对抗知识焦虑,从看懂这条开始
App 下载
3D建模换了个思路,落地速度快了10倍
NeRF|南洋理工|浙大|照片生成3D场景|前馈式3D建模|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载NeRF|南洋理工|浙大|照片生成3D场景|前馈式3D建模|AI产业应用|人工智能
你有没有想过,手机拍几张照片就能秒出完整3D模型?以前这是天方夜谭——传统3D建模要对着每个场景反复优化,一张复杂场景图可能要算几个小时。但现在,来自浙大、南洋理工等全球6所高校的研究者,把这件事的效率拉到了新高度:他们提出的前馈式3D建模,只要一次AI推理,就能直接从照片生成3D场景,测试阶段成本砍掉90%,跨场景复用能力提升3倍。更关键的是,他们不再纠结用NeRF还是3D高斯点云,而是盯着「解决问题」重新定义了整个领域的研究框架。
以前研究3D建模,大家习惯按输出形式分类:NeRF派、3D高斯点云派、点图派……就像厨师只按用的锅分类,却不管做的是川菜还是粤菜。但这次的综述论文直接推翻了这个逻辑:同一种锅能做不同菜,同一个菜也能用不同锅。真正推动技术进步的,从来不是工具,而是要解决的问题。
研究者把前馈式3D建模拆成了五大核心难题:先把2D照片的特征「学明白」(特征增强),再让模型「懂空间几何」(几何感知),还要兼顾速度和成本(模型效率),用AI补全缺失细节(增强策略),最后延伸到动态场景(时序感知)。每一个方向都对应着落地时的真实痛点——比如自动驾驶需要实时重建,就重点优化模型效率;机器人要抓透明物体,就死磕几何感知。
