对抗知识焦虑,从看懂这条开始
App 下载
给AI图像生成装个独立大脑,解决逻辑翻车
ACL 2026|逻辑推理|图像生成模型|浙江大学|Unified Thinker|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载ACL 2026|逻辑推理|图像生成模型|浙江大学|Unified Thinker|多模态视觉|人工智能
让AI画一张“燃烧6小时后的蜡烛”,闭源模型能精准呈现蜡泪堆积、灯芯烧短的状态,开源模型却常给出一根刚点燃的新蜡烛——它能理解“燃烧”,却搞不懂“6小时”意味着什么。这不是生成画质的差距,而是AI缺了个能把逻辑落地的“大脑”。2026年5月,浙江大学联合团队提出的Unified Thinker,把AI的“思考”和“画画”彻底分开,让图像生成从靠概率猜像素,变成靠逻辑做规划。这项研究刚被ACL 2026接收为Oral报告,它要解决的,正是开源AI和闭源AI之间那道看不见的推理鸿沟。
你可以把传统图像生成模型想象成一个闭着眼睛画画的人——它见过太多画,能凭记忆复刻出相似的像素组合,但不知道自己画的是什么,更别说理解“先有因再有果”“位置不能乱”这类逻辑。Unified Thinker做的第一件事,就是把这个“闭眼画家”拆成两个角色:
一个是Thinker(思考者),也就是独立的“大脑”。它不用碰画笔,只负责把用户的模糊指令拆成三步:先拆解真实意图(比如用户要的不是“蜡烛”,是“燃烧6小时后的状态变化”),再把逻辑具体化(蜡体烧短三分之二、蜡泪沿容器凝固、灯芯变黑变短),最后转译成生成器能看懂的视觉指令(“保留容器,将蜡烛高度改为原三分之一,底部添加半凝固蜡泪”)。
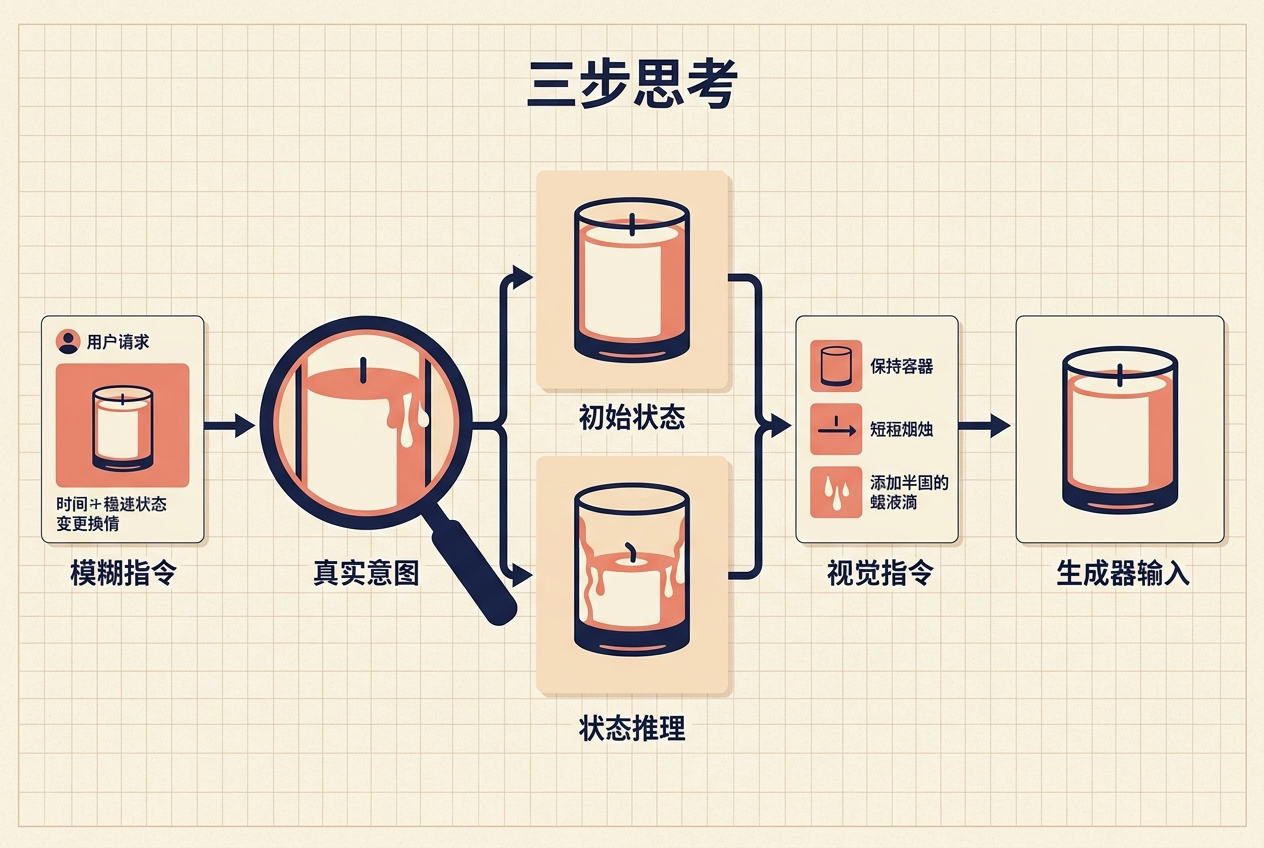
另一个是Generator(生成器),也就是专精的“手”。它不用费脑想逻辑,只需要严格按照思考者给出的结构化指令,生成高精度的像素画面。
这种彻底解耦的设计,解决了两大老问题:一是过去大一统模型里“思考和画画抢算力”的矛盾,二是外挂LLM时“说的和画的对不上”的错位。更关键的是,你可以单独给“大脑”升级逻辑能力,不用重新训练整个画画的“手”——就像给手机换个更聪明的芯片,不用连屏幕一起换。

光有分工还不够,思考者得知道怎么“想”才能帮到生成器。研究团队专门建了一个4万条样本的HieraReason-40K数据集,核心是给每个任务加了结构化推理轨迹——简单说,就是逼着AI在画画前,把思考过程写得像一份施工蓝图。
