对抗知识焦虑,从看懂这条开始
App 下载
烟雾里重建3D场景,靠的不是魔法是组合拳
图像处理流水线|ConvIR-UDPNet|NTIRE 3D重建挑战赛|杭州电子科技大学|烟雾3D重建|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像处理流水线|ConvIR-UDPNet|NTIRE 3D重建挑战赛|杭州电子科技大学|烟雾3D重建|多模态视觉|人工智能
想象火灾现场的浓烟:能见度不足三米,手机拍的照片全是糊成一团的灰影。但如果有人告诉你,用这堆模糊照片能重建出清晰到看清桌面纹理的3D场景——而且精度比传统方法提升了近90%,你会不会觉得这是特效?2026年NTIRE 3D重建挑战赛上,杭州电子科技大学的团队就做到了。他们没搞出什么颠覆式的新模型,只是把五种成熟技术像搭积木一样拼在了一起,就解决了困扰行业多年的烟雾3D重建难题。
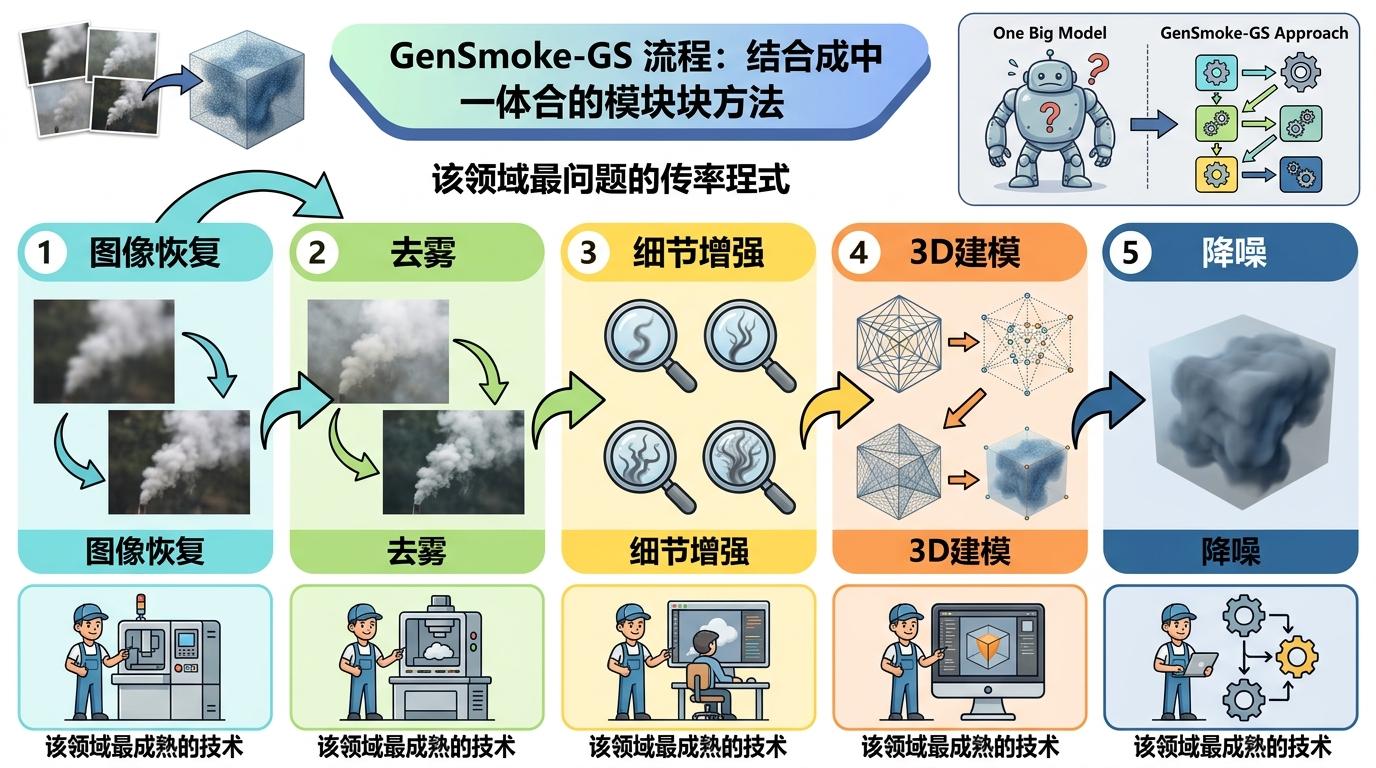
你可以把整个过程看成一条精密的食品加工线:先把沾了灰的原料洗干净,再去掉杂质,接着精细加工,最后反复质检确保品质。
第一步是「初步清洁」:用ConvIR-UDPNet卷积网络把烟雾图里最基础的结构和颜色捞出来——就像把埋在灰里的家具轮廓先擦出来。这一步不追求完美,只要求给后续步骤打下不跑偏的基础。
第二步是「深度去雾」:用经典的暗通道先验算法DCP剥离烟雾层。这个算法的逻辑很简单:无雾的图像里总有一些像素接近纯黑,抓住这个规律就能精准算出烟雾的浓度,像撕保鲜膜一样把它揭掉。
