对抗知识焦虑,从看懂这条开始
App 下载
1970年代老机器跑通Transformer,算力不是关键
序列反转任务|自注意力机制|汇编实现|PDP-11小型机|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载序列反转任务|自注意力机制|汇编实现|PDP-11小型机|大语言模型|人工智能
想象一下:没有GPU,没有浮点运算单元,连编程语言都只有最原始的汇编——在1970年代的PDP-11小型机上,能训练出Transformer吗?
答案是能。开发者用纯汇编写出了一个只有1216个参数的单层单头Transformer,让这台主频6MHz、内存仅32KB的老机器完成了「序列反转」任务:输入一串数字,它能准确输出倒序结果,而且不能靠死记硬背,必须理解每个数字的位置映射关系——这正是Transformer核心的自注意力机制要解决的问题。更惊人的是,它只花了5分钟、350步训练就达到了100%准确率。
为什么一台半个世纪前的老机器,能完成我们默认需要顶级算力的任务?
要在没有浮点单元的PDP-11上跑通Transformer,核心是把复杂的自注意力机制,拆解成老机器能执行的整数运算。你可以把自注意力想象成「给句子里的每个词找亲戚」:输入序列里的每个数字,都会生成三个身份——查询(Q)、键(K)、值(V)。查询是「我要找什么」,键是「我是什么」,值是「我能提供什么」。通过计算查询和所有键的相似度,模型就能知道该关注哪些位置的信息,最终把对应的值整合起来,完成位置映射。
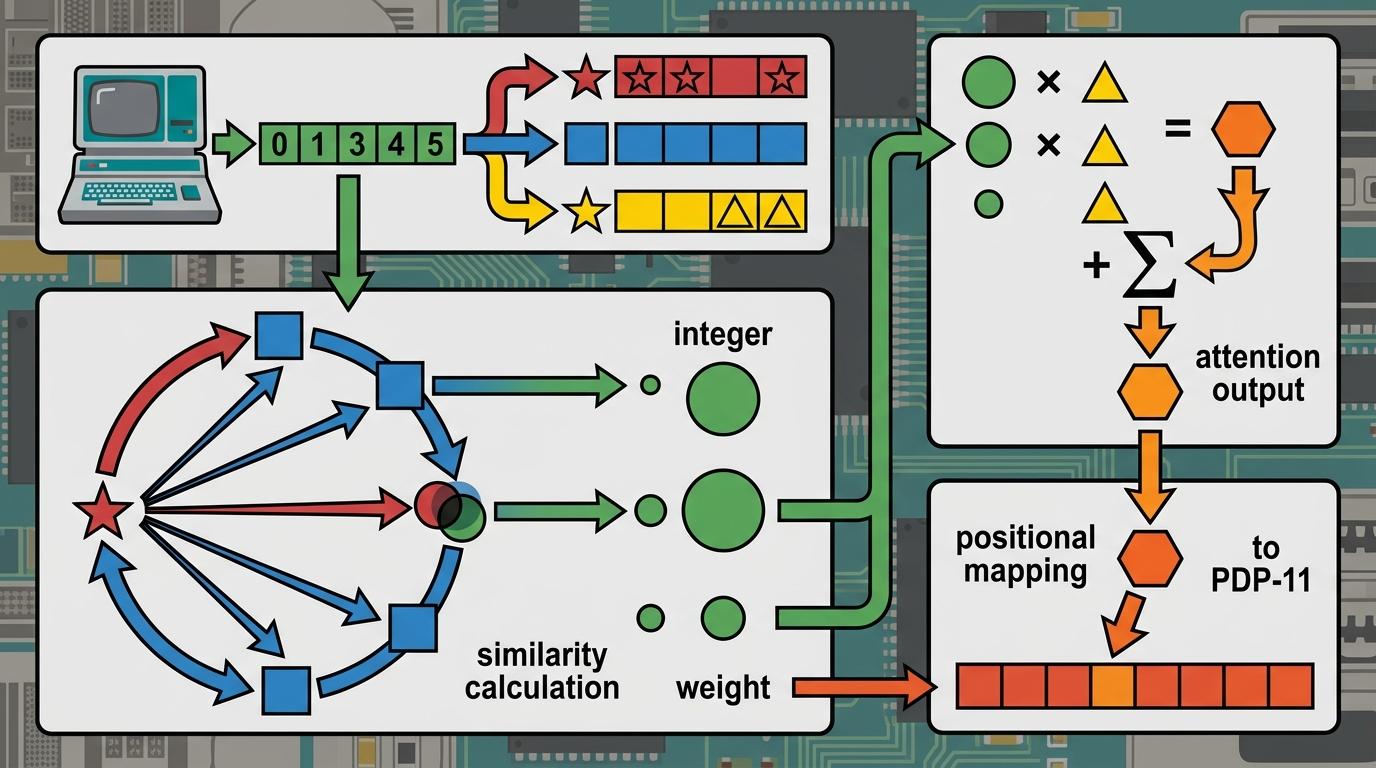
但真实的机制比这个类比更精确:自注意力的核心是计算Q和K的点积得分,再通过Softmax转换成概率权重,最后加权求和V向量。在PDP-11上,这意味着所有浮点运算都要替换成定点数——用整数模拟小数,通过位移操作替代除法;而指数、对数这类「超越函数」,则直接用提前算好的查找表代替,一次查表只需要一条MOV指令,比任何实时计算都高效。
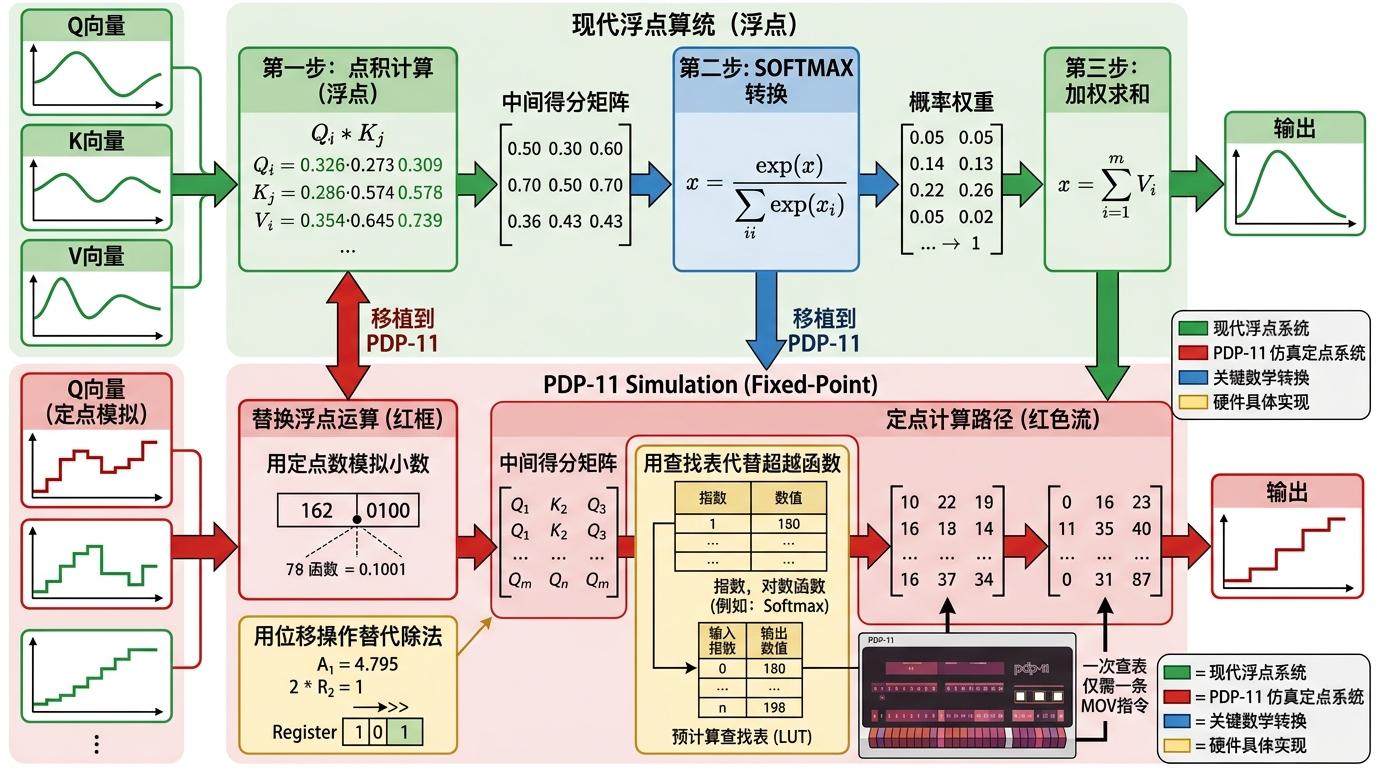
开发者还做了最极致的减法:去掉了层归一化和前馈网络,只用残差连接维持训练稳定;放弃了Adam这类复杂优化器,手动给不同层设置不同学习率——编码位置映射的注意力层用高学习率快速收敛,输出层用低学习率避免震荡。最终整个模型连代码带参数,只占了19.2KB内存,比很多现代图片还小。
