对抗知识焦虑,从看懂这条开始
App 下载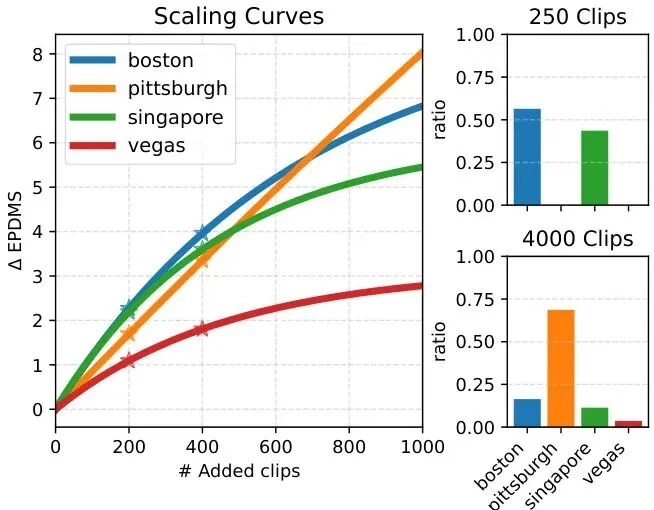
自动驾驶省80%训练数据,靠的不是模型是选数据
数据利用率|自动驾驶场景|数据聚类|训练数据筛选|自动驾驶|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数据利用率|自动驾驶场景|数据聚类|训练数据筛选|自动驾驶|人工智能
想象你是自动驾驶团队的负责人:车队每年攒下数百万小时的驾驶录像,从波士顿的连环环岛到拉斯维加斯的深夜高速,从暴雨天的拥堵到乡村路的碎石,数据多到硬盘在哭,算力却不够用。老板要你用这些数据训出最好的模型,但预算只够喂1/5的数据。挑哪部分?随便选可能漏了紧急避让的关键场景;均匀采样,波士顿的环岛和拉斯维加斯的直道,对模型的价值能一样吗?2026年,一支研究团队拿出的方案,把这个难题解决得干脆利落:只用20%的数据,就达到了全量数据训练的效果。
你可以把自动驾驶的训练数据想象成一锅大杂烩:有海鲜、有青菜、有主食,混在一起煮,既浪费食材,也煮不出好菜。MOSAIC做的第一件事,就是把这锅菜按食材类型分开——也就是数据聚类。
聚类不是简单按地理位置或天气分堆,而是用算法找出那些“对模型提升效果相似”的数据。比如波士顿的环岛、旧金山的陡坡,虽然地理位置不同,但都属于“需要复杂转向决策”的场景,会被归为一类;而拉斯维加斯的直道、德州的乡村公路,都属于“长时间匀速驾驶”的场景,会被归为另一类。
分好堆还不够,同一堆里也有好坏之分。MOSAIC会给每个数据样本打个“重要性分数”:用当前模型跑一遍这个样本,看它能给综合驾驶评分(比如不撞车、守交规、坐得舒服这些指标的总分)带来多少提升。提升多的就是“优等生”,优先选进训练集。
但真实的聚类比这个类比更精确:它用的是无监督学习算法,通过分析数据的特征空间,自动找出相似度最高的样本组,不需要人工定义“复杂转向”或者“匀速驾驶”这些标签。
如果说聚类是“分帮派”,那缩放定律就是MOSAIC的“算账工具”。这个概念原本在大语言模型领域火——简单说就是,模型性能随数据量增长的规律是可预测的,就像你给手机充电,前10分钟能充50%,后面10分钟可能只能充20%,边际收益会递减。
MOSAIC给每个数据聚类单独拟合一条缩放曲线:先做几次小规模的“试点训练”,比如从“复杂转向”聚类里取100、200、400个数据,看模型的综合评分分别涨了多少,然后用这些数据拟合出一条饱和曲线。这条曲线能预测:再从这个聚类里加100个数据,能多涨多少分?什么时候再加数据就不划算?
有了这条曲线,MOSAIC就像拿着一张“数据性价比地图”:先采那些加一点数据就能涨很多分的“富矿”,比如波士顿的环岛;等这些“富矿”的边际收益降下来,再去采那些涨分慢但稳定的“贫矿”,比如德州的乡村公路;最后实在没矿采了,才去碰那些涨分微乎其微的“废矿”,比如拉斯维加斯的直道。
这个过程是动态迭代的:每采一批数据,就重新计算一次各聚类的边际收益,然后调整下一批的采样本。直到把预算花光,最后选出的数据集,就是在给定预算下能让模型性能最大化的最优组合。
当然,MOSAIC也不是万能的。它的效果高度依赖初始聚类的质量——如果把“复杂转向”和“匀速驾驶”的数据混在一个聚类里,那拟合出的缩放曲线就会完全失准,后续的选择也就全错了。而且,拟合每个聚类的缩放曲线需要做多次试点训练,这本身也要消耗算力,虽然比起全量训练的成本来说九牛一毛,但对于超大规模的模型和数据集,这笔开销也不能完全忽略。
更值得关注的是,MOSAIC的思路其实跳出了“靠更大模型、更多数据提升性能”的惯性思维,转向了“用更聪明的方法利用现有数据”。这在AI训练成本越来越高的今天,可能是比研发新模型更务实的方向。它的框架是通用的,不仅能用于自动驾驶,还能迁移到机器人、医疗影像分析等任何“数据多到用不完、算力却不够”的领域。
实验数据也证明了这一点:在OpenScene数据集上,MOSAIC只用随机采样15%的数据,就达到了后者用全量数据训练的效果;在Navtrain数据集上,数据效率提升也高达70%。而且它不是在某一个指标上刷分,而是能平衡提升所有驾驶指标——比如发现模型在“碰撞避免”上得分低,就优先采能提升这个指标的数据。
当我们还在惊叹大模型参数突破万亿的时候,MOSAIC悄悄给AI训练踩了一脚“刹车”:不是数据越多越好,而是有用的数据越多越好。它就像一个精明的投资人,不会把钱撒在每一个项目上,而是把钱投给那些回报率最高的项目,直到预算花完。
“数据的价值不在多,而在精准。”这句话放在今天的AI领域,比任何时候都更有分量。未来的AI训练,可能不再是比谁的数据更多、模型更大,而是比谁能更聪明地利用数据——毕竟,算力和数据的成本不会无限下降,但人类的智慧可以无限提升。