对抗知识焦虑,从看懂这条开始
App 下载
剪半AI模型参数,自动驾驶通信反而更稳了
车载终端|低信噪比|参数剪枝|V2V通信|自动驾驶|人工智能
对抗知识焦虑,从看懂这条开始
App 下载车载终端|低信噪比|参数剪枝|V2V通信|自动驾驶|人工智能
你开着自动驾驶车钻进隧道,前方大卡车突然急刹——但你的车没看到,因为摄像头被黑暗糊成了马赛克。这不是科幻片里的灾难场景,而是自动驾驶V2V通信的真实死穴:隧道、高架桥下的低信噪比环境里,传统通信会直接“罢工”,连带着车辆感知系统彻底失明。但2026年的一项新研究,把负责V2V通信的AI模型剪掉一半参数后,居然在1dB的极低信噪比下,还能清晰还原前方路况。这不是反常识,而是给自动驾驶装了个“抗造”的神经中枢。
你可以把自动驾驶的V2V通信模型想象成一个背着几十斤装备跑马拉松的运动员——车载终端的算力就是他的体能,冗余参数就是那些用不上的装备。以前的“瘦身”方法要么是乱砍一通(非结构化剪枝),结果模型变残废,得靠特殊硬件才能动;要么是均匀“饿肚子”(压缩带宽),把有用的信息也给挤没了。
这次研究用的结构化剪枝,更像专业教练的精准减脂:先通过批归一化层里的缩放因子γ,给每个卷积通道做“体检”——γ越小,说明这个通道对图像重建的贡献越小,属于“无效赘肉”。然后在训练时加L1正则化,像给赘肉上了“紧箍咒”,让没用的通道自动萎缩。最后一刀剪掉50%的冗余通道,再用数据微调补营养。
结果相当惊人:模型参数从6.25M降到4.02M,计算量砍掉10%,但图像重建的PSNR只从31.42dB微降到30.99dB,人眼几乎看不出差别。更关键的是,剪枝后的模型不用特殊硬件,普通车载芯片就能跑。
解决了模型“装得下”的问题,下一个难题是“传得出去”。以前的语义通信喜欢用模拟传输,就像直接喊着传话,虽然信息全,但和现在的4G/5G数字网络不兼容,相当于拿着对讲机插手机卡。要是强行转数字传输,量化误差会和信道噪声叠加,低信噪比下直接变成“杂音”。
