对抗知识焦虑,从看懂这条开始
App 下载
AI数据分析Agent:实验室光鲜,落地现原形
数据分析报告|金融智库任务|Claude Opus 4.6|南方周末科创力研究中心|中山大学陈川课题组|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数据分析报告|金融智库任务|Claude Opus 4.6|南方周末科创力研究中心|中山大学陈川课题组|AI智能体|人工智能
当你在视频里看到AI Agent输入一句指令,几分钟就生成一份新能源汽车产业分析报告时,可能会觉得分析师的饭碗要保不住了。但中山大学陈川课题组联合南方周末科创力研究中心的测试,给这份乐观浇了盆冷水:他们用492个真实金融智库任务测试8款主流大模型Agent,结果最强的Claude Opus 4.6准确率也只有63.4%,其余均低于50%。更关键的是,这些AI在真实开放式数据环境里,连第一步「找到需要的数据」都频频出错。为什么实验室里的优等生,一到真实职场就掉链子?
你可以把实验室里的AI数据分析demo,想象成厨师在备料齐全的厨房里做菜——食材洗好切好、调料摆得整整齐齐,只要按步骤翻炒就能出菜。但真实职场里的数据分析,更像让厨师去一个陌生的菜市场:你不知道摊位在哪、食材新鲜度如何、秤准不准,甚至连要做的菜需要哪些原料都得自己摸索。

这种「在未知里找线索」的过程,就是DataClawBench提出的「探索负担」。真实的企业数据库里,表格字段口径不统一、企业名称写法混乱、单位错位是常态,没有任何预设的「正确数据源清单」给AI参考。过去的评测基准大多像提前把菜市场整理成标准化厨房,AI只要按部就班就能拿高分,但一到真实的「菜市场」就彻底懵了。
直给地说:真实数据分析的核心难点,从来不是「算出数字」,而是「先找到能算数的数据」。这一步走不通,后面的清洗、计算、验证全是空中楼阁。
传统评测只看AI最终答案对不对,就像只看厨师端出的菜好不好吃,却不管他是用新鲜食材做的,还是用了过期原料瞎凑的。DataClawBench的突破,在于把评测从「结果导向」拉回「过程导向」——它给每个任务标注了「关键里程碑」,也就是专家认为必须完成的中间步骤,比如「找到2022年各省份新能源汽车产量数据」「统一企业名称口径」,通过追踪AI在这些节点的表现,就能精准定位它在哪一步掉了链子。
