
1 个月前
1 个月前
当机器人后空翻的视频刷爆朋友圈,当机械臂精准冲泡咖啡的演示收获数万点赞,没人会怀疑具身智能的爆发式增长。但很少有人问:这些惊艳的表演,到底是机器人真的学会了适应世界,还是仅仅在特定场景下被反复调教出的「表演」?2026年3月,中山大学联合多机构推出的ManipArena,第一次把这个行业悬而未决的问题,变成了可以用数据回答的科学命题——它不是又一个炫技舞台,而是给具身智能做「全面体检」的精准标尺。
你可以把传统的具身智能评测想象成只看一次体温就判断健康,而ManipArena的分层OOD评测,是给模型做了一次从常规体检到极限挑战的完整心电图。它把每个任务拆成10个难度层级:T1到T4是「常规体检」,测试机器人在训练过的场景里的稳定性,比如移动训练中见过的不锈钢勺;T5到T8是「小感冒测试」,引入视觉偏移,比如换成形状不同的儿童勺;最苛刻的T9到T10是「极限挑战」,直接拿出训练时从未见过的黑色塑料勺,测试真正的语义泛化能力。
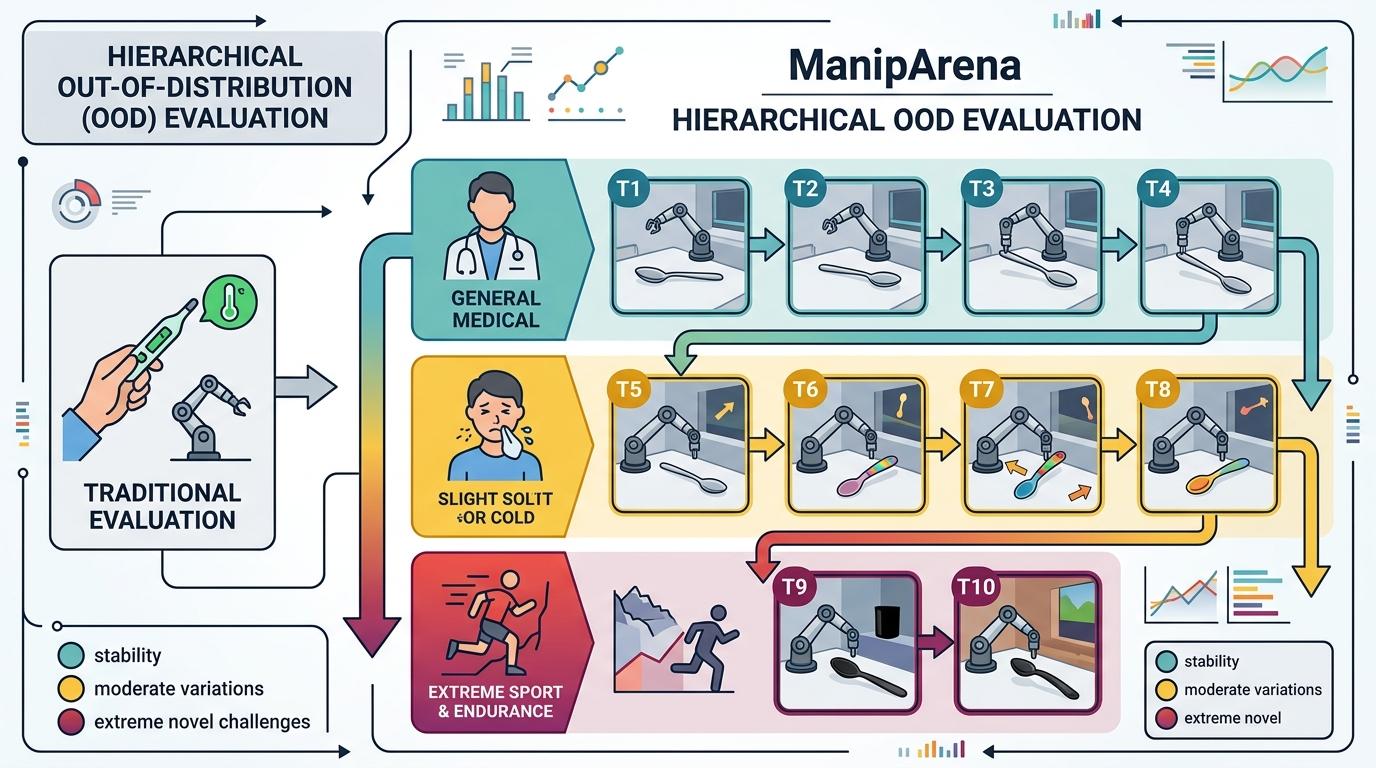
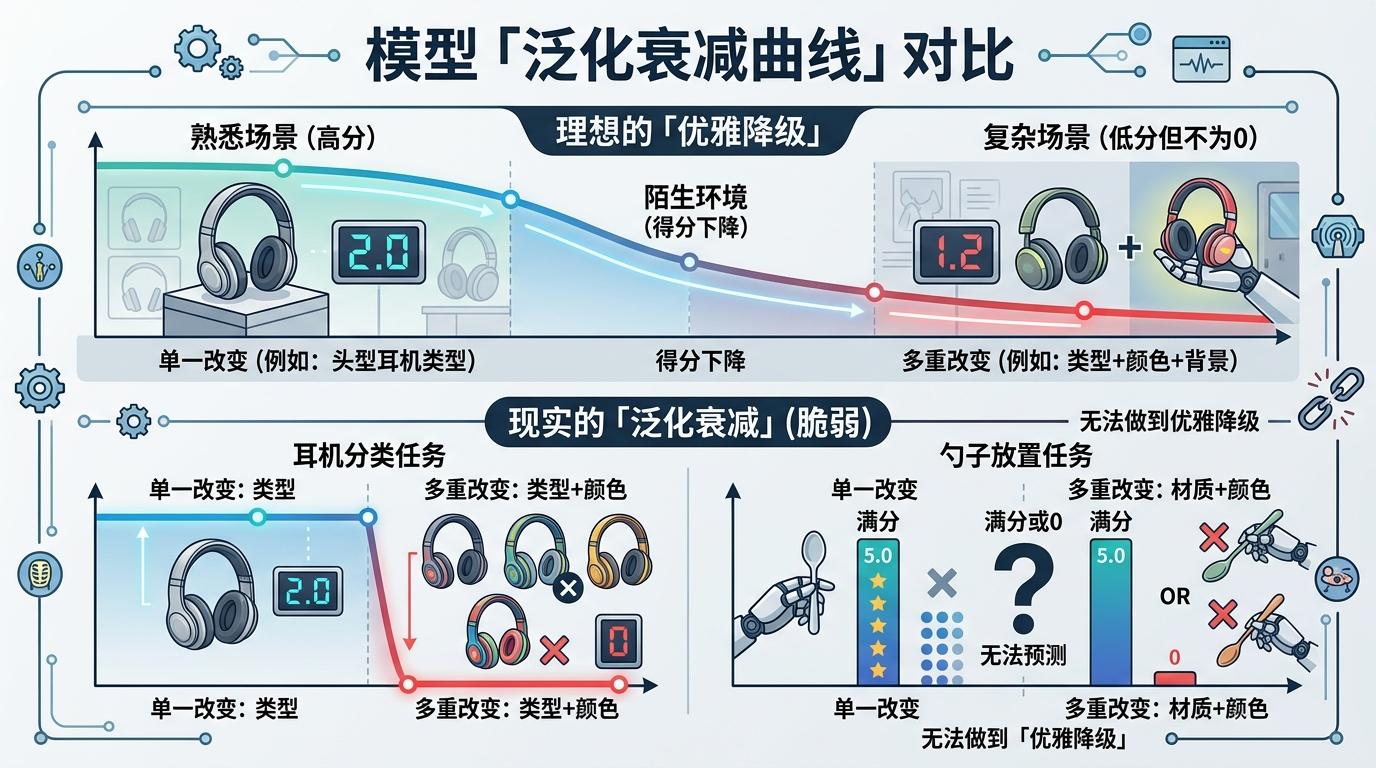