最关键的第三步来了:用GPT-Image-1.5这个多模态大模型补细节。但这里的核心不是让模型「自由发挥」,而是给它上了紧箍咒——提示词严格要求「只补细节,不许改结构」。比如两张不同角度的椅子照片,模型绝不能把第一张的镂空椅背改成第二张的实心条纹,这是3D重建的生死线。
接下来是「3D建模」:用3D高斯泼溅技术把2D照片转成3D场景。你可以把它想象成用几百万个半透明的彩色泡泡填满空间,每个泡泡的位置、大小、颜色都精准对应现实物体的细节,渲染速度比传统NeRF快了几十倍。
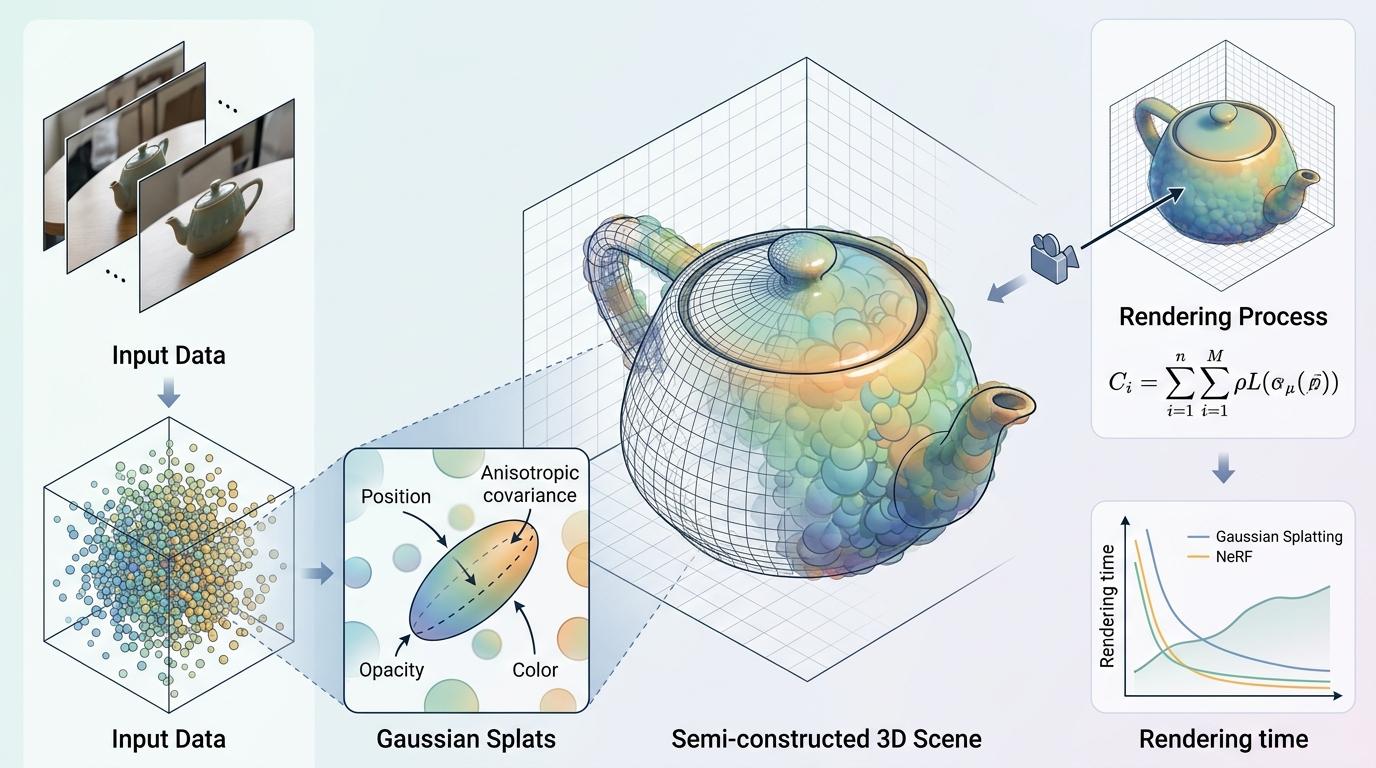
最后一步最「笨」也最有效:连续渲染91次,把结果平均。因为算法优化里总有随机噪声,就像手抖拍出来的照片,多拍几次取平均,模糊和伪影自然就消失了。
为什么不能直接用AI把烟雾图变清晰再重建?这是所有人都会犯的直觉错误。
普通的图像增强模型只看单张图的好看程度,根本不管「同一物体在不同角度得长得一样」。比如它可能给第一张椅子补了雕花,给第二张补了条纹——单看每张都清晰,但3D重建算法拿到这两张图,只会彻底混乱:这到底是一把椅子还是两把?
这就是生成模型的「幻觉问题」:它太擅长「脑补」,但补出来的细节往往不符合现实逻辑。在3D重建里,这种「脑补」是致命的——3D算法的核心就是靠不同视角的相同特征点计算空间位置,一旦特征点对不上,重建出来的模型要么扭曲变形,要么直接散架。
GenSmoke-GS的聪明之处,就在于用提示词工程把模型的「想象力」关在了笼子里。他们给模型的指令不是「把图变清晰」,而是「在保持物体形状、位置、边界完全不变的前提下,去除烟雾,恢复细节」。相当于给模型画了个框:你只能在框里干活,不许出圈。