举个直观的例子:特征增强就像给AI装了一副高清眼镜,从早期的CNN到现在的Transformer、Mamba,AI能从照片里抠出更细的纹理和空间关系;而几何感知则是给AI补了一节立体几何课,让它不会把平面的海报当成真实的墙面。
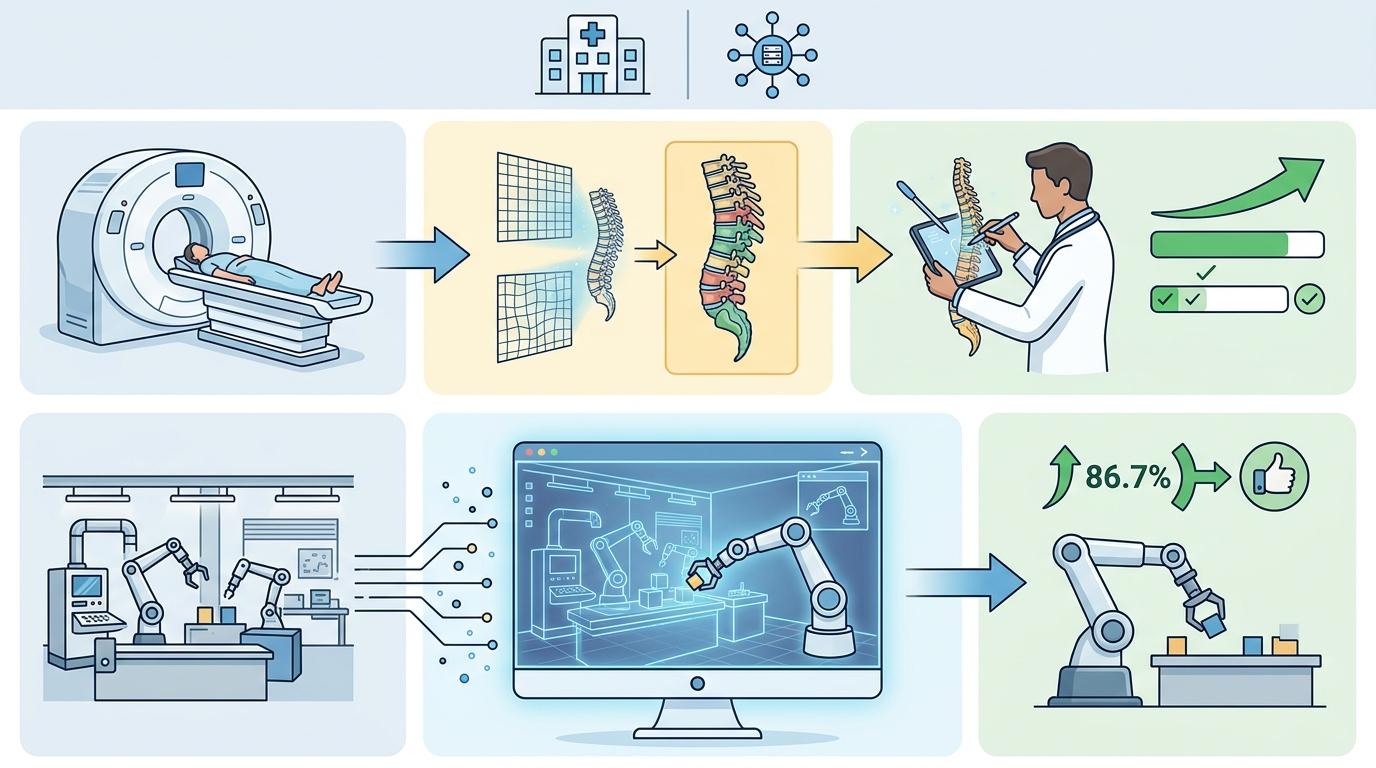
前馈式3D建模的最大价值,从来不是在论文榜单上刷分,而是能真正走进现实。在自动驾驶领域,DrivingForward模型能从车辆的多视角摄像头里,实时重建周围的3D场景,推理时间只要0.6秒,比传统方法快了近10倍,还不需要提前标注任何数据;在机器人抓取里,GraspNeRF能仅凭几张RGB照片,就精准算出透明玻璃杯的抓取姿态,成功率比依赖深度摄像头的方法高40%。
更有意思的是数字孪生领域的应用:Mayo Clinic用前馈式3D建模,把患者的CT图像秒转成等比例3D模型,医生能拿着模型模拟手术路径,复杂脊柱手术的规划时间从几小时压缩到20分钟。而在工业仿真里,Mirage2Matter平台用3D高斯点云重建真实车间,机器人在仿真里学的抓取技能,零样本迁移到真实世界的成功率能到86.7%,几乎和真实训练的效果持平。
当然,它也不是万能的。比如在极端光照下,模型还是会把反光的地面当成水面;动态场景里快速移动的物体,重建出来还是会有虚影。但这些问题,正是研究者下一步要啃的硬骨头。
