对抗知识焦虑,从看懂这条开始
App 下载
AI作画内存瓶颈被攻克:旋转量化让模型瘦身4倍?
显存优化|AI绘画模型|旋转量化|Diffusion Transformer|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载显存优化|AI绘画模型|旋转量化|Diffusion Transformer|多模态视觉|人工智能
想象一位才华横溢的艺术家,他能创作出媲美伦勃朗光影、梵高色彩的杰作,但他的工作室却是一座耗电巨大的超级计算机中心,每一次挥动画笔都需要整个城市电网的支持。这正是当今顶级AI绘画模型——尤其是基于Diffusion Transformer(DiT)架构的模型——所面临的窘境。它们生成的图像质量令人惊叹,但其庞大的模型尺寸和惊人的计算需求,如同一座无形的墙,将无数创作者和普通用户挡在门外。一个几十亿参数的模型动辄需要上百GB的显存,这让大多数个人电脑甚至专业工作站都望而却步。如何让这位“艺术家”走出云端,进入寻常百姓家,成为了AI落地应用中最棘手的瓶颈之一。
为了打破这面“内存之墙”,科学家们开启了一场名为“模型量化”的瘦身革命。其核心思想很简单:用更少的“颜料”来描绘世界。在数字世界里,这意味着将模型中精确但臃肿的32位浮点数(FP32),压缩成更紧凑的8位甚至4位整数(INT8/INT4)。这就像将一张拥有1600万种颜色的高清照片,压缩成一张只有256色甚至16色的图片,文件大小急剧缩小。
