
2 天前
2 天前
你有没有过这种经历:用手机拍了4K日落,暗部却糊着一层彩色噪点,像撒了把碎芝麻;想用AI修图,要么细节被磨平,要么电脑风扇狂转半小时才出一帧。这是4K视频去噪的经典死局:要质量就得用大模型,速度慢到离谱;要速度就得砍精度,画质惨不忍睹。直到今年4月,青岛大学等团队拿出的UHD-GPGNet,把这个死局砸出了个口子——一个只有70万参数的“迷你模型”,居然做到了和顶级大模型一样的去噪质量,还能以28帧/秒的速度实时处理4K视频。
要搞懂这个模型的厉害,得先戳破传统去噪方法的痛点:它们都是“一刀切”。视频去噪的核心是用相邻帧信息补当前帧,但不同区域的需求天差地别——天空这种平滑区域,多帧平均就能把噪点抹干净;但风中的柳枝、人物的发丝,要是敢平均,直接就成模糊的重影。

UHD-GPGNet的解法,是给模型加了个“侦察兵”:稀疏高斯过程。你可以把它想象成一个会看菜下饭的厨师——它先给视频的每个区域“体检”,算出两个关键数据:一个是这里的噪声有多严重,另一个是它对这个判断的“信心值”(也就是不确定性)。比如碰到发丝边缘,它会给出“高不确定性”的信号,意思是“这里细节复杂,别乱平均”;碰到天空,就给出“低不确定性”,意思是“放心大胆用多帧信息降噪”。
这个“信心值”会被转换成一个动态的融合门控——就像智能开关,在平滑区域打开多帧融合的闸门,在细节区域把闸门关上,优先保留当前帧的纹理。和传统深度学习模型靠海量数据“隐式学经验”不同,高斯过程是“显式讲道理”,用概率模型直接量化每个区域的处理优先级,这才是它能以小参数实现高质量的关键。
光有聪明的思路还不够,要让70万参数的模型扛住4K视频,每一个设计都得抠到骨头里。
首先是“稀疏”二字的威力。传统高斯过程的计算复杂度是O(N³),N是像素数,4K视频有800多万像素,根本算不动。UHD-GPGNet用了“诱导点”的方法:从密集的像素里选出少数关键代表点,只在这些点上做高斯过程计算,再通过核函数把结果扩散到所有像素,把复杂度降到了O(NM²),M是诱导点数量,比如每帧只选16个,计算量直接砍到原来的几万分之一。
