对抗知识焦虑,从看懂这条开始
App 下载
AI修复短视频野生废片,不止是变清晰
NTIRE挑战赛|扩散模型|生成式AI|短视频修复|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载NTIRE挑战赛|扩散模型|生成式AI|短视频修复|AIGC|人工智能
你有没有过这种时刻:翻到三年前用旧手机拍的聚会视频,画面糊成马赛克,人物边缘飘着压缩的方块,镜头抖得让人头晕——明明是珍贵的回忆,却连脸都认不清。过去我们只能叹口气划走,但现在,AI能把这些被设备、光线和平台压缩联手毁掉的「野生废片」,拉回清晰的世界。NTIRE 2026的一场挑战赛,让12支顶尖团队用生成式AI正面PK,结果不仅刷新了修复的上限,还戳破了一个行业误区:好的修复,从来不是「还原像素」那么简单。
你可以把传统视频修复算法想象成专科医生——去噪的不会修抖,去模糊的搞不定压缩伪影。但用户拍的短视频,从来都是「并发症」:在昏暗的餐馆举着手机拍生日歌,手抖+弱光+平台三次压缩,最后出来的视频连蜡烛火焰都像块融化的黄油。
扩散模型的出现,相当于来了个全科医生。它的逻辑很反直觉:先把清晰的视频逐步「加噪」变成模糊的废片,让模型记住这个退化的全过程,修复时再倒着走一遍——从满是噪声的废片里,一步步「还原」出合理的细节。这个过程不需要提前预设「是什么导致了模糊」,模型能自己从数据里学会应对各种复杂的「野生退化」。
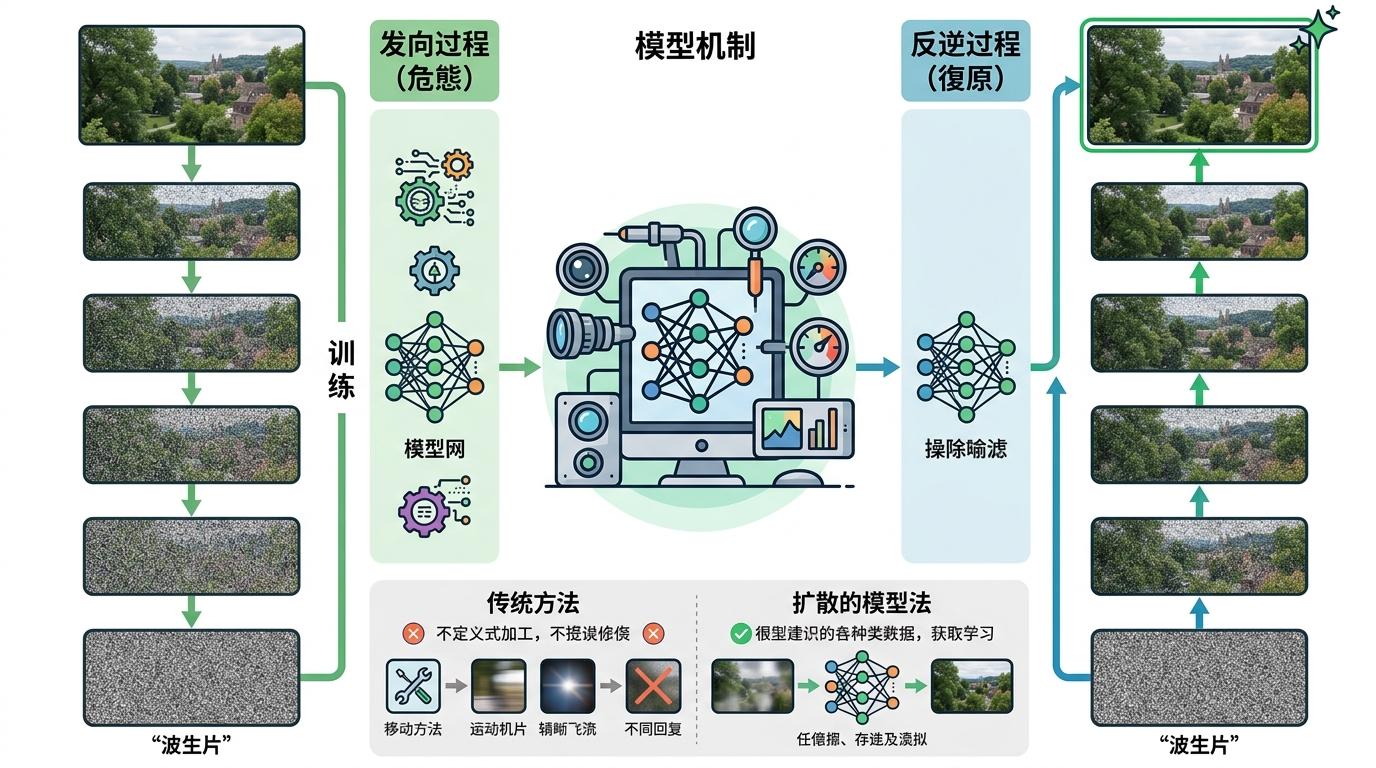