这种阶梯式设计,能让单次评测就画出模型的「泛化衰减曲线」——就像心电图能看出心脏在不同负荷下的表现,它能精准显示模型从熟悉场景到陌生环境的性能跌落点。比如在耳机分类任务中,单一改变耳机类型时,模型还能拿到2.0分,但同时改变类型和颜色,得分直接暴跌到0;勺子放置任务里,材质和颜色同时变化时,模型要么拿满分要么得0,完全做不到「优雅降级」。这些数据第一次直白地揭示:当前的具身智能模型,泛化能力比我们想象的脆弱得多。
ManipArena的首批测试,直接把当前具身智能的两大技术路线拉到了同一场公平对决里——代表视觉-语言-动作模型(VLA)的π₀.₅,和代表世界模型(WAM)的DreamZero。
VLA模型就像训练有素的工匠,精细操作能力极强,能完成亚厘米级的精准插线,但泛化能力脆弱得像玻璃:面对从未见过的物体,性能会出现灾难性退化。而世界模型更像经验丰富的探险家,泛化鲁棒性出色——当篮子位置从右侧移到左侧,π₀.₅的得分暴跌44%,DreamZero只下降了8%。但它的软肋同样明显:只能完成粗粒度操作,精细任务完全力不从心,单步推理耗时更是比VLA慢50到70倍。
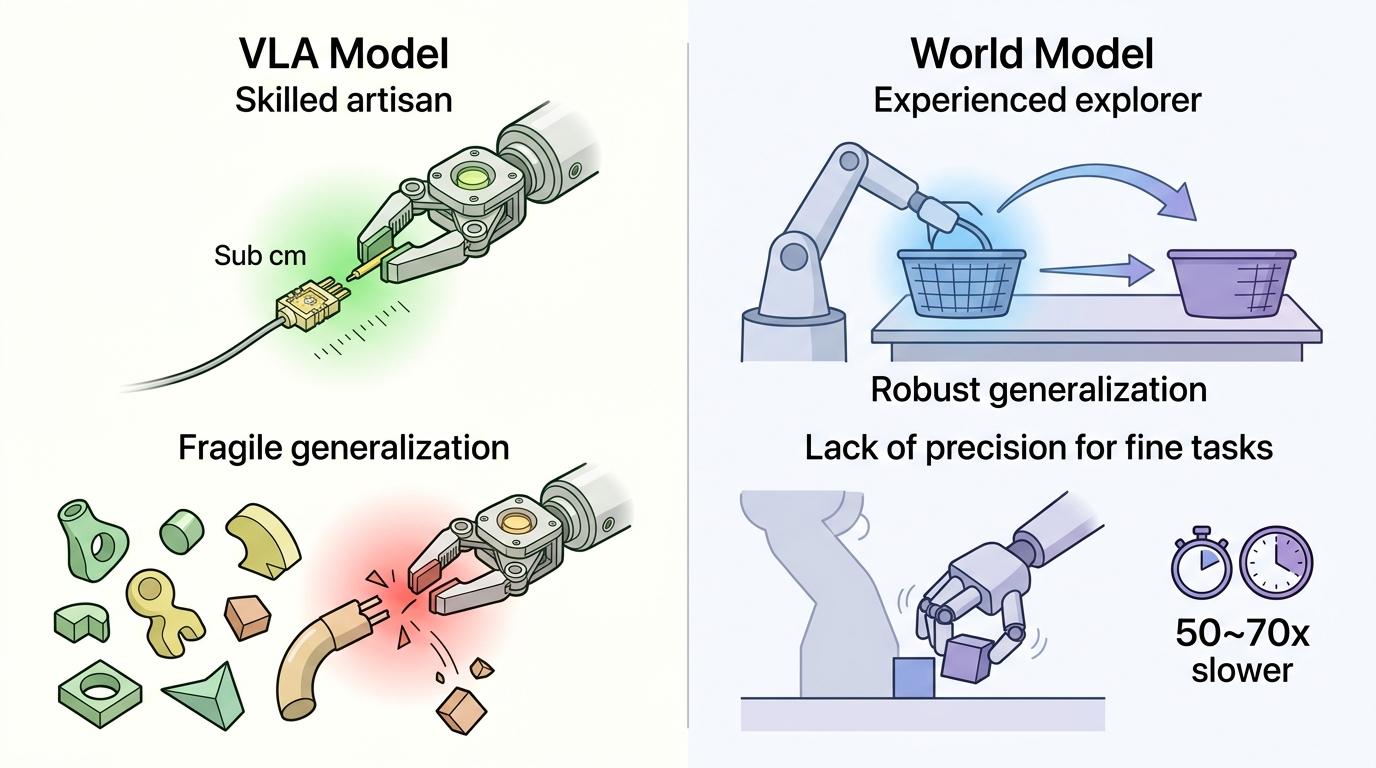
这次对决没有赢家,只有清晰的能力边界:未来的通用具身智能,必须是「工匠+探险家」的融合——既要VLA的精细操作能力,也要世界模型的泛化鲁棒性。而ManipArena的价值,就是第一次用真实的真机数据,明确指出了这条融合的方向。
