对抗知识焦虑,从看懂这条开始
App 下载
AI学会脑补遮挡物,视觉感知迈过关键坎
遮挡物体还原|空间补全适配器|腾讯AI Lab|哈工大|Amodal SAM|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载遮挡物体还原|空间补全适配器|腾讯AI Lab|哈工大|Amodal SAM|多模态视觉|人工智能
当你看到半个人躲在墙后,大脑会自动补出他完整的身形——这种“脑补”能力,曾是AI视觉的天堑。过去的图像分割模型只能处理物体的可见部分,被遮挡的区域对它们来说就是“盲区”,换个没见过的场景更是直接失效。直到哈工大、腾讯AI Lab等团队推出的Amodal SAM出现:它给Meta的“分割一切”大模型装上了“透视眼”,能精准还原被遮挡物体的完整轮廓,在多个数据集上把遮挡区域的分割精度从30%左右拉到了60%以上。更关键的是,它能在完全陌生的场景里做到这一切。这背后的技术,到底是怎么让AI学会“想象”的?
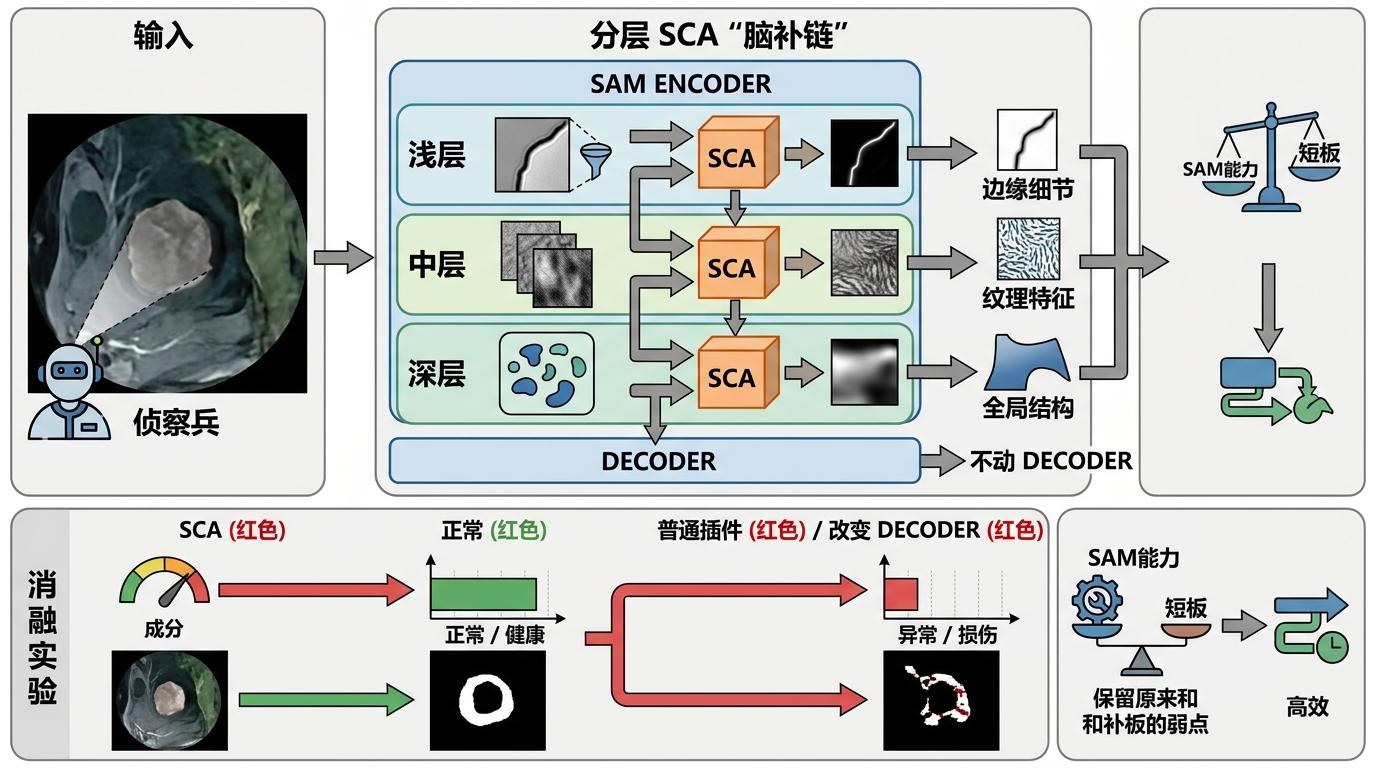
你可以把SAM的编码器想象成一个负责“看细节”的侦察兵,解码器是负责“画全貌”的画师——画师本身已经能把看见的部分画得极好,但一旦遇到遮挡,侦察兵没传回信息,画师就只能停笔。
空间补全适配器(SCA)就是给侦察兵加的“补全雷达”。它不像传统插件那样硬塞信息,而是用了一种类似“智能开关”的门控卷积机制:先把图像特征和一个粗略的目标范围框拼在一起,再分成两路处理——一路生成0到1之间的“门控权重”,另一路负责转换特征。被遮挡的区域权重接近1,模块就重点补全这里的特征;可见区域权重接近0,就保留原始信息。
