来。
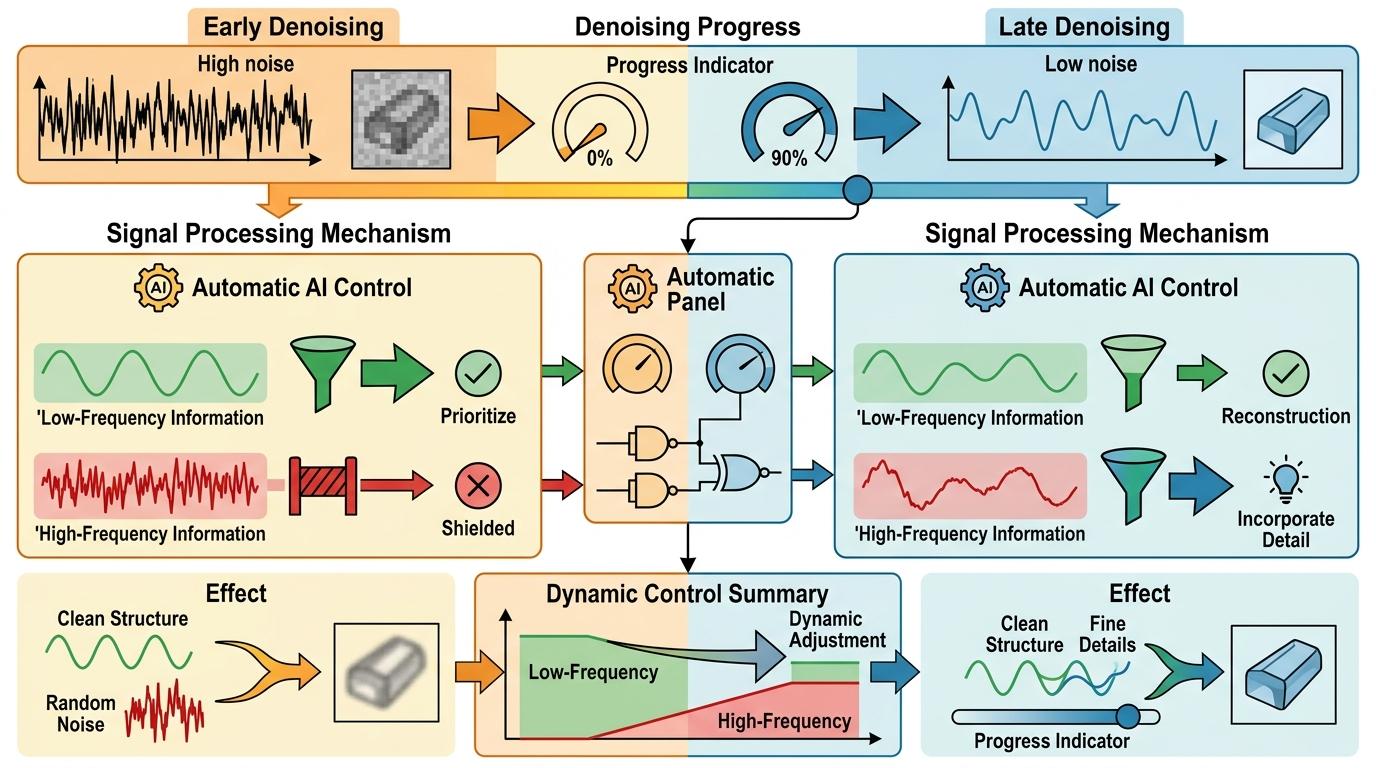
最妙的是那个“时间步释放因子”——就像给高频信息装了个定时阀门:去噪前30%的阶段,阀门只开10%;到了最后30%的精修阶段,阀门全开,让AI专注于找回那些能决定诊断的细微纹理。
这个模块轻得像个外挂,不改动任何主干网络,却让模型的细节保留能力跳了一个台阶:LPIPS感知指标从0.118降到0.100,意味着医生能看到更锐利的边缘、更清晰的纹理,而推理时间还是18秒——等于白捡了一份性能提升。
TAFG-MAN的实验数据很漂亮,但要真正走进医院,还有几道坎要跨:
首先是“数据偏见”。目前它只在腹部和胸部CT上测试过,换个脑部CT、骨关节CT,或者换个品牌的扫描仪,它还能保持同样的性能吗?真实临床的噪声比实验室里的高斯噪声复杂多了,散斑、条纹伪影这些“野生噪声”,它还能准确分辨吗?
其次是“临床验证”。现在的评估都是靠PSNR、SSIM这些冰冷的数字,真正的金标准是放射科医生的眼睛:那些AI找回来的细节,真的能帮医生更快发现肿瘤、更少漏诊结节吗?没有盲态读片的验证,再漂亮的指标都是纸上谈兵。
最后是“实时性”。18秒一张图看起来快,但在急诊、批量筛查的场景里,还是不够。要做到“扫完就能看”,还得把推理时间压缩到秒级以内——这需要更极致的模型压缩和硬件优化。
从BM3D的“一刀切”滤波,到RED-CNN的“过度平滑”,再到扩散模型的“慢工出细活”,低剂量CT去噪的研究一直在“效率”和“质量”之间走钢丝。TAFG-MAN没走堆算力的捷径,而是靠一个精巧的“智能开关”,找到了两者的平衡点。
更值得关注的是,它的思路不止能用在CT去噪上——这种“分阶段、按需求”的信息调控,或许能给所有需要“平衡精度与效率”的AI任务提个醒:有时候,比堆参数更重要的,是让AI学会“什么时候该看什么”。
好的医疗AI,从来不是追求“完美的图像”,而是追求“能帮医生做出准确诊断的图像”。TAFG-MAN已经摸到了这道门的门把手,剩下的路,得和医生一起走。