对抗知识焦虑,从看懂这条开始
App 下载
AI造假追不上?北邮用增量学习破解溯源困局
生成模型|增量学习|AI内容溯源|IncreFA框架|北邮团队|AI安全治理|人工智能
对抗知识焦虑,从看懂这条开始
App 下载生成模型|增量学习|AI内容溯源|IncreFA框架|北邮团队|AI安全治理|人工智能
当你刷到一张逼真到能以假乱真的风景照,或是一段模仿你语气的语音时,可能不会想到:每10秒,就有一个新的AI生成模型在全球上线。传统的水印、防伪算法刚跟上上个月的模型,下个月就彻底失效——就像用去年的疫苗防今年的流感。2026年CVPR大会上,北邮团队的一项研究,第一次让AI内容溯源拥有了「自我进化」的能力。他们是怎么让溯源技术不再被AI迭代甩在身后的?
你可以把传统AI内容溯源工具想象成一本固定的「造假特征词典」——每个生成模型对应一个词条,遇到新模型就得手动加新词,还容易把旧词忘光。北邮团队提出的IncreFA框架,把这本死词典改成了能自己学习的「智能笔记」:它不再死记硬背某个模型的特征,而是先搞懂所有生成模型的「家族树」——比如Diffusion模型和GAN模型在底层逻辑上的相似性,再用增量学习的方式,每遇到一个新模型,就把它的特征「嫁接」到对应的家族分支上,不用从头学起。
