对抗知识焦虑,从看懂这条开始
App 下载
机器人不再只会动手,开始学着「想明白」再做
机器人家务|动作执行|推理决策|ICRA机器人挑战赛|具身智能|人工智能
对抗知识焦虑,从看懂这条开始
App 下载机器人家务|动作执行|推理决策|ICRA机器人挑战赛|具身智能|人工智能
当你对机器人说「把桌面收拾干净」,它不再是机械地把杂物扫到一边——它会先盯着桌上的书本、半杯水、皱巴巴的零食袋愣两秒,像个刚被布置家务的孩子那样「想一想」:哪些是要扔掉的垃圾,书本该摞成多高,水杯要放到不被碰倒的角落。这不是科幻电影里的场景,而是2026年ICRA机器人挑战赛最核心的考题。这场曾经比拼「谁叠衣服更快」的比赛,今年彻底换了赛道:它要让机器人学会「推理」,而不只是做个精准的「机械手」。为什么整个行业突然调转了方向?这背后,是具身智能从实验室走进真实世界的关键一步。
你可以把传统的机器人看成一个只会照本宣科的实习生——给它明确指令「把红色杯子放到蓝色盘子上」,它能精准完成,但你要是说「把桌面收拾干净」,它只会一脸茫然。这就是过去具身智能的核心局限:只能执行「短程、明确」的动作,却听不懂「模糊、开放」的任务。
今年的挑战赛把赛道从「操作」改成了「推理到操作」,本质是要迈过两道门槛:一是理解「模糊指令」,比如判断什么是「干净」;二是学会「举一反三」,比如见过推拉门后,能自己琢磨怎么开旋转门。这背后的技术核心,是**动作链式推理(Action Chain-of-Thought)**——让机器人像人类一样,把复杂任务拆成一步步可执行的子任务。
