
10 天前
10 天前
想象你要找一本散落在图书馆深处的书:传统AI会让管理员把所有相关书架的书全搬来,堆成小山让你翻;而现在,清华和纽约大学的团队让AI学会了自己走进图书馆——先看索引找大致区域,再查书脊找关联书目,甚至会根据作者线索挖到冷门藏本。2026年4月发布的AgentGL,第一次让大语言模型像人一样在知识图谱里“逛”,用强化学习练出了一套精准找答案的本事,在7个主流数据集上把节点分类准确率最高提了17.5%,链接预测性能暴涨28.4%。为什么“逛图谱”比“堆书”厉害这么多?
过去大模型处理图谱数据,本质是“静态投喂”:不管问题复杂与否,先把目标节点的所有邻居、邻居的邻居一股脑塞进模型,结果要么信息太多干扰判断,要么关键线索被淹没在噪声里。就像给你一堆零件让你拼汽车,你根本不知道先看发动机还是轮胎。
AgentGL的核心突破,是把大模型变成了一个带“导航系统”的智能体。它给大模型配了四把“搜索钥匙”:1跳邻居搜索是“看眼前”,直接找目标节点的直接关联;2跳邻居搜索是“问朋友的朋友”,扩大局部视野;结构显著性搜索是“找权威”,定位图谱里的核心枢纽节点;语义密集搜索是“找同类”,挖那些没直接关联但语义相近的节点。
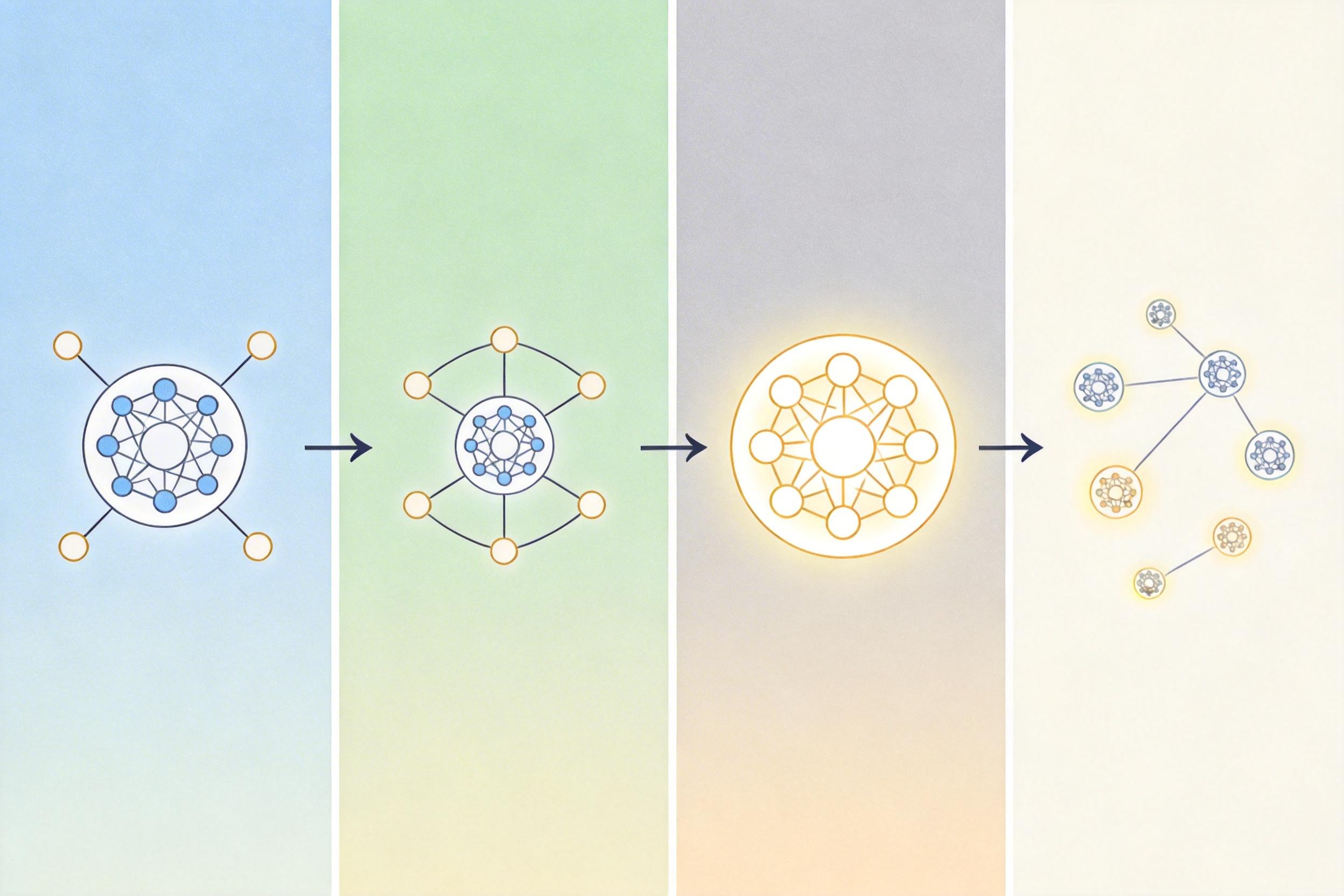
这个智能体严格遵循“思考-行动-观察”的循环:先根据问题想该用哪把钥匙,再去图谱里找对应信息,最后根据新发现调整下一步策略。比如要判断两个学术论文是否有潜在引用关系,它会先查共同引用的核心文献(1跳搜索),再看领域内的权威综述(结构显著性搜索),如果还拿不准,就去挖研究方向相似但没直接关联的论文(语义密集搜索)——完全是科研人员找文献的思路。
强化学习训练智能体最头疼的是“开局就崩”——如果一开始就让AI处理最复杂的图谱问题,它会像刚学走路的孩子摔得满地找牙,根本学不会有效策略。AgentGL解决这个问题的关键,是一套叫“图条件课程学习(GCCL)”的机制:它会自动给图谱里的任务分难度,让AI从简单题开始练,循序渐进挑战难题。 怎么定义难度?比如节点分类任务,一个节点如果邻居大多和它同类、自身连接又多,就像一个住在全是医生的小区里的医生,一眼就能判断类别,属于“简单题”;如果它是个跨界研究者,邻居一半是工程师一半是艺术家,就属于“难题”。