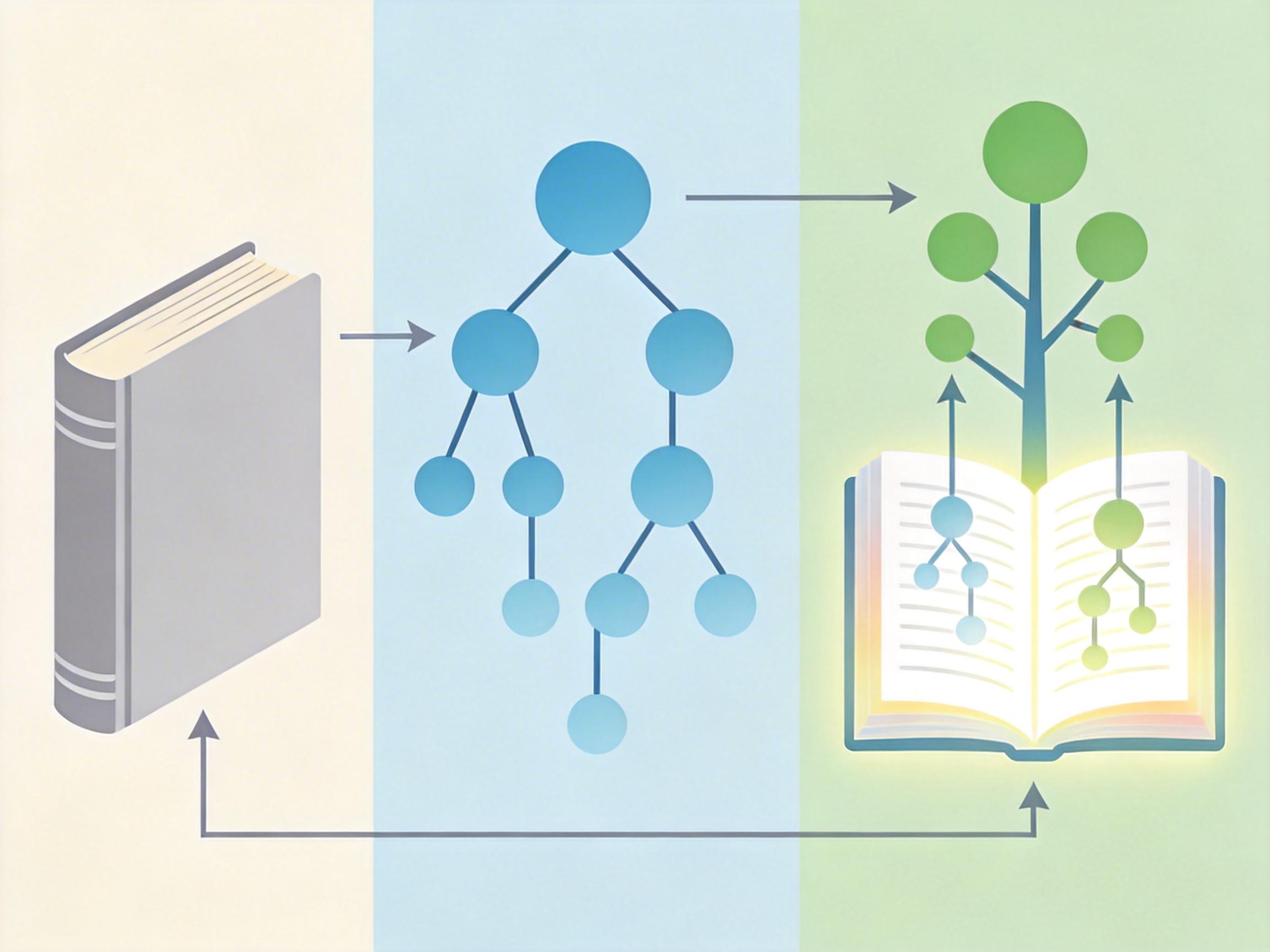
这个框架在2022到2025年的28个主流生成模型上做了测试,准确率比传统方法提升了37%。更关键的是,它不需要每次都重新训练整个模型,新模型上线后,只需要花原来1/5的时间就能完成适配——相当于给溯源系统装了个自动更新的开关。
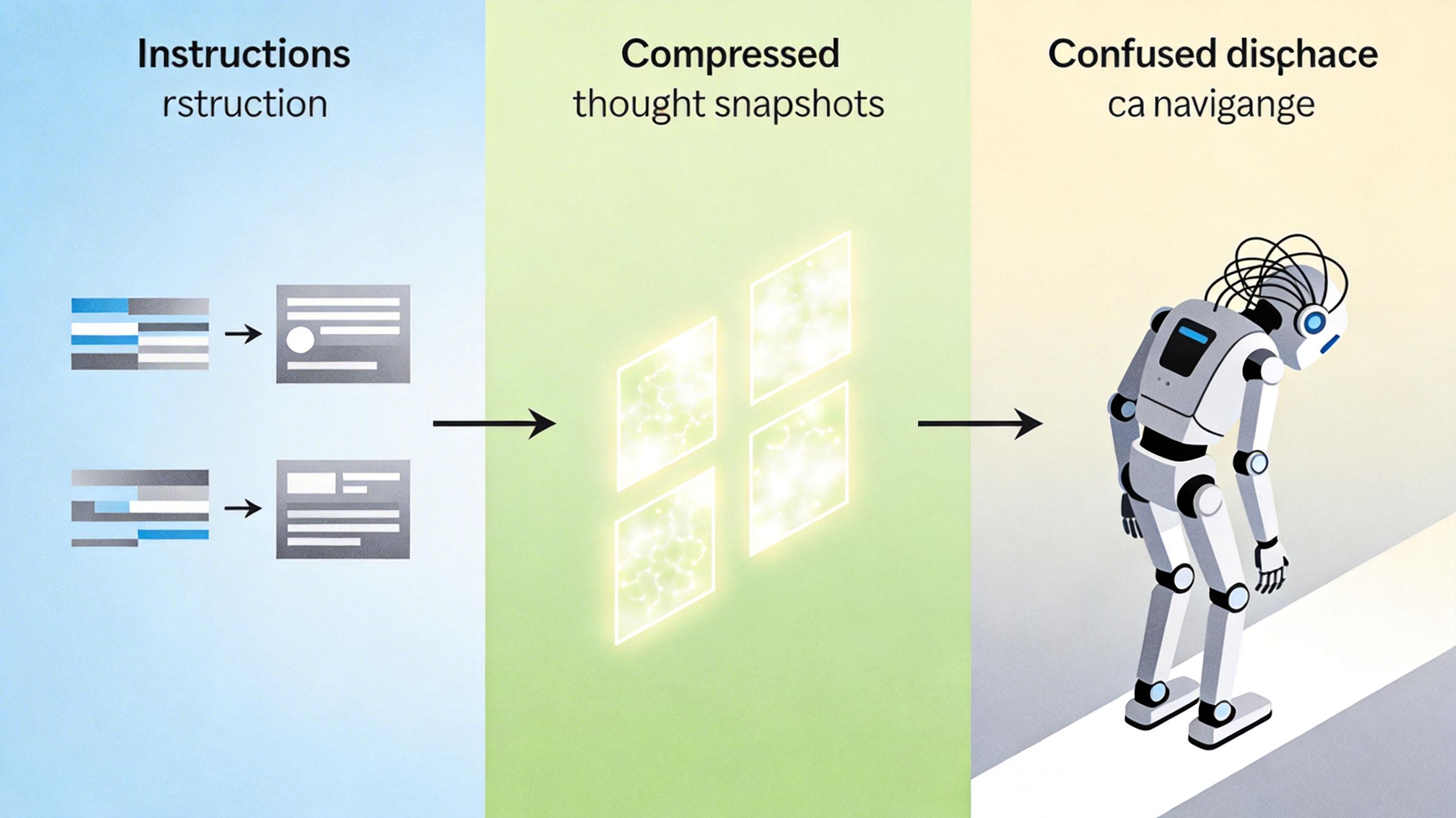
如果说溯源是给AI内容「查户口」,那多模态链式推理就是让AI学会「做侦探」。传统的视觉语言导航AI,比如让机器人根据指令找东西,要么只会看不会想,要么只会用文字推理找不到位置。北邮的FantasyVLN框架,第一次把文本、视觉和空间推理拧成了一股绳。
它的逻辑像极了人找东西的过程:先把指令拆成「先找桌子→再找桌子上的书」这样的步骤,然后在脑子里「想象」书可能在的位置,最后再用眼睛验证。为了不让脑子里的「想象」太占内存,团队用VAR模型把这些视觉想象压缩成了紧凑的「思维快照」,推理速度一下子提升了10倍。在导航测试中,它的成功率比传统方法高了24%——相当于让机器人从只会看地图的路痴,变成了能听懂方言的本地向导。