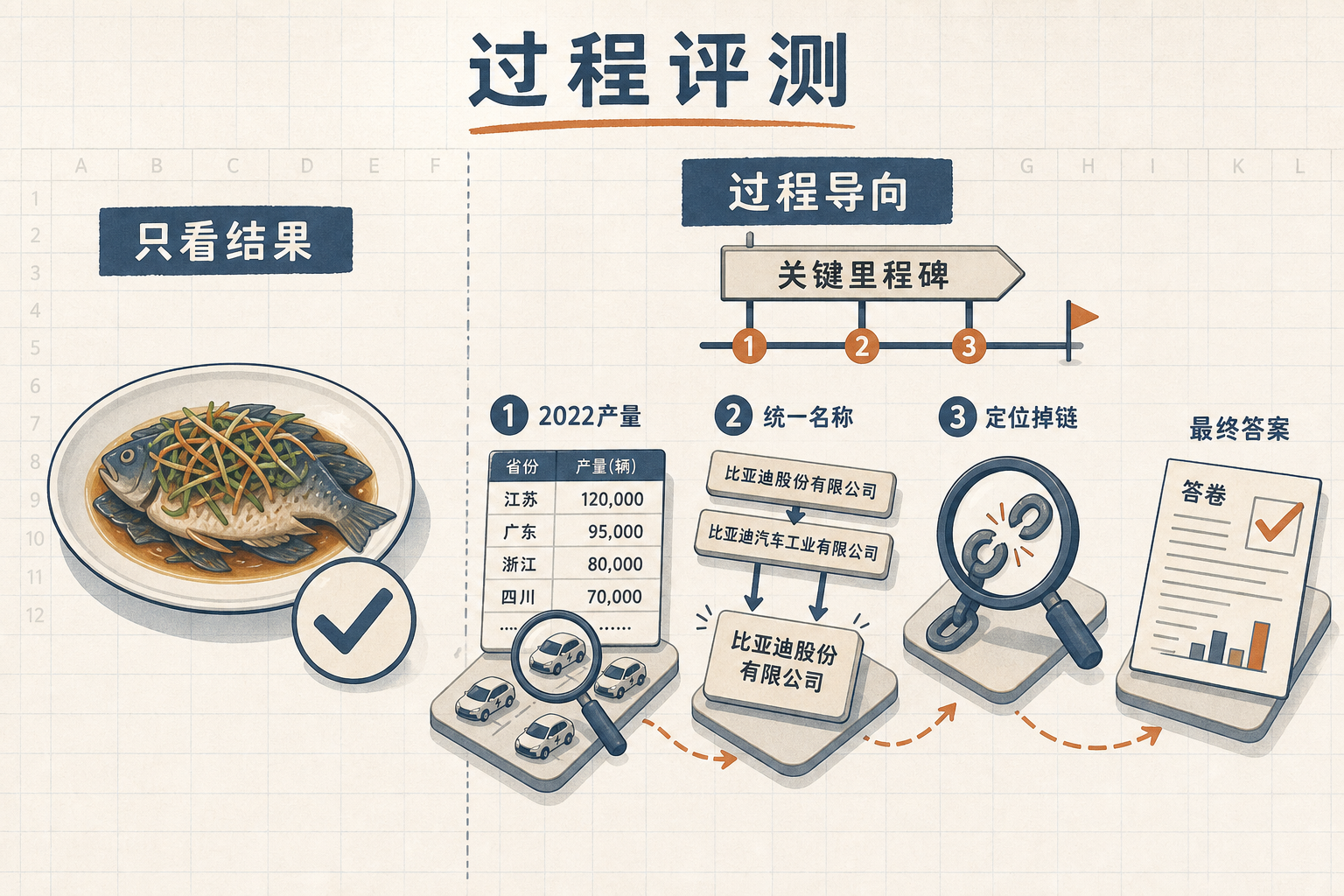
测试后,8款AI被分成了四类:Claude Opus 4.6是「决断派」,找证据快且准;Gemini 3.1 Pro和Minimax M2.7是「磨叽坚持派」,能找到证据但效率极低;DeepSeek-V3.2和Qwen3.5-Plus是「乱试派」,花了大量时间却没摸到关键线索;GPT-5.4、Kimi-K2.5和GLM-5则是「躺平派」,稍微找不到就直接放弃。
更值得关注的是,同一个错误答案背后,可能藏着完全不同的失败逻辑:有的AI是根本没找到数据,有的是找到了数据但用错了口径,还有的是中间计算时把逻辑链弄断了。这也解释了为什么实验室里的高分模型,一到真实场景就失效——它们可能只是在预设好的环境里「背熟了答案」,而非真正掌握了分析能力。
为了搞清楚AI到底卡在哪,研究者做了一组对照实验:先给AI原始的嘈杂数据环境,再逐步移除噪声、提供完整的字段说明。结果发现,移除噪声能让简单和中等难度任务的准确率有所回升,但高难度任务依然全军覆没;只有当提供完整的字段引导后,高难度任务的准确率才勉强爬到20%。
这说明AI同时在和三重不确定性搏斗:嘈杂的无效数据、零散的数据源、模糊的字段定义。而最致命的问题是,AI往往在任务最早期就丢失了线索。测试显示,除了Claude Opus 4.6,其余AI在简单任务上有超过80%的概率卡在第一个里程碑,中等和高难度任务也有一半以上的概率在第一步就失败——就像厨师刚进菜市场,连要找的菜叫什么都没搞清楚,就开始乱逛。
更有意思的是,AI面对不同任务的失败反应截然不同:找不到具体实体数据时,它会主动放弃;但面对聚合、比较这类需要推理的任务,哪怕证据不全,它也会硬着头皮输出一个看似合理的答案——这就像厨师找不到食材,干脆用调料瞎兑了一碗汤,还硬说这是招牌菜。
当我们为AI生成的精美报告惊叹时,往往忽略了一个最朴素的真相:所有智能的基础,都是对真实世界的准确感知。AI在实验室里的风光,本质是因为人类替它扫清了所有感知障碍;而一旦进入真实的开放式环境,它就像突然失明的人,连路都走不稳。
「实验室的光鲜,从来不是落地的通行证。」这句话放在AI Agent身上再合适不过。未来的AI要真正走进职场,可能不需要更强大的计算能力,而是先学会像人类分析师那样,在混乱的数据里「摸清楚情况」——毕竟,先找到正确的问题,比给出漂亮的答案更重要。