更关键的是,它不是在「补像素」,而是在「补逻辑」。比如修复一张糊掉的人脸,它会根据眼睛、鼻子的位置,推理出嘴巴的合理形状,而不是简单把模糊的色块磨平。这也是为什么扩散模型修复的视频,看起来不仅清晰,还「自然」——它符合我们对真实世界的认知逻辑。
这场挑战赛最聪明的地方,是用两套标准给AI打分:一套是客观指标,比如PSNR(峰值信噪比),比的是修复后的视频和原始高清视频的像素接近度;另一套是主观评分,让专业评委从「像不像真的」「看着舒服不舒服」「画面连贯不连贯」三个维度打分。
结果不出意料地出现了分化:有个团队的客观指标排第二,WarpError(衡量帧间抖动的指标)低到0.0549,意味着视频流畅得像专业设备拍的,但主观评分只排第八——因为它为了追求像素还原,把画面修得太平滑,人像像塑料假人;而主观评分第四的团队,客观指标排第七,因为它给糊掉的夜景「脑补」了路灯的光晕,虽然和原始视频的像素对不上,但人眼觉得「这才是夜晚该有的样子」。
最终夺冠的RedMediaTech团队,是唯一在两条赛道都拿第一的。他们的秘诀是「两步走」:先用Wan 2.1的扩散模型保证画面的「好看」,再换用表达能力更强的Qwen-Image VAE提升像素还原度;同时用3D旋转位置编码把视频的帧和帧「粘」在一起,解决了扩散模型容易出现的帧间闪烁问题。
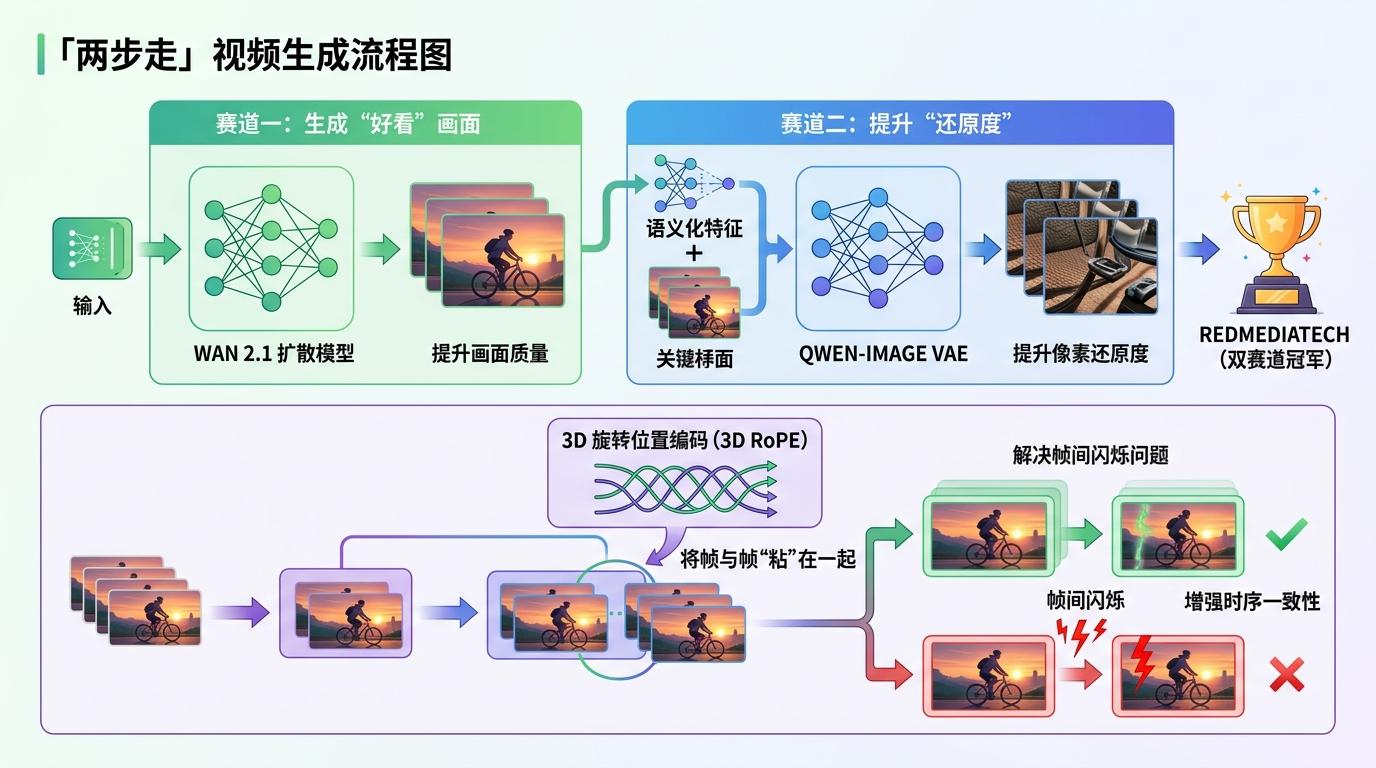
更值得关注的是,他们偷偷加了「外挂」——用1万个高清视频片段做额外训练,比官方给的数据集大得多。这说明在AI修复领域,数据的量级和多样性,依然是比模型架构更核心的竞争力。