然而,这场革命并非一帆风顺。粗暴的压缩会带来一个致命问题——“异常值”(Outliers)。在模型的数据中,总有那么一些数值极大或极小的“异类”,它们就像颜料盘上最极端、最刺眼的一抹亮色。在量化过程中,为了容纳这些极端值,整个“调色盘”的精度都会被拉伸,导致大部分正常数值的细节丢失,最终生成的图像质量严重下降。这正是低比特量化长期以来的核心难题。
为了驯服“异常值”这头猛兽,研究者们各显神通。早期的方法如SmoothQuant,像是一种巧妙的“乾坤大挪移”,它将激活值(动态数据流)中的异常值“转移”到权重(模型参数)中,通过牺牲一部分权重的精度来保全激活值的平滑,从而让量化过程更加顺畅。这一招在语言大模型上取得了不错的效果。
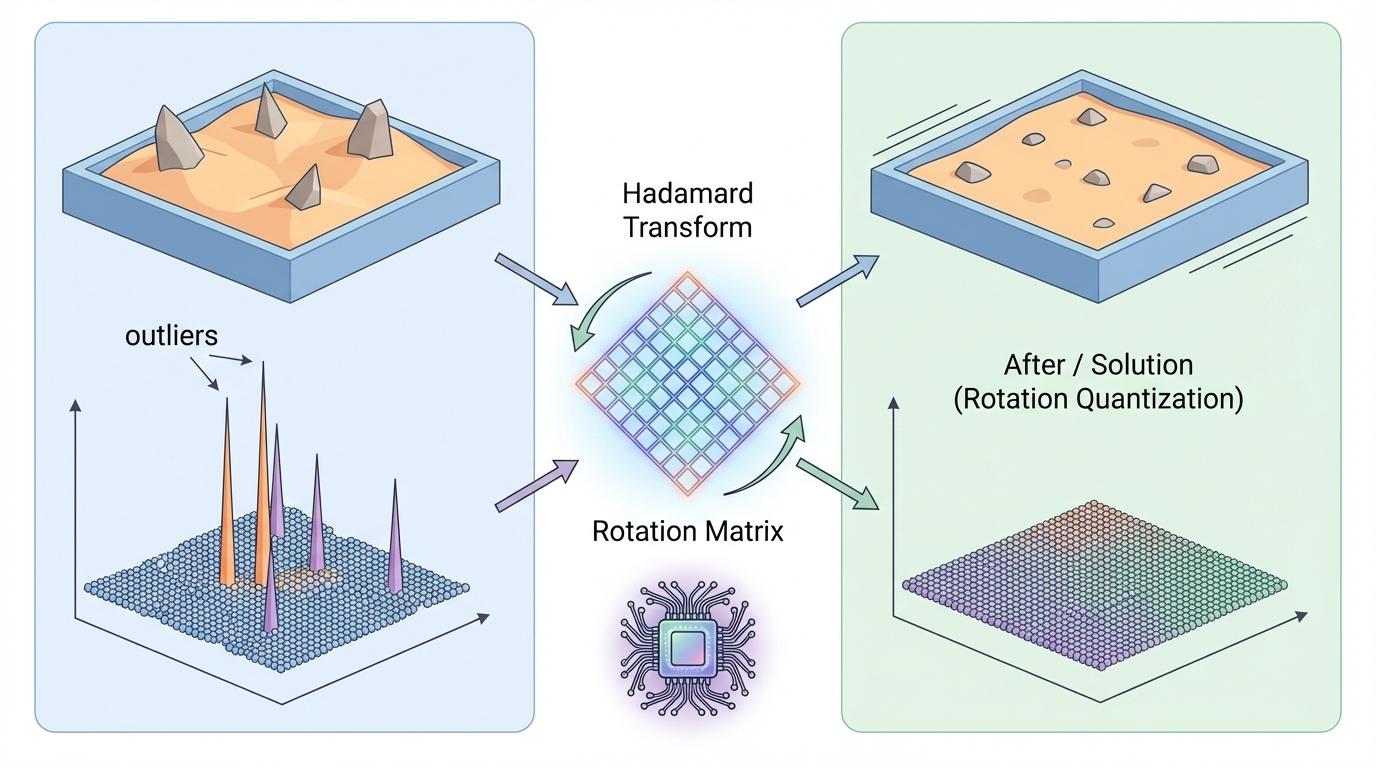
但对于结构更复杂的Diffusion Transformer,这还不够。于是,一种更激进的方案——**“旋转量化”**登上了舞台。其灵感来源于一个简单的物理直觉:如果一堆沙土中有几块突兀的石头,怎么办?摇晃沙盘,让石头混入沙土中,表面就平滑了。在数学上,研究者通过一个名为“Hadamard变换”的正交矩阵,对数据进行“旋转”,将异常值的能量均匀地分散到所有维度上,从而“抹平”这些尖峰。QuaRot等方法在语言模型上验证了这一思路,但它也带来了新的问题:全局旋转的计算开销是平方级的(O(K²)),对于DiT这样的大模型来说,这种“摇晃”本身的代价就难以承受。
正当旋转量化陷入“力大砖飞”的困境时,清华大学与华为的研究团队带来了全新的解法——ConvRot。他们意识到,也许我们不需要摇晃整个“沙盘”,而只需要在有“石头”的地方进行局部、精准的“抖动”。
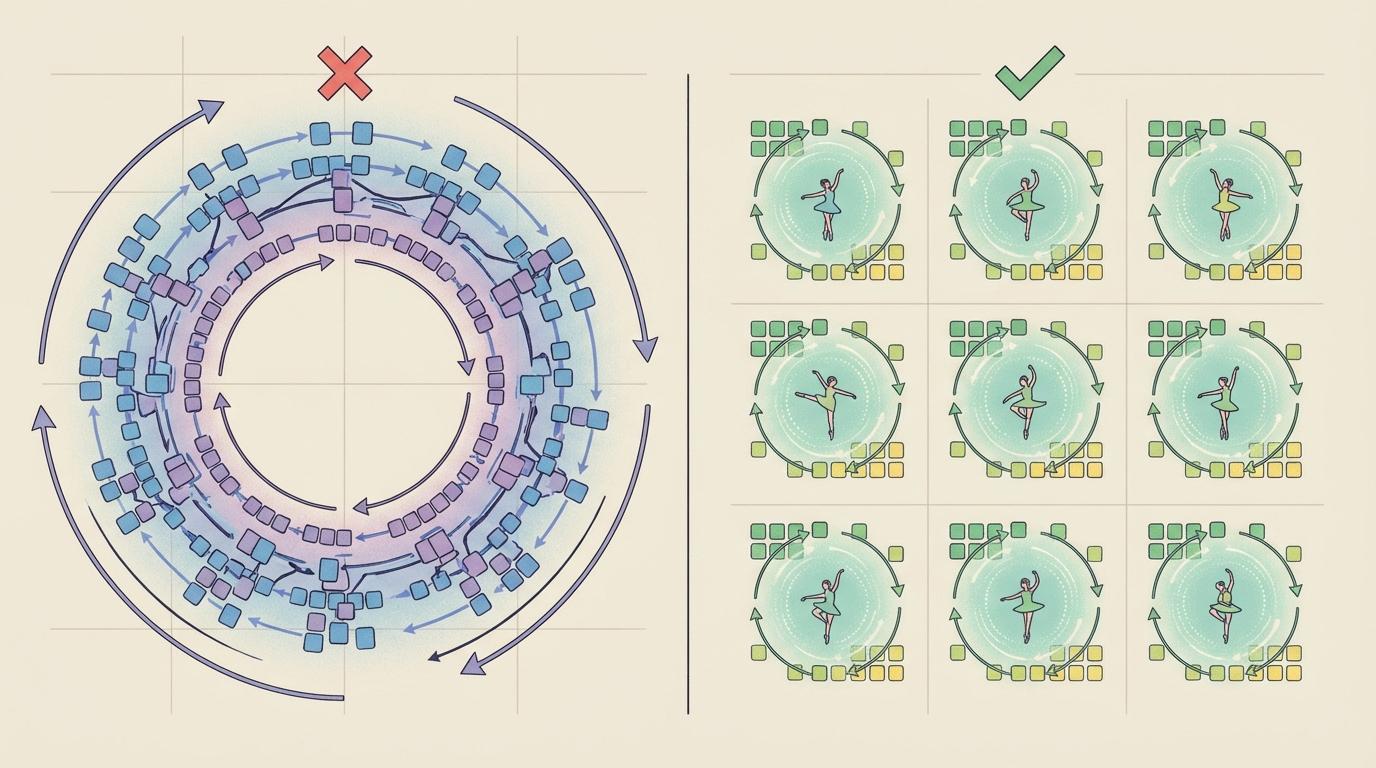
