
2 天前
2 天前
你可能没意识到,现在给AI看病的「教材」里,混着不少「错题」——CT片上的设备噪声、MRI里模糊的病灶边界、不同医生标注的分歧……这些医学图像自带的「随机不确定性」,就像藏在题库里的错题,会把AI的诊断思路带偏。西安电子科技大学的团队没去给AI换更复杂的「大脑」,反而先给「教材」做了一遍「体检」:用见过千万级医学图像的基础模型当「考官」,给每一张图的「靠谱程度」打分。结果让人大吃一惊——就靠筛选掉最不靠谱的5%数据,主流分割模型的准确率平均提升了0.6%以上,疑难病灶的边界识别精度直接肉眼可见变准。这背后的逻辑,其实是给AI看病的思路来了个大转弯。
传统的AI训练,就像让学生闷头刷完所有题库——不管题对不对,先全做一遍。但医学图像里的「随机不确定性」是天生的:比如肺部CT上的血管和早期肿瘤阴影重叠,不同医生都可能标错,这种「错题」AI学了只会越学越偏。
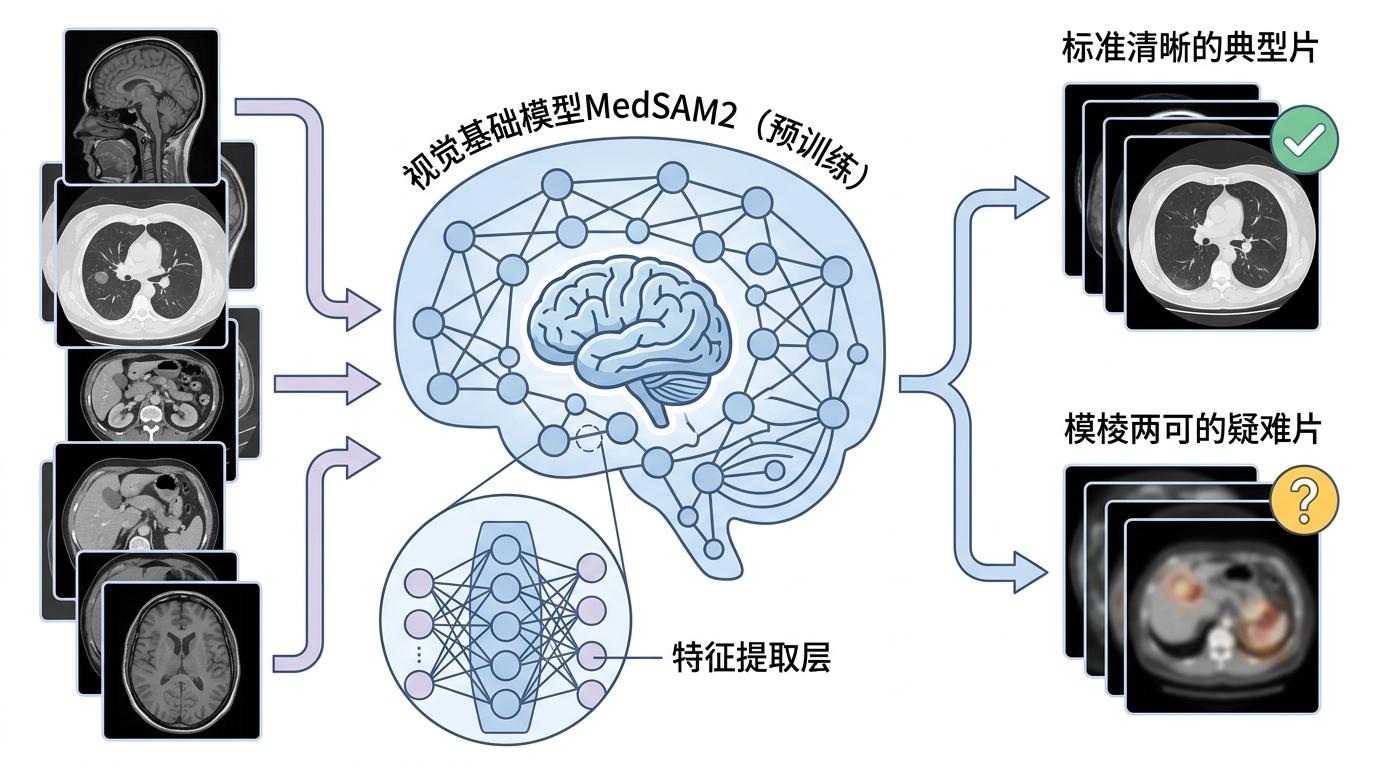
西电团队的办法是,请个「见多识广的老专家」来先审一遍题:用MedSAM2这类在百万级医学图像上预训练过的视觉基础模型,给每一张输入图像提取特征。你可以把这个过程理解成,让资深放射科医生快速扫一遍所有片子,标记出哪些是「模棱两可的疑难片」,哪些是「标准清晰的典型片」。
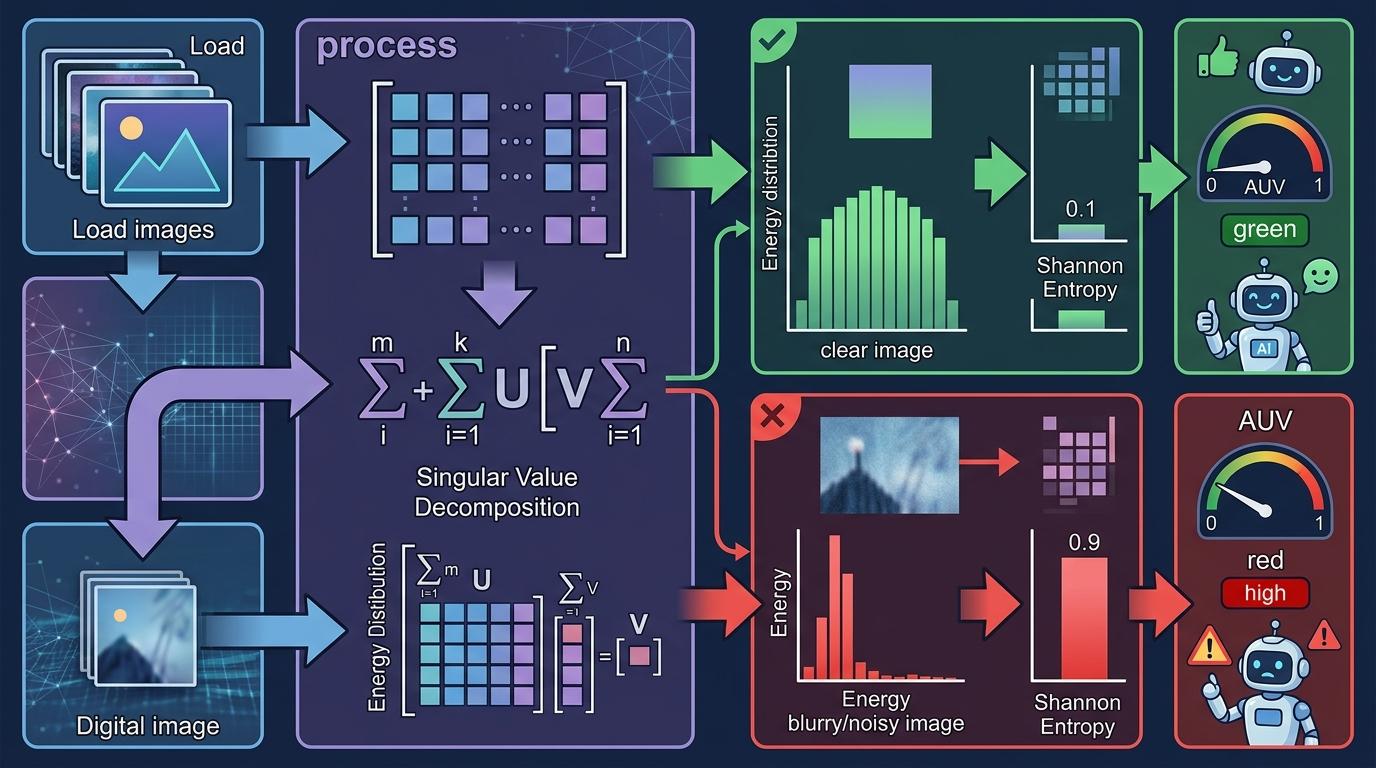
