对抗知识焦虑,从看懂这条开始
App 下载
动作生成不用二选一:越控制反而越自然
轨迹误差|动作生成|香港中文大学|南洋理工大学|MoTok|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载轨迹误差|动作生成|香港中文大学|南洋理工大学|MoTok|多模态视觉|人工智能
你有没有见过这样的虚拟人:让它抬手时动作僵硬得像牵线木偶,想让它自然走动又会偏离指定路线?这不是技术不够强,而是动作生成领域卡了几十年的死结——要精准控制就丢了自然度,要流畅动作就没了可控性,两者像跷跷板一样此消彼长。直到南洋理工大学与香港中文大学的团队拿出MoTok:只用过去1/6的运算量,把轨迹误差压到0.08厘米,还实现了「约束越多动作越自然」的反常识效果。这背后,是一场对动作生成逻辑的彻底重构。
你可以把动作生成想象成筹备一场晚宴:既要决定「今晚吃川菜还是粤菜」(高层语义规划,动作要做什么),又要精准控制「每道菜的盐放0.5克」(低层细节控制,动作要怎么做)。过去的AI模型,是让同一个厨师同时做这两件事——一边要盯着菜单全局统筹,一边要精准拿捏每勺调料的分量,结果必然顾此失彼:要么菜的搭配乱了套,要么口味差得离谱。
具体到技术上,传统方法把高层语义和低层细节揉在同个生成阶段处理:全局的动作组织需要连贯一致,局部的关节控制要精准到毫米,两种需求在模型里相互拉扯,最后只能在「僵」和「飘」之间选一个。比如用纯扩散模型做动作生成,细节够丰富但像没头苍蝇,给个「挥手」指令可能会甩到天上去;用纯离散token方法,能精准执行指令但动作僵硬,像早期游戏里的NPC。