在ManipArena出现之前,具身智能行业一直面临「劣币驱逐良币」的风险:因为缺乏统一的真机评测标准,研发资源更容易流向那些容易出视觉效果的「表演项目」,而真正投入泛化能力研发的团队,却难以证明自己的价值。
ManipArena从根源上解决了这个问题:它用统一的双臂机器人平台、封闭的绿幕环境排除了硬件和环境干扰,确保所有模型在完全相同的物理条件下竞争;「一个模型应对所有任务」的规则,直接封死了针对单一任务过度拟合的捷径;远程真机评测架构,让研究者不用购买昂贵硬件就能参与,极大降低了行业准入门槛。
更重要的是,它第一次为行业提供了可量化、可复现的泛化能力基准。未来,当企业要判断一个具身智能模型的真实能力,当投资者要评估研发团队的技术实力,ManipArena的评测数据,会成为最有说服力的标尺。
当我们为机器人的炫技欢呼时,ManipArena提醒我们:真正的智能,从来不是在特定场景下的完美表演,而是在陌生环境中依然能从容应对的适应力。它就像一面镜子,照出了当前具身智能的真实水平,也为行业指明了前进的方向。
从炫技到实用,具身智能终于踩在了坚实的地面上。 未来的机器人,不该是舞台上的表演者,而应该是能走进真实世界,帮我们解决问题的合作者。ManipArena的出现,正是这个转变的开始。
点击充电,成为大圆镜下一个视频选题!