数据不会骗人:在测试集上,这个方法的PSNR(图像精度指标)从传统3DGS的11.54跃升到20.21——提升幅度接近9dB,在图像领域这相当于从模糊的马赛克变成了高清照片。
这个方案最值得琢磨的,不是它用了什么黑科技,而是它的工程思维。
现在的AI圈总在追求「大一统模型」,仿佛一个模型解决所有问题才叫厉害。但GenSmoke-GS反其道而行之:它把烟雾3D重建拆成了「图像恢复-去雾-细节增强-3D建模-降噪」五个独立问题,每个问题都用该领域最成熟的技术解决——没有重新训练任何大模型,只是把现有模块用正确的逻辑串了起来。
这种思路在工业界其实很常见,但在学术圈却显得格外务实。就像造车不需要自己发明轮胎、发动机和方向盘,只要把最好的零件组装起来,再解决好零件之间的匹配问题就行。
当然,它也不是完美的。在极端烟雾场景下,比如整个画面都被浓烟覆盖,这个方法的效果还是会打折扣;而且91次渲染的时间成本很高,暂时没法实现实时重建。但它提供了一种更接地气的思路:面对复杂问题,与其死磕一个完美的解决方案,不如用模块化的方式逐个击破。
当我们为AI的「创造力」欢呼时,GenSmoke-GS的成功像个冷静的提醒:很多时候,解决复杂问题的关键不是发明新工具,而是学会正确使用现有工具。
这个方案没有什么让人拍案叫绝的创新,却用最朴素的工程思维,解决了一个实实在在的难题——从火灾现场的应急救援,到工业厂房的设备检测,再到考古现场的遗迹重建,这种能在烟雾里看清3D世界的技术,每多精进一分,就能多解决一些现实中的麻烦。
复杂问题的最优解,往往是简单模块的精准组合。