其次是分而治之的工程技巧。4K单帧的特征图太大,GPU显存装不下,模型就把视频切成带重叠的小块,处理完再用加权拼接的方式拼回去,完美避开接缝瑕疵。同时,它还把视频拆成亮度、色度、RGB三个分支分别处理——亮度分支管最影响观感的明暗细节,色度分支管颜色稳定性,RGB分支补全局信息,既分工明确又互不干扰,最后再用结构-色彩协同模块把结果整合,保证画质和色彩都不翻车。
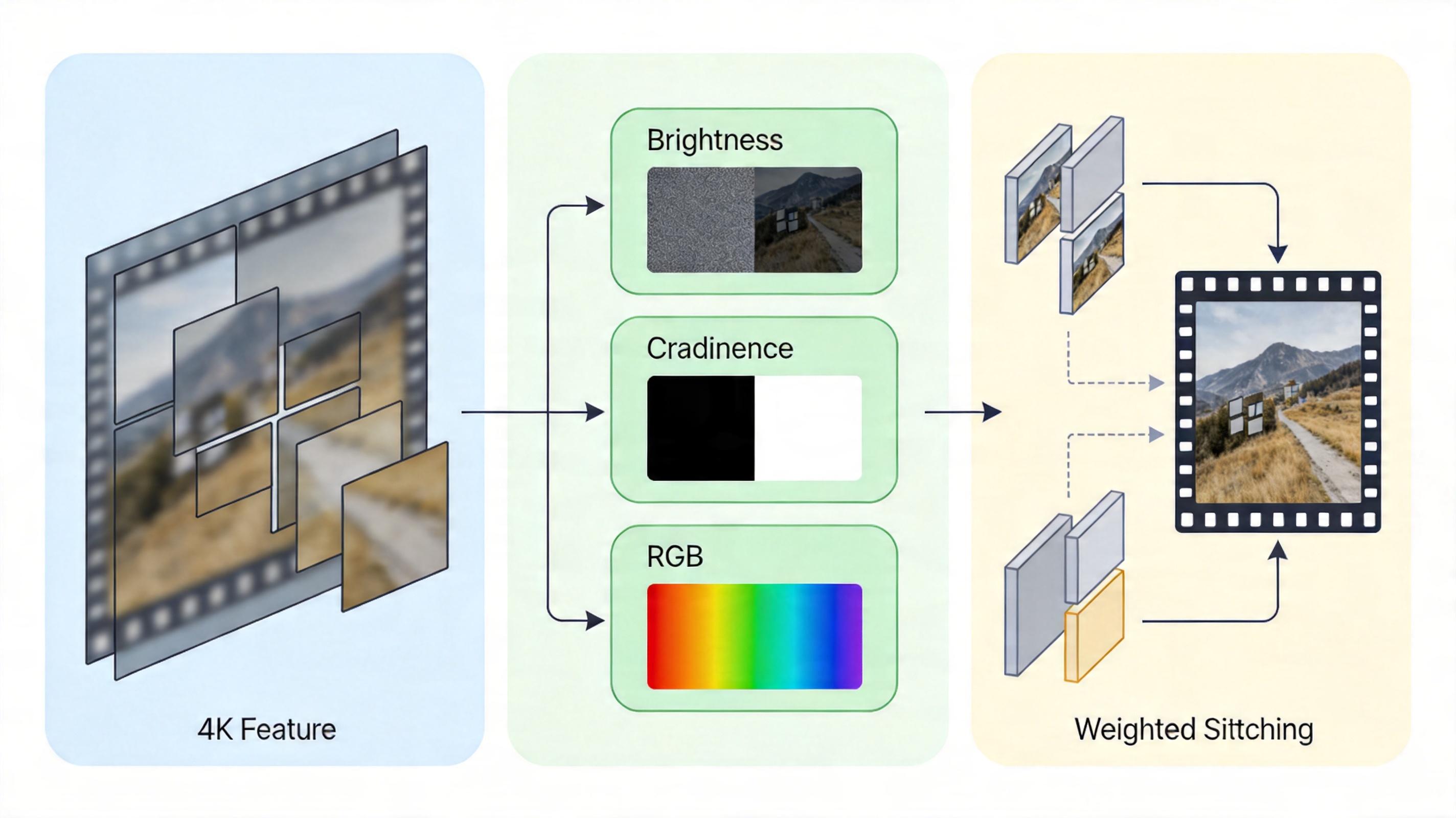
更关键的是,它的性能提升不是靠堆参数。论文里做了个扎心的对比:给模型加等量参数的注意力机制,性能反而不如高斯过程模块。这说明真正值钱的不是参数数量,而是高斯过程带来的“空间局部性+时序平滑”的结构化归纳偏置——相当于给模型装了个内置的“视频规律知识库”,不用学也知道该怎么处理不同区域。
当然,UHD-GPGNet也不是万能的。它现在只能处理固定5帧的输入,碰到快速运动的场景,比如赛车、飞鸟,可能还是会力不从心;稀疏高斯过程的近似计算,理论上还是会丢失一点细粒度的信息;而且训练的时候,因为要优化高斯过程的参数,复杂度比纯深度学习模型要高一些。
但这些局限掩盖不了它的价值:它第一次把传统概率模型和深度学习的结合,从“概念验证”推到了“工程可用”的阶段。以前我们总觉得,要提升AI模型的性能,要么堆参数,要么堆数据,但UHD-GPGNet证明,给模型注入“结构化的先验知识”,能以小得多的代价实现同样甚至更好的效果。
从产业角度看,它的低显存、快速度的特性,刚好踩中了当下的需求:现在手机、监控、自动驾驶都在往4K甚至8K走,谁都需要一个能在边缘设备上跑的高质量去噪模型。UHD-GPGNet已经在真实手机视频上证明了自己的泛化能力——不用针对真实噪声微调,直接就能用,还能提升下游目标检测的准确率,这意味着它离落地只有一步之遥。
当我们还在争论“大模型和小模型哪个更好”的时候,UHD-GPGNet已经跳出了这个框架:它用传统概率模型的“智”,补了深度学习的“拙”,用70万参数做到了别人几千万参数才做到的事。
这背后其实是一个更值得深思的趋势:AI的未来,可能不是比谁的模型更大,而是比谁能更聪明地利用知识——不管是数据里学来的,还是数学里借来的。用最少的参数,解决最硬的问题,这才是AI真正该有的样子。毕竟,我们需要的不是一个需要超级计算机才能跑的“实验室玩具”,而是一个能装在手机里、监控里、汽车里,随时能帮我们把模糊变清晰的实用工具。
点击充电,成为大圆镜下一个视频选题!