但真实的机制比这更精确:研究者把SCA分别插在SAM编码器的浅、中、深三层,浅层补边缘细节,中层补纹理特征,深层补全局结构,形成一个分层的“脑补链”。消融实验显示,如果把SCA换成普通插件,或者同时改动解码器,遮挡区域的分割精度会直接下降20%以上——这证明了“只改侦察兵,不动画师”的策略,既保留了SAM原有的能力,又精准补上了它的短板。
光有雷达还不够,侦察兵得先见过足够多的遮挡场景,才能学会补全。但人工标注被遮挡物体的完整轮廓,成本是普通图像标注的3倍以上,现有数据集的规模根本喂不饱大模型。
研究者想出的办法是“用AI造题”——目标感知遮挡合成(TAOS)就像一个自动出题的老师,能把SAM训练用的SA-1B数据集(1100万张图,11亿个分割标注)直接转换成带遮挡的训练样本。它的流程简单又高效:先随机选一个目标物体,再从另一张图里切个大小匹配的物体当遮挡物,盖在目标上后用高斯模糊处理接缝,让遮挡看起来更自然。最后用视觉语言模型筛选掉那些明显不合理的合成图,比如把飞机盖在茶杯上这种违背常识的组合。
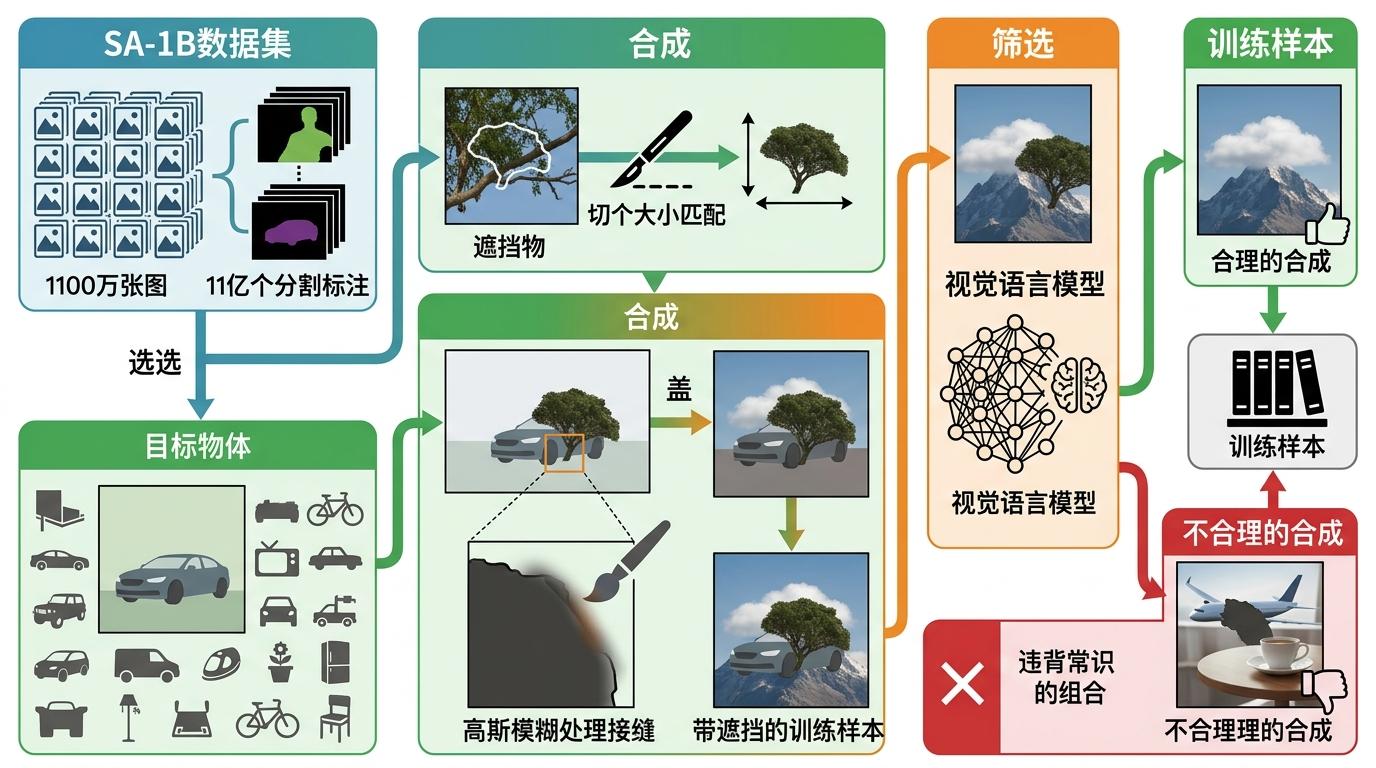
这套流程能自动生成海量多样化的遮挡场景,从简单的部分遮挡到复杂的多层叠加都能覆盖。实验显示,只用合成数据训练的模型,在真实场景中的表现已经接近用真实标注数据训练的模型;如果把合成数据和真实数据混合,遮挡区域的分割精度还能再提10%。