研究团队搞了个“训练-部署分离”的巧招:训练时不让模型接触量化模块,只让它习惯带噪声的输入——就像让运动员在充满干扰的训练场练跑步,等他适应了,再让他去正式赛场。部署时再加入量化调制,把AI输出的连续值映射到256QAM这样的数字星座点上,完美对接现有数字网络。
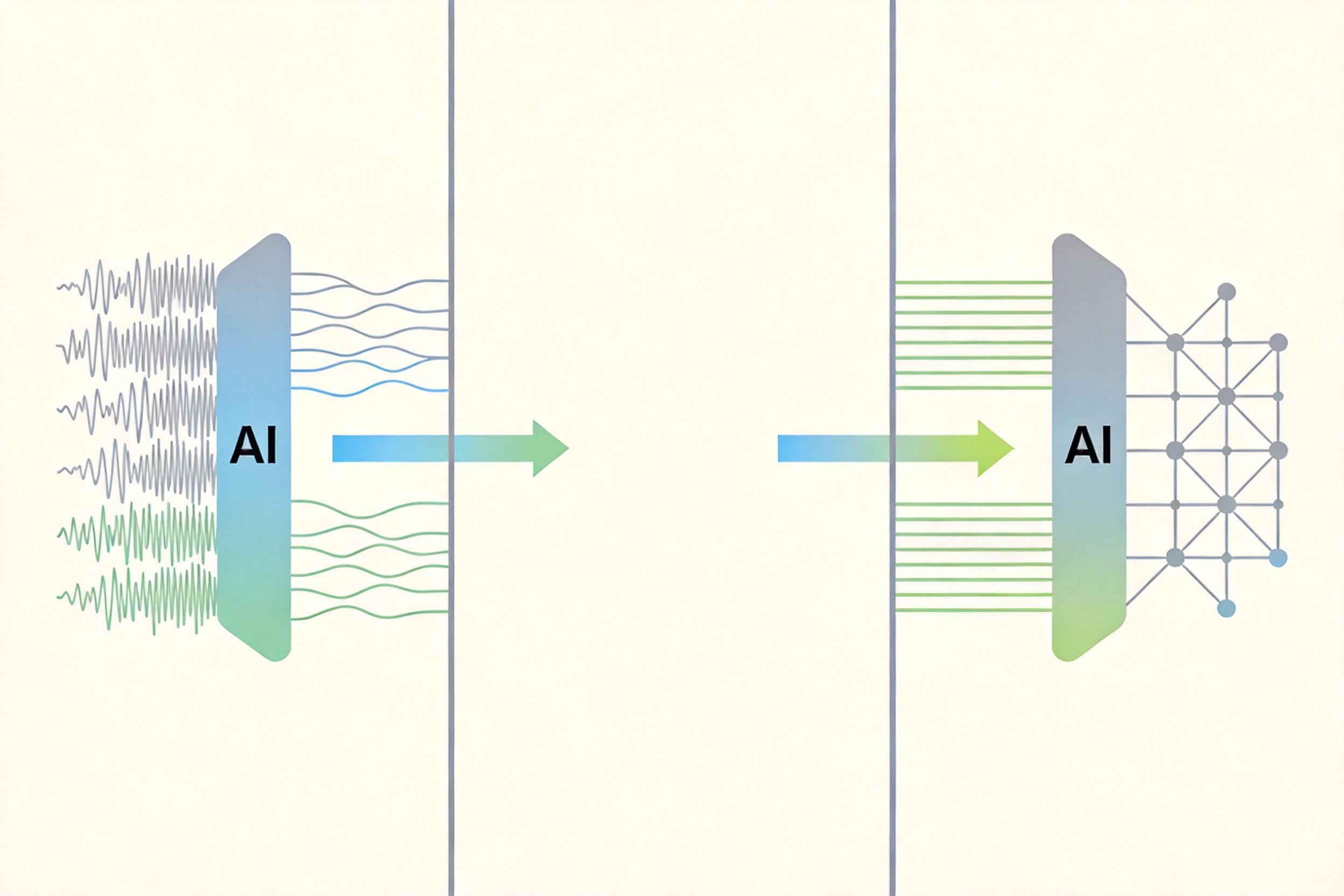
没想到这还带来了意外收获:数字传输的硬判决能过滤掉模拟传输里的小幅噪声,低信噪比下的图像反而更干净。在1dB的极端低信噪比下,传统BPG编码方案的图像已经糊成了马赛克,而这个方案还能还原出清晰的车辆和道路轮廓,PSNR能到27.76dB,SSIM高达0.90。

当然,这个方案也不是万能的。在高信噪比环境下(>14.5dB),它的PSNR不如传统的BPG-LDPC方案——毕竟传统方案在信道好的时候,能把图像压缩得更精细。而且目前它只在Cityscapes的固定尺寸图像上做了测试,要是换成不同分辨率的图像,或者复杂的雨雾天气,性能会不会打折扣还不好说。
更重要的是,它还没经过真实车载硬件的考验。实验室里的仿真环境和真实道路的无线信道差远了——真实环境里有多径衰落、信号遮挡,还有其他车辆的通信干扰。而且自动驾驶需要的不只是静态图像,还有实时视频流,这套方案能不能处理高速变化的视频数据,也是个未知数。
不过这些问题反而让它更有价值:它不是一个终极答案,而是给后续研究指了个方向——原来把模型轻量化和数字兼容性结合起来,能解决这么棘手的问题。
当我们谈论自动驾驶时,总喜欢盯着激光雷达、大模型这些“高大上”的技术,却常常忽略了V2V通信这种“看不见的基础”。就像建高楼,地基没打好,再华丽的顶层设计也没用。
这次研究最有意思的地方,不是它实现了多少技术突破,而是它用一种“务实”的思路,解决了一个“接地气”的问题——不是追求最先进的模型,而是让模型适应真实的硬件和网络环境。好技术不是做加法,而是做精准的减法。未来的自动驾驶,可能不需要最复杂的模型,但一定需要最“懂”车载终端和通信环境的模型。而这个研究,就是往这个方向走的重要一步。