比如用户要“把数独谜题改成解完的样子”,传统模型可能直接乱填数字,而Unified Thinker的思考者会先走完三步:第一步拆解意图,明确是“完成数独游戏,保证每行每列数字不重复”;第二步做逻辑推理,逐个算出每个空格的正确数字;第三步转译成视觉指令,“将第一行第二列改为3,第三行第五列改为7……”。而且在图像编辑时,它严格遵守“只说要改的地方”的规则,绝口不提原本就正确的数字,避免生成器画蛇添足。
为了让思考和画画更默契,团队还设计了双阶段强化学习:第一阶段让思考者生成多个推理路径,用生成的图像质量反过来打分,逼它放弃“听起来合理但画不出来”的空想;第二阶段让生成器随机采样多种画法,用推理指令的契合度优化,提升它对复杂指令的执行精度。这种双向反馈,就像让大脑和手不断磨合,直到大脑说的每一句话,手都能精准做出来。
实验数据最能说明问题:在侧重推理的RISEBench测试中,Unified Thinker的逻辑准确率从基线的37%提升到60%以上;在知识密集的WiseBench里,它的表现已经接近GPT-4o这类闭源模型。更惊喜的是,把这个思考者模块直接插到没参与训练的BAGEL生成器上,居然也能让后者的推理准确率提升30%——这意味着这个“大脑”是通用的,能给不同的“手”打工。
当然,Unified Thinker还远不是万能的。它的思考质量高度依赖训练数据,遇到罕见的复杂场景,比如“把汽车改成折叠后能放进背包的样子”,还是可能出现逻辑漏洞;不同生成器对指令的理解能力有差异,同样的指令,有的生成器能画准细节,有的可能只会画个大概;而且多了一个思考阶段,确实会增加一点计算时间——就像人做事前要先想,肯定比凭直觉做慢一点,但出错的概率也低了。
但这些问题,都是前进中的问题。团队已经在计划扩充数据集,覆盖更多长尾场景;也在优化强化学习的奖励机制,让反馈更精准;甚至在想怎么把这个思考模块用到机器人、自动驾驶这些需要实时决策的领域——毕竟“先思考后行动”的逻辑,不止适用于画画。
从靠概率拟合像素,到靠逻辑规划画面,Unified Thinker的意义不止于提升AI画画的能力,更在于给AI装上了一个“可解释的大脑”。过去我们看AI生成的图像,只能说“像不像”,现在我们能知道“它为什么这么画”——因为它先想清楚了每一步逻辑。
这是AI从“模仿”到“理解”的一小步,却是视觉生成从“黑箱”到“可控”的一大步。先想清楚,再动手做,这个人类最朴素的做事逻辑,终于在AI身上落地了。未来的AI,或许不用再靠“撞大运”生成内容,而是能像人一样,有计划、有逻辑地完成每一个任务。