这个实验最戳人的地方,不是老机器能跑Transformer,而是它戳破了一个行业默认的「常识」:大模型的发展必须靠堆参数、堆算力。
有网友翻出了更惊人的历史数据:1984年的Cray X-MP超级计算机,算力已经能达到每秒10亿次浮点运算,配上1GB存储,半年就能训练出千万参数的语言模型;1990年代中期的Cray T3E,甚至能承载GPT-2规模的模型——比OpenAI早了24年。而早在1965年,就有人用打孔卡计算机通过反向传播学会了异或运算。
我们总以为是硬件限制了AI的发展,但事实是,很多时候是我们的思路限制了硬件的潜力。就像这次实验里,开发者没有纠结「老机器能不能跑」,而是先问「Transformer的核心到底是什么」——是自注意力对位置关系的建模能力,不是几十层的网络、上万亿的参数。当把冗余的部分全部砍掉,剩下的核心逻辑,连半个世纪前的老机器都能承载。
当然,这不是说现代大模型的算力投入没有意义——大规模参数能处理更复杂的任务,比如理解长文本、生成多模态内容。但这个实验提醒我们:当我们在追求更大、更快的时候,不要忘了AI最本质的东西——用算法解决问题的思路。
这个穿越时空的实验,不止是怀旧,更是给当下的AI发展提了个醒:在边缘计算、物联网这些资源受限的场景里,我们需要的不是缩小版的大模型,而是像ATNN-11这样,从硬件特性出发重新设计的AI。