这种「边想边看边做」的能力,不止能用在导航上。北邮另一款KFRA智能体,能把网上查到的鸟类知识,对应到照片里鸟的羽毛形状、喙的长度上,推理准确率比普通多模态模型提升了19%——就像让AI不仅能认出「这是只鸟」,还能说出「这是只吃虫子的啄木鸟」,并且指出判断依据。
技术跑在前面,规则和认知还在追。北邮团队构建的AVFakeBench基准测试,测了11款主流音视频大模型,发现它们在判断「内容是不是假的」这件事上表现不错,但要说出「哪里假了、怎么假的」,准确率直接掉了一半——就像医生能看出你生病,却找不到病灶。

更现实的问题是跨平台溯源:一张带C2PA凭证的照片,在A平台能查到来源,转到B平台可能就丢了元数据;用户看到「已认证」的标识,常误以为内容100%真实,不知道凭证只证明「谁做的」,不证明「内容本身是真的」。还有隐私的边界:要追踪AI内容的生成轨迹,难免会涉及训练数据的版权,怎么在不侵犯隐私的前提下实现溯源,至今没有完美答案。
当AI能生成以假乱真的内容,我们最需要的不是更强大的生成工具,而是能和AI「同步进化」的鉴别能力。北邮团队的研究,本质上是在给狂奔的AI踩下「可信的刹车」——不是要阻止AI前进,而是要让它的每一步都有迹可循。
技术的可信,才是AI的未来。 未来的数字世界里,我们或许不会再纠结「这是不是AI做的」,而是能坦然地问一句:「这是谁做的?怎么做的?」就像我们现在拿起一本书,会先看扉页上的作者名字一样。