关键的打分机制藏在数学里:对基础模型提取的特征矩阵做奇异值分解,就像把一张图的「特征能量」拆成不同频段的信号——清晰的片子能量分布均匀,模糊或噪声大的片子能量会集中在少数几个频段。再用香农熵计算这种分布的复杂度,最后归一化得到0到1之间的AUV值:AUV越接近1,这张图的不确定性越高,越容易把AI带偏。
有了AUV这个「靠谱度分数」,团队设计了两个不用改AI模型就能提分的「外挂」。
第一个是「数据过滤」:直接删掉AUV最高的5%到10%样本。就像让学生先跳过最离谱的错题,先把基础题练扎实。实验显示,在肝脏肿瘤、肾脏肿瘤等五个数据集上,用这个方法训练的nnU-Net模型,平均Dice分数从75.10%提升到75.73%,收敛速度还快了不少。
第二个是更精细的「动态不确定性感知优化」(DUO):不删题,而是在训练时给难题加权重。AI每做一遍题,就根据当前的预测情况调整损失函数——对那些AUV高、AI容易错的样本,训练时多花精力;对那些标注清晰、AI一看就会的样本,少花时间。同时还加了个「标签去噪」模块,自动修正标注里的明显错误,就像给题库里的错题悄悄改对。
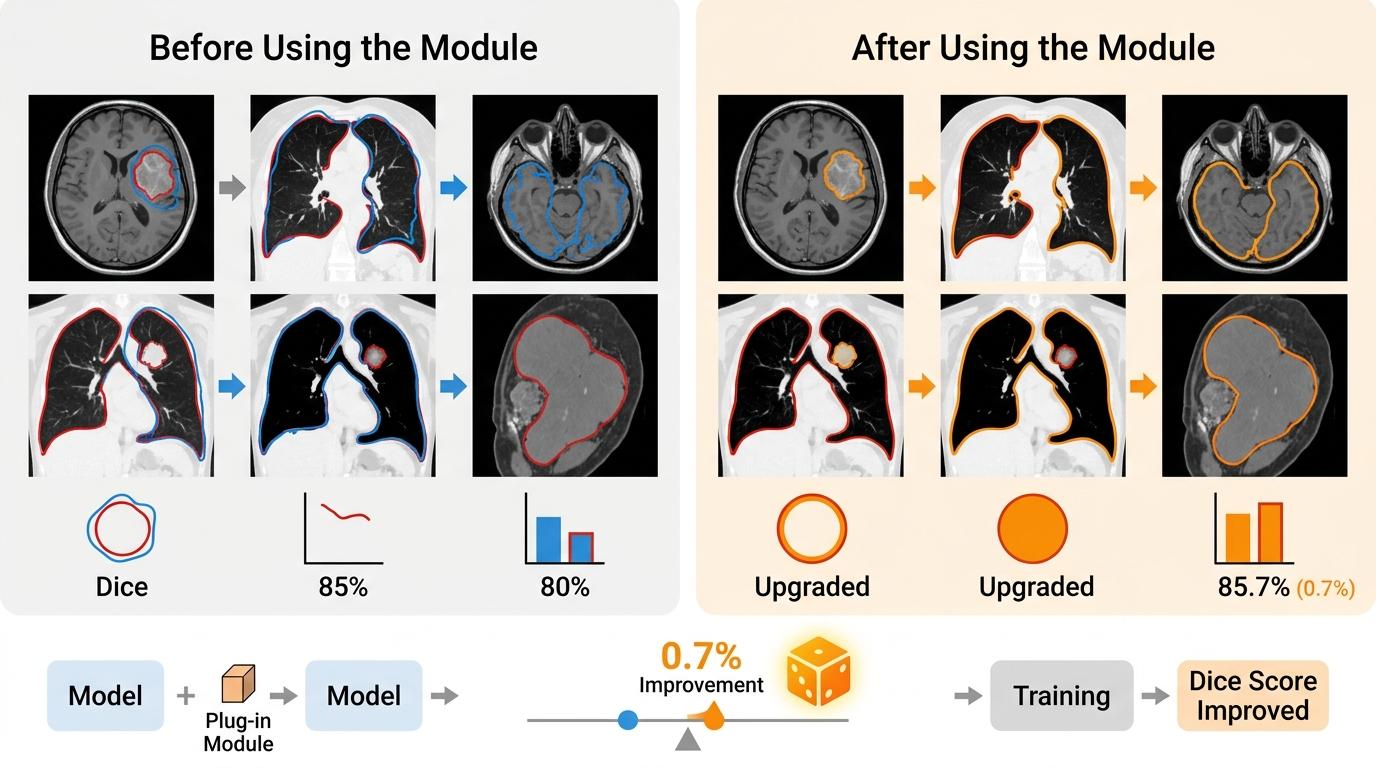
最关键的是,这两个策略都是「即插即用」的——不用动主流分割模型的核心结构,只要在训练前或训练中加个模块就行。在nnU-Net、SwinUNet、VMamba三种不同架构的模型上,DUO都能稳定提升0.6%到0.7%的Dice分数,在病灶边界的分割上,橙色的AI预测线比原来的蓝色线更贴近红色的真实边界。