打个比方,收拾桌面这个任务,机器人的推理链会是:「识别物品→分类(垃圾/书本/水杯)→规划顺序(先扔垃圾,再摆书本,最后放水杯)→执行每个动作」。而支撑这个推理链的,是融合了视觉、语言和动作的VLA模型——它能把人类的自然语言,翻译成机器人能理解的动作序列。
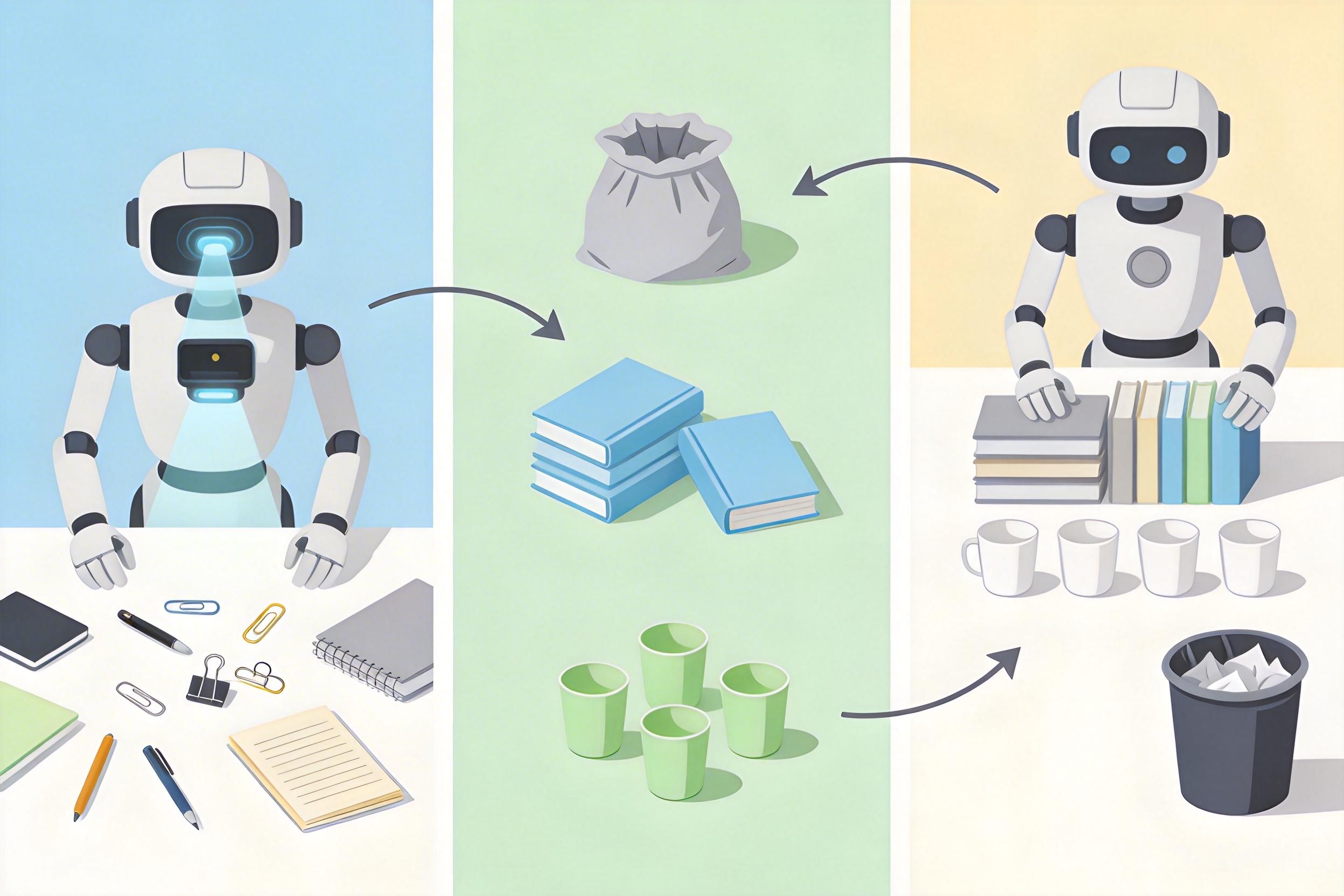
但真实的机制比这个类比更精确:机器人会先通过视觉传感器构建桌面的3D场景图,再用大语言模型解析「干净」的语义,接着生成包含17个细分动作的序列,最后逐个执行并通过力觉传感器调整力度——比如放杯子时不会把水洒出来。

现在的具身智能领域,有两条并行的技术路线在竞速:一条是刚才说的VLA模型,另一条是**世界模型(World Model)**。如果把VLA模型比作「反应敏捷的执行者」,能快速把指令变成动作,那世界模型就是「未雨绸缪的预演者」——它会先在脑子里构建一个虚拟的环境模型,预测每个动作的后果,再规划最优路径。
比如让机器人开门,VLA模型会直接根据视觉输入生成「伸手、握把手、转动」的动作;而世界模型会先模拟:「如果我用5牛的力转把手,门会开多少度?如果把手滑了怎么办?」,然后生成更稳妥的动作序列。
这两条路线不是非此即彼的替代关系,更像是左右手的配合。今年挑战赛同时设置两个赛道,就是在推动两者的融合:用世界模型做长远规划,用VLA模型做实时执行。而赛事提供的基线模型,正是这种融合的尝试——它在VLA模型里加入了链式推理,让机器人能「想明白」再动手,相比去年的模型,真实任务成功率提升了17%。
但这种融合也面临着现实挑战:世界模型需要海量的真实环境数据来训练,而采集机器人的物理交互数据成本极高——比如让机器人开1000次不同的门,不仅耗时,还可能损坏设备。
要让会推理的机器人走进千家万户,还有三道坎要跨。