现在已经有很多类似的尝试:比如把Transformer的自注意力改成稀疏模式,只计算关键位置的相似度,把复杂度从序列长度的平方降到线性;或者用知识蒸馏,让小模型学习大模型的注意力分布,而不是只模仿输出;还有的团队直接在硬件层面做优化,把Transformer的计算逻辑做成专用电路,让边缘设备能以毫瓦级的功耗运行AI。
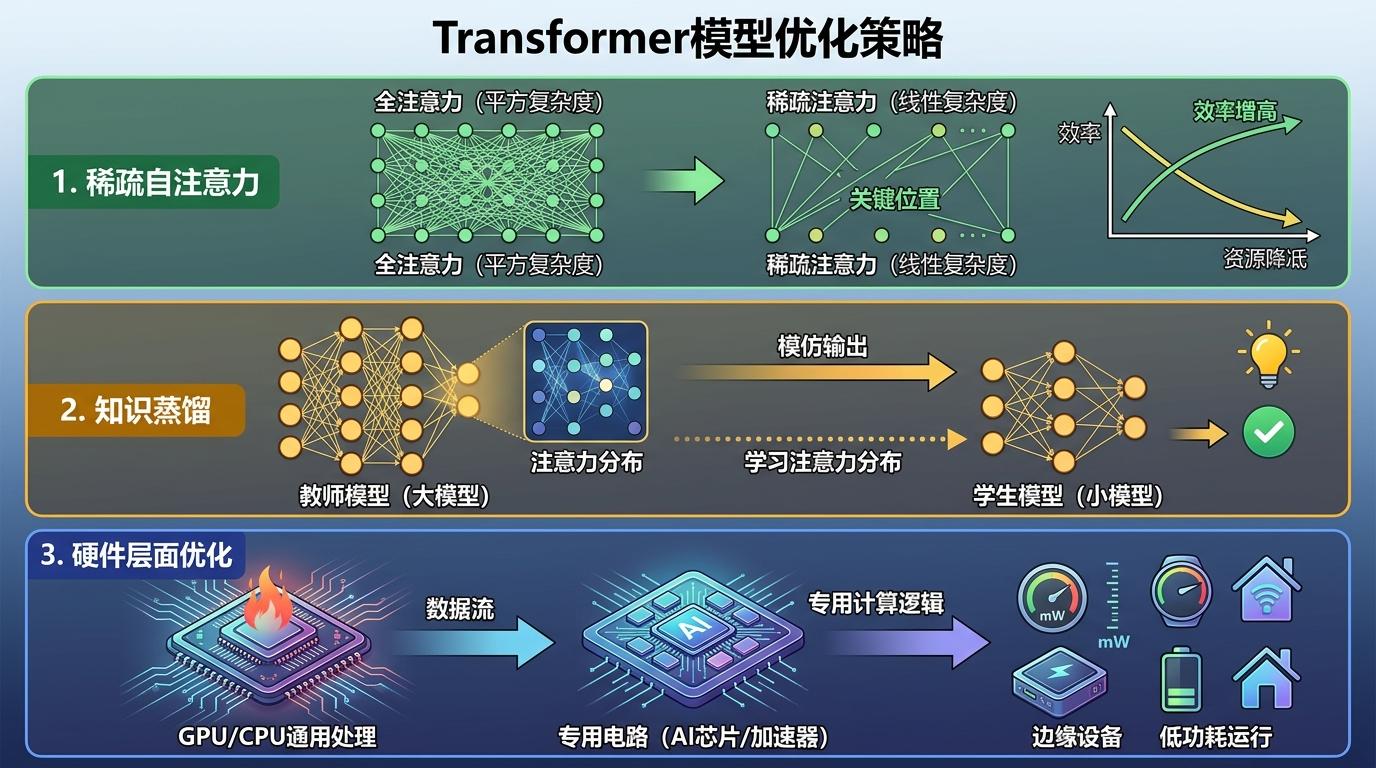
这些思路和ATNN-11的本质是一样的:不是让算法适应硬件,而是让算法和硬件协同工作。就像PDP-11上的汇编代码,每一条指令都在榨干老机器的最后一点性能——未来的AI,或许会有更多这样「刚刚好」的设计,而不是一味追求「更大更强」。
当那台1970年代的老机器吐出正确的倒序数字时,它其实在说:AI的本质从来不是算力的竞赛,而是思路的突破。
我们总习惯用「时代局限性」来解释过去的技术,但这次实验告诉我们,很多时候,局限的不是时代,而是我们对技术的想象。就像打孔纸带上的孔,每一个都简单到极致,但排列组合起来,就能承载最先进的AI逻辑。
算力是燃料,但思路才是引擎——这或许是半个世纪前的老机器,给当下AI行业最珍贵的启示。