ConvRot的核心创新在于**“分组正则Hadamard旋转”**。它不再对所有数据进行全局旋转,而是将特征维度分成若干个小组,在每个小组内部独立进行旋转变换。这好比将一场耗费巨大的“广场舞”分解成无数场轻盈而高效的“局部芭蕾”。这一改变带来了三大好处:
如果说ConvRot是精妙的算法核心,那么ConvLinear4bit模块则是其走向实用的“临门一脚”。研究团队将旋转、量化、4比特矩阵乘法和反量化等一系列复杂操作,封装成一个即插即用的计算层。这意味着开发者无需重新训练动辄耗资百万的模型,只需像替换乐高积木一样,将原有模型中的线性层替换为ConvLinear4bit模块,就能立即享受到4比特量化带来的巨大优势。
在拥有120亿参数的顶级文生图模型FLUX.1-dev上的实验结果堪称惊艳:
更重要的是,这一切几乎没有牺牲图像质量。通过一种混合精度策略(将20%最敏感的层保持在INT8精度),量化后的模型在图像细节和全局一致性上,几乎与那些依赖额外16位高精度分支的复杂方法相媲美。
ConvRot的出现,首次将高效的旋转量化技术成功应用于Diffusion Transformer领域,为AI绘画模型的普及扫清了一大障碍。它不仅仅是一篇学术论文或一个算法,更是一把钥匙,解锁了被囚禁在云端超级计算机中的强大创造力。
这项突破意味着,未来,在你的个人电脑、甚至是笔记本上流畅运行顶级的AI绘画模型,将不再是奢望。艺术家、设计师和爱好者们将能以更低的成本、更高的效率,将想象力转化为现实。这场始于“瘦身”的技术革命,最终通向的,是一个更加普惠和充满无限可能的创意新纪元。这位才华横溢的“AI艺术家”,终于可以走出昂贵的“工作室”,将画板带到世界的每一个角落。