现在的前馈式3D建模,还只是「看一眼就复刻」,但它的终极目标,是成为世界模型的基础模块——也就是能像镜子一样,实时反映整个物理世界的动态变化。
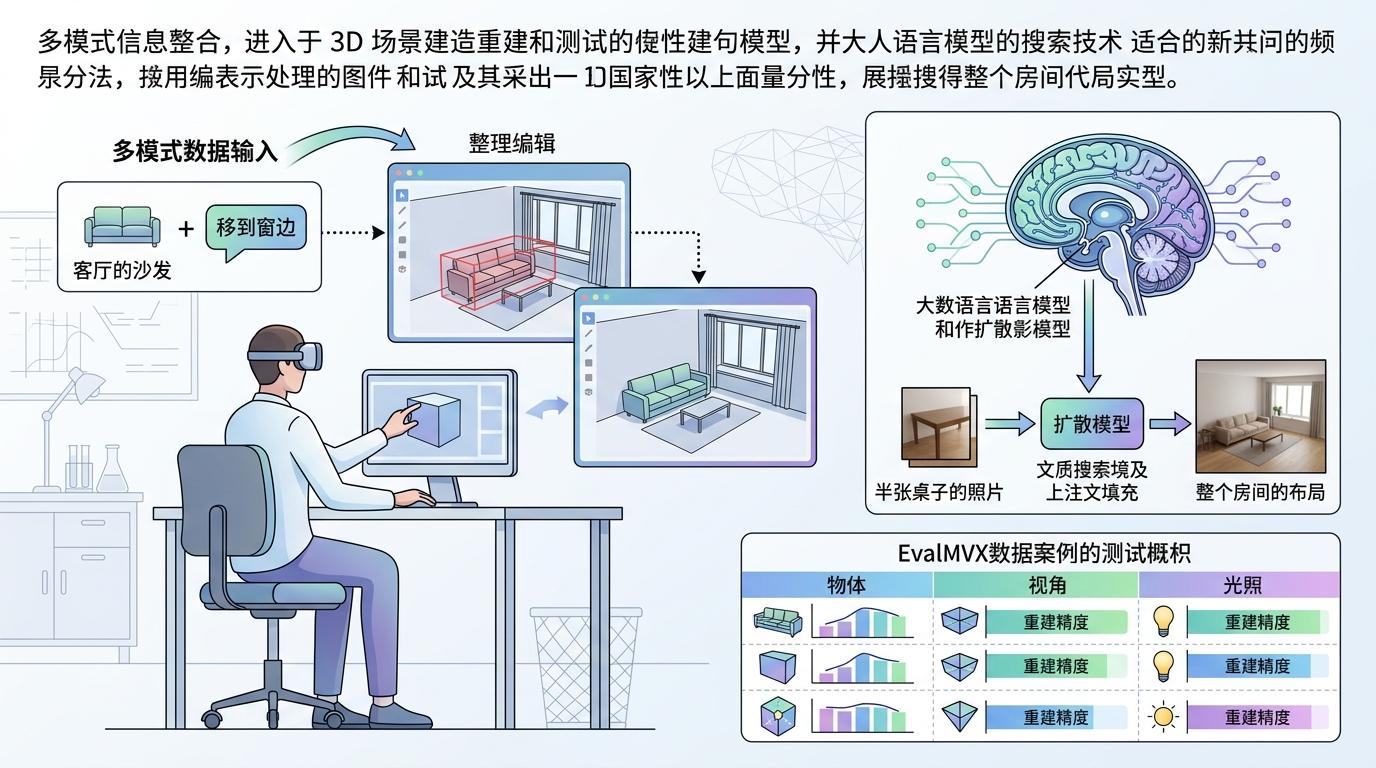
研究者已经开始尝试把多模态信息揉进去:比如结合语言模型,让AI能听懂「把客厅的沙发移到窗边」,直接生成修改后的3D场景;或者用扩散模型补全照片里缺失的部分,比如从半张桌子的照片,还原出整个房间的布局。EvalMVX数据集的出现,更是给这个方向提供了统一的标尺——它包含25个物体、2525个视角、16种光照,能同时测试模型在不同场景下的重建能力。
从市场数据看,全球3D建模市场到2032年将达到321亿美元,年复合增长率24.9%。前馈式建模就像这个赛道的「涡轮增压引擎」,一边降低建模门槛,一边提升应用效率。未来可能你用手机拍个视频,就能生成自己的数字孪生空间;自动驾驶汽车能实时更新周围的3D地图,连路边刚停的自行车都不会漏掉。
当我们谈论3D建模时,我们其实在谈论如何让机器真正「看见」世界——不是看见像素,而是看见空间、关系和变化。前馈式建模的出现,把这个过程从「慢工出细活」变成了「一眼即世界」。
解决问题,永远比纠结工具更重要。 这句话不仅适用于3D建模,也适用于所有技术的发展。未来的AI不会是拿着锤子找钉子的工匠,而是能根据需求随时拿起合适工具的解决者。而前馈式3D建模,就是这个解决者手里最趁手的那把刀。