当然,这个方法也有它的边界。比如它的效果高度依赖基础模型的能力——如果基础模型没见过某种罕见病的影像,就没法准确给这类片子打分。而且AUV的阈值需要根据不同数据集微调,没法一套参数用到底。
但它真正的价值,是把AI训练的重心从「改模型」拉回了「看数据」。过去十年,医学AI的研究大多在拼模型复杂度:从UNet到SwinUNet再到VMamba,模型越做越深,参数越堆越多。但西电的研究证明,当你把训练数据里的「噪音」筛掉,给AI喂更干净的「饲料」,哪怕用最经典的nnU-Net,也能得到更好的结果。
这就像给厨师换最好的食材,哪怕用普通的锅,也能做出更可口的菜。在数据质量参差不齐的医疗领域,这个思路的改变,可能比模型本身的突破更有现实意义。
当我们在谈论医疗AI的「精准」时,往往把目光投向模型的算法复杂度,却忽略了最基础的「数据质量」。西电团队的研究,就像给喧闹的AI研究场浇了一盆冷水:先把数据的「病」治好,AI才能真正学会看病。
未来的医疗AI,可能不是靠最复杂的模型取胜,而是靠最会「挑数据」的训练机制——给每一张图做体检,给每一个样本算权重,让AI在学习时也能「因材施教」。毕竟,再聪明的学生,也需要一套靠谱的教材。
给数据体检,是AI精准看病的第一步。
点击充电,成为大圆镜下一个视频选题!