第一道是数据和人才的缺口。顶尖的具身智能人才需要懂机器人、AI、认知科学等多个领域,培养周期极长;而真实机器人的训练数据更是稀缺——目前行业的数据量,相比需求还差10万倍。现在的解决方案是「多层次数据融合」:用低成本的人类视频和仿真数据做预训练,用高精度的真实机器人数据做微调,比如赛事提供的Genie Sim 3.0仿真平台,能把仿真到真实的误差控制在10%以内。
第二道是仿真与现实的差距。仿真环境再逼真,也模拟不了真实世界的所有变量——比如桌面的摩擦力、杯子的重量差异,这些细微的差别,可能让机器人在仿真里完美完成的动作,到真实世界里就失败。现在的研究者正在用「领域随机化」解决这个问题:在仿真里随机改变物理参数,让机器人适应各种可能的环境。
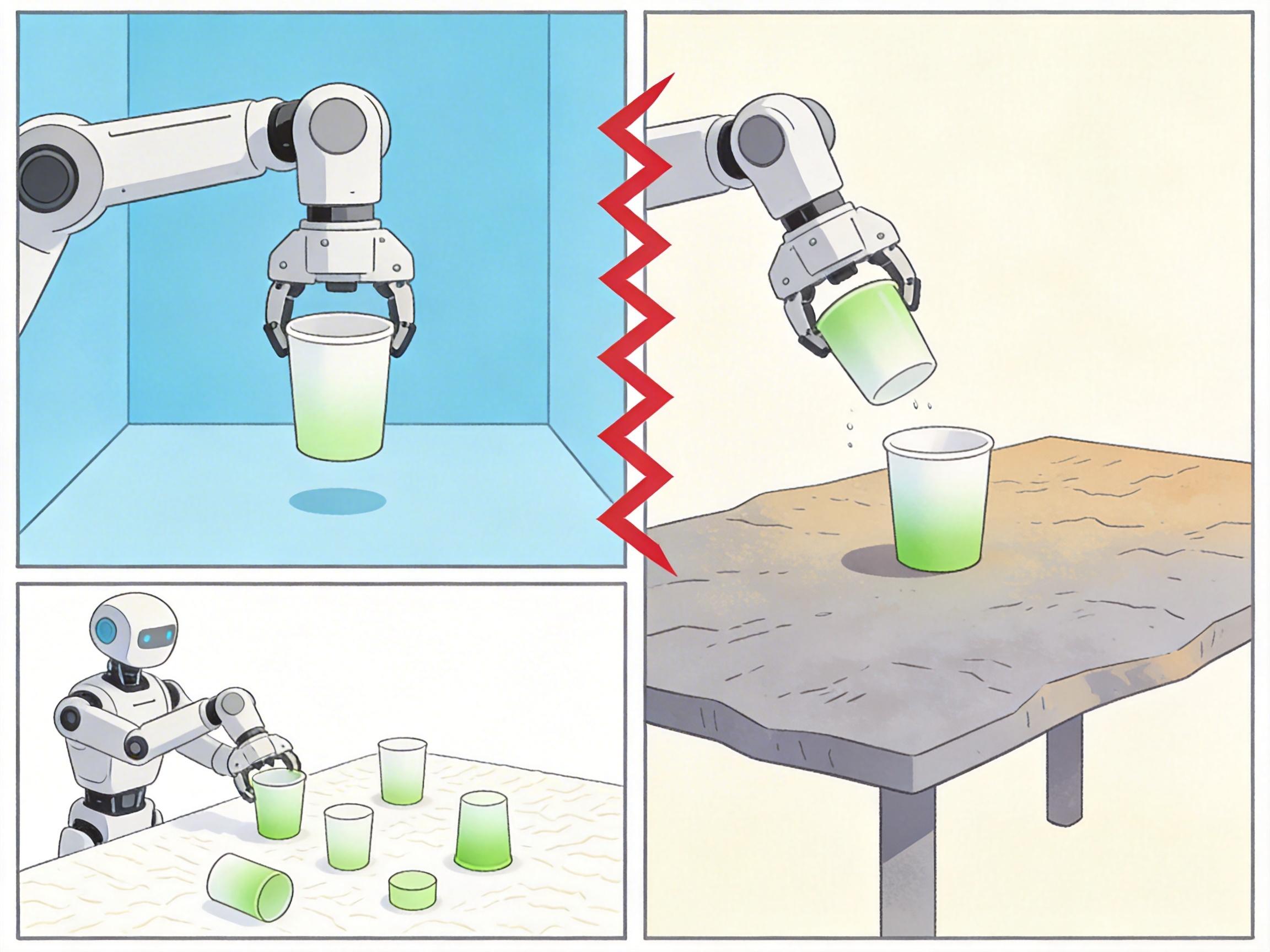
第三道是推理的安全性和可解释性。如果机器人在医院里推理错误,把药物递给了不该拿的人,后果不堪设想。但现在的AI模型大多是「黑箱」,人类不知道它为什么做出某个决策。解决这个问题的关键,是让机器人的推理链变得透明——比如它能告诉人类「我把水杯放到这里,是因为这里不会被碰到」,而不是默默执行。
当机器人开始学着「想明白」再动手,我们离拥有一个能真正理解人类需求的智能伙伴,又近了一步。但这不仅仅是技术的进步,更是对人类自身认知的反向探索——我们终于开始教机器,像我们一样去思考、去决策。
未来的具身智能,不会是一个完美的「超级执行者」,而是一个能在复杂世界里「边想边做」的「合作者」。它会犯错,会调整,会在和人类的互动中不断学习——就像我们每个人一样。
智能的本质,从来不是完美执行,而是学会适应。