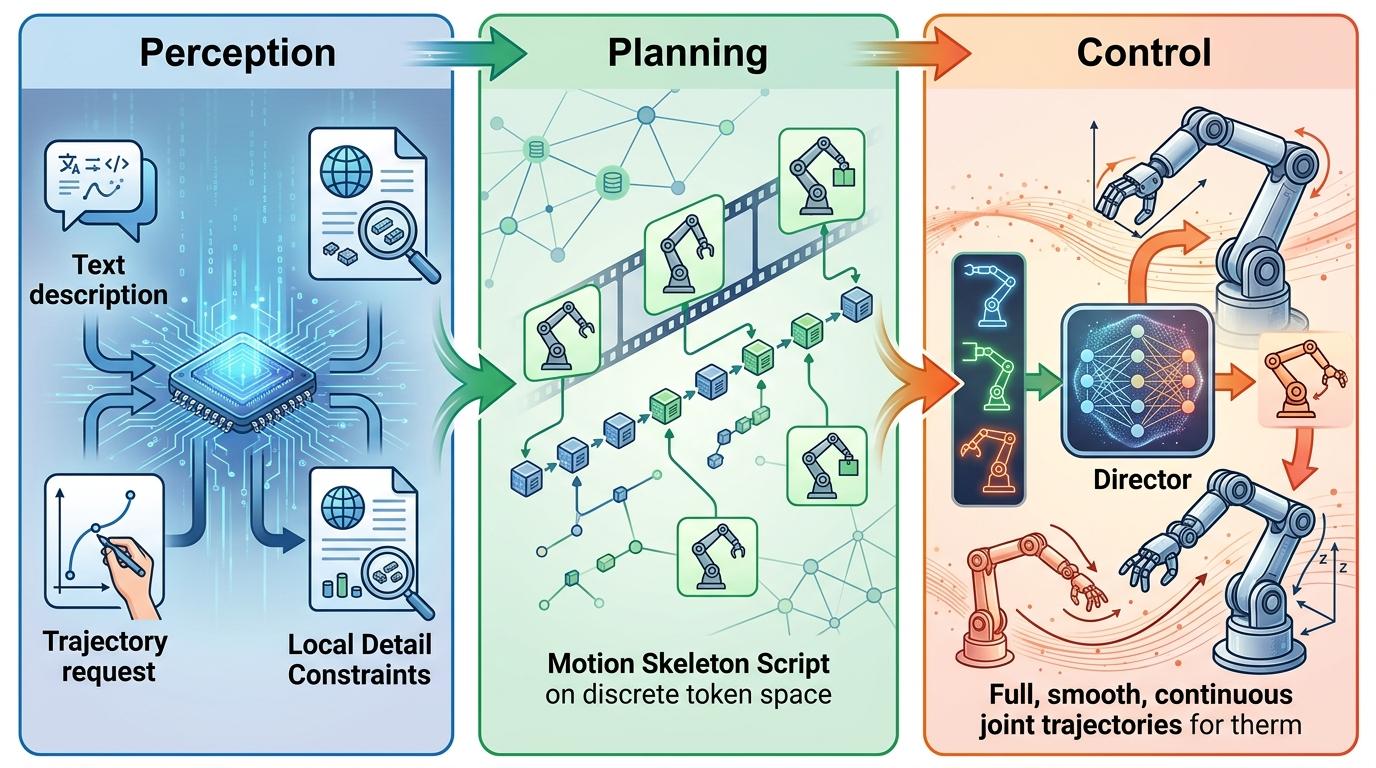
MoTok的解法,是把晚宴的筹备彻底拆分:先找个美食顾问定菜单(感知-规划阶段),再让专业厨师按单做菜(控制阶段)。这就是它首创的「感知-规划-控制」三阶段范式:
第一阶段是感知,负责把输入的指令——不管是文字描述还是轨迹要求——翻译成AI能懂的「任务说明书」,区分出全局的语义要求和局部的细节约束;第二阶段是规划,在离散token空间里生成动作的「骨架脚本」,就像电影分镜只定大动作和关键帧,不管手指怎么摆、膝盖弯多少度;第三阶段是控制,由扩散模型当「执行导演」,把脚本里的骨架填充成流畅自然的完整动作,同时精准贴合关节轨迹要求。
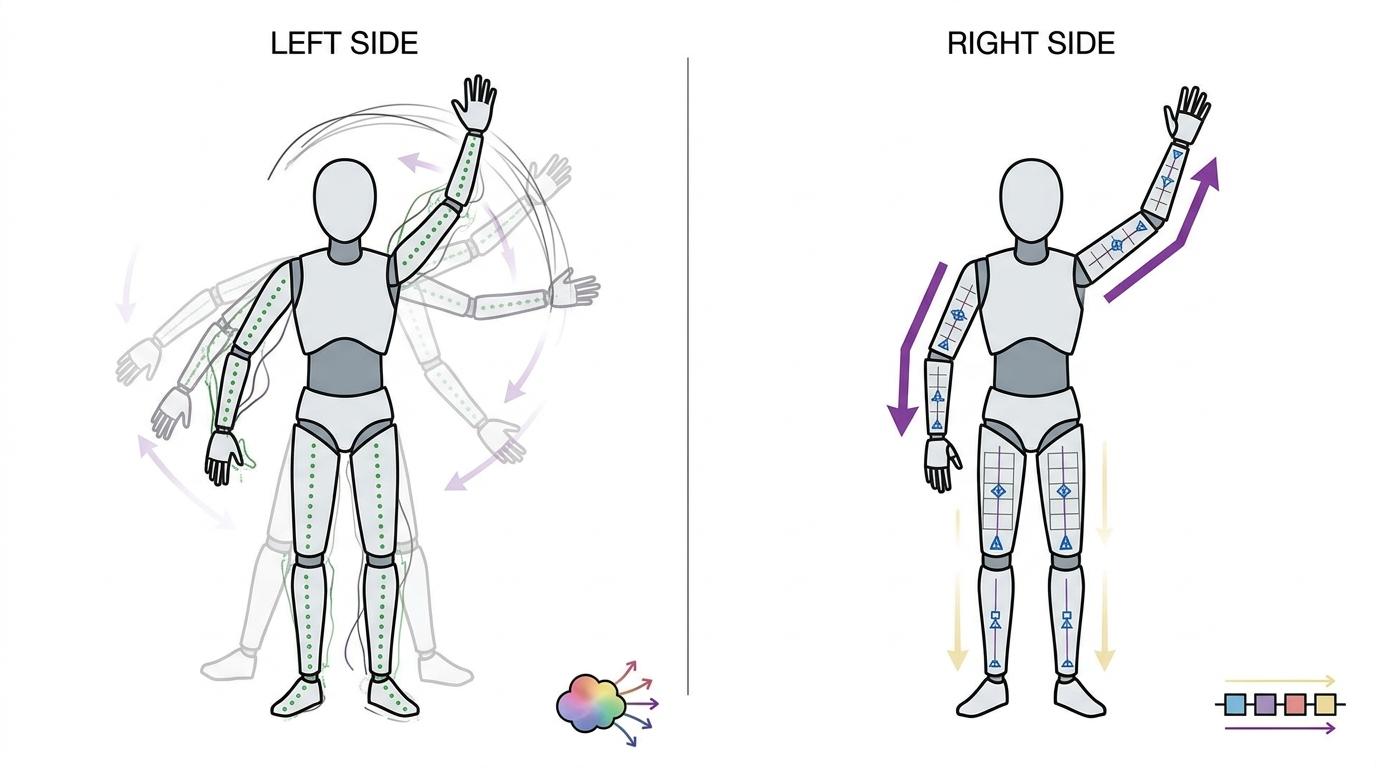
核心的巧思在离散运动tokenizer和扩散解码器的配合:离散token只负责抓动作的语义核心,比如「抬手」「转身」,不用管细节,所以数量能压缩到过去的1/6;扩散模型专门补细节,就像给简笔画上色,既能保证线条精准,又能画出自然的光影层次。实验数据最能说明问题:轨迹误差从0.72厘米降到0.08厘米,相当于从「差一个拳头」到「差一张纸」;衡量动作自然度的FID指标下降65%,意味着生成的动作和真实人类动作几乎没差别。