链接预测任务里,两个语义相似度高的节点有连接,就像两个喜欢科幻的人成了朋友,很容易判断;如果两个风马牛不相及的节点有连接,就像一个农民和一个宇航员成了朋友,判断起来就难。 这套自动分阶的课程,让AI的训练稳定性大幅提升。实验显示,用GCCL训练的模型,不仅收敛速度快了30%,在零样本迁移任务上的表现也暴涨——只在两个数据集上训练,换到完全陌生的图谱,节点分类准确率平均提升24.4%,相当于学完小学数学就能做初中题。
AgentGL的性能提升让人兴奋,但有个容易被忽略的细节:它的推理成本比传统静态方法高得多。因为每一步搜索都要调用大模型,一次复杂推理可能要反复调用十几次,计算量是静态方法的数倍,延迟也相应增加——这意味着它目前只适合对速度要求不高的场景,比如学术研究、金融风控,还没法直接用到实时推荐、智能客服这类对延迟敏感的业务里。 更值得关注的是,这套“主动导航”的策略依赖强化学习的奖励设计,而奖励函数的细微偏差可能让AI走偏。比如如果奖励只看最终答案是否正确,AI可能会学会“投机取巧”:直接跳到最可能的答案节点,而忽略中间的推理过程,虽然能答对,但失去了可解释性——就像学生直接抄了答案,你不知道他到底懂没懂。 研究者也意识到了这些问题,在第二阶段训练里加入了“搜索约束思考”:每次搜索后强制让AI停下来整理思路,避免盲目跳转。但这本质是一种“人工干预”,未来能不能让AI自己学会平衡效率和严谨性,还是个待解的难题。
AgentGL的出现,其实是AI从“记忆型”向“推理型”进化的一个缩影。过去我们总说大模型“没有真正的智能”,因为它只会在训练数据里找相似的例子;而现在,它开始像人一样“找线索、理逻辑、做决策”——这种主动探索的能力,才是通用人工智能的雏形。 当然,这条路还很长:它现在还只会在静态图谱里逛,未来要学会处理随时间变化的动态图谱;它现在还只会处理文本节点,未来要学会看懂图片、音频这些多模态数据。但不管怎样,当AI不再是被动接受信息的容器,而是主动探索世界的智能体,我们离“能思考的机器”就又近了一步。 真正的智能,从来不是记住所有答案,而是知道怎么找答案。
点击充电,成为大圆镜下一个视频选题!