就算能补全特征,AI也可能补出违背常识的形状——比如把被墙挡住的人补成飘在空中的半截身体。为了避免这种情况,研究者给模型加了两道“逻辑枷锁”。
第一道是区域一致性损失:它要求模型对同一个物体的可见部分和被遮挡部分,提取的特征必须相似。就像一个人的胳膊和被挡住的腿,肤色、纹理得保持一致,不能把腿补成另一种颜色。第二道是整体拓扑正则化:他们引入了一个判别器,专门判断模型补出的轮廓是不是“合理的形状”——如果补出的人形有三条腿,判别器就会打低分,逼着模型调整。
消融实验验证了这两道枷锁的必要性:去掉任何一个,遮挡区域的分割精度都会下降5%以上。更重要的是,这些优化没有破坏SAM原有的“零样本”能力——Amodal SAM在完全没见过的物体和场景里,依然能准确补全遮挡区域,而传统模型在这种情况下的精度会直接跌到个位数。
当然,Amodal SAM也有局限:它的合成数据和真实场景还有差距,遇到极端复杂的多层遮挡时,补全的精度会明显下降;而且它的计算量比原始SAM大,暂时还没法在边缘设备上实时运行。
从只能“看见”到学会“想象”,Amodal SAM的突破,本质上是让AI从“识别像素”走向了“理解逻辑”。它没有从零开始造一个新模型,而是在现有大模型的基础上,用精准的插件、高效的数据和合理的优化,补上了人类视觉最基础的能力之一。
这也给AI研究提了个醒:与其盲目追求更大的模型,不如盯着人类的基本能力,给大模型做“精准的加法”。AI的进化,从来不是从零创造,而是补全缺失的拼图。未来,当AI能像人类一样,通过碎片信息还原完整的世界,自动驾驶、机器人抓取、增强现实这些领域,才能真正走进我们的生活。