最颠覆传统认知的,是MoTok实现了「越控制越自然」。过去的模型,给的约束越多动作越僵硬,因为局部的细节要求会打乱全局的动作节奏。但MoTok把约束分成了「粗粒度」和「细粒度」两层:在规划阶段只给粗约束,比如「抬手到肩膀高度」,让AI先把大动作逻辑理顺;到控制阶段再给细约束,比如「手腕要保持水平」,由扩散模型在不破坏全局节奏的前提下微调细节。
团队做了个极端测试:把关节控制强度拉满,结果FID指标再降58%,动作反而更自然了。这就像让厨师做菜时,先定好「做麻婆豆腐」,再要求「豆腐块1厘米见方」「豆瓣酱比例精确到克」——有了清晰的分层指令,厨师反而能更专注地把菜做好,而不是在「选菜」和「调味」之间来回纠结。当然,MoTok也不是完美的:目前它的实时生成速度还跟不上游戏或机器人的实时交互需求,复杂多模态指令的理解精度还有提升空间,但它撕开的这个口子,已经足够改变整个领域的走向。
从早期只能生成僵硬动作的AI,到现在能兼顾精准和自然的MoTok,动作生成的进步,本质上是人类对「智能」理解的深化:真正的智能不是把所有事堆在一起做,而是像人一样,先想清楚「要做什么」,再琢磨「怎么做好」。
分而治之,反而能两全其美。这句话不仅适用于动作生成,也适用于所有被「两难困境」困住的技术领域。当我们不再强迫一个模型同时扮演「决策者」和「执行者」,AI反而能释放出更大的潜力——就像MoTok生成的动作一样,既听话,又灵动。