现在你肯定想问:这么厉害的技术,什么时候能装到我的手机里?答案是:快了,但还得闯三道关。
第一关是「瘦身」。夺冠的模型用8张H20 GPU跑了好几天才训练好,推理一个9帧的1080p片段要224秒,手机的算力连它的零头都不到。现在研究者们正在用「知识蒸馏」把大模型的能力压缩到小模型里,或者用「单步扩散」把几十步的修复过程压缩到一步——就像把一本厚书浓缩成一张思维导图,虽然细节少了,但核心逻辑还在。
第二关是「管住AI的脑洞」。扩散模型有时候会「脑补」出不存在的细节,比如给糊掉的照片里的人加个眼镜,或者把背景里的树修成路灯。现在的解决办法是给模型加「缰绳」,比如用低质量的视频流作为「结构提示」,让AI只在已有信息的基础上修复,而不是凭空创造。
第三关是「找到真正的用户需求」。用户要的不是「像素级还原」,而是「能看清回忆里的脸」「视频不抖得头晕」「颜色像当时看到的一样鲜艳」。未来的修复算法,可能会让你自己选:是要「完全真实」,还是「好看优先」,甚至可以一键「复古滤镜修复」,把旧视频修成80年代电影的质感。
当我们讨论AI修复短视频时,我们其实在讨论的是「记忆的清晰度」。那些模糊的、抖动的、满是压缩方块的视频,不是没用的垃圾,是我们用手机随手定格的生活碎片:第一次带爸妈吃火锅的晚上,毕业照里挤成一团的脸,孩子学会走路的瞬间。
AI修复的不是视频,是让这些快要褪色的记忆,重新变得鲜活。技术的终极意义,从来都是服务于人对「好」的感知。也许不用太久,我们打开手机里的旧视频,点一下「修复」按钮,那些模糊的脸会重新清晰,抖动的画面会变得平稳,就像我们又回到了那个瞬间。