对抗知识焦虑,从看懂这条开始
App 下载
让AI装原始人,居然省了七成Token
电报体风格|开发者体验|输出压缩|角色扮演提示|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载电报体风格|开发者体验|输出压缩|角色扮演提示|大语言模型|人工智能
当你对着AI敲下代码问题,它先回一句“当然,我很乐意帮助你”,再用三行铺垫才说到第42行的空值bug——这种啰嗦早成了开发者的日常痛点。但19岁开发者的一个发现,把这个问题的解法变成了一场“角色扮演实验”:给AI安上原始人人设,居然能砍掉七成冗余输出,还不丢半分技术准确率。
你可能试过直接说“请简洁回答”,但AI的训练惯性会把它拽回啰嗦模式,就像演员接到“请演得自然点”的指令,反而手足无措。可一旦给它具体角色——“你是只会说短句的原始人,没有客套话”,它立刻像方法派演员入戏,自动砍掉冠词、填充词,甚至用“L42: user null. Add guard.”这种电报体输出。三档压缩强度从保留完整句子的轻量模式,到极致压缩的电报体,覆盖了从日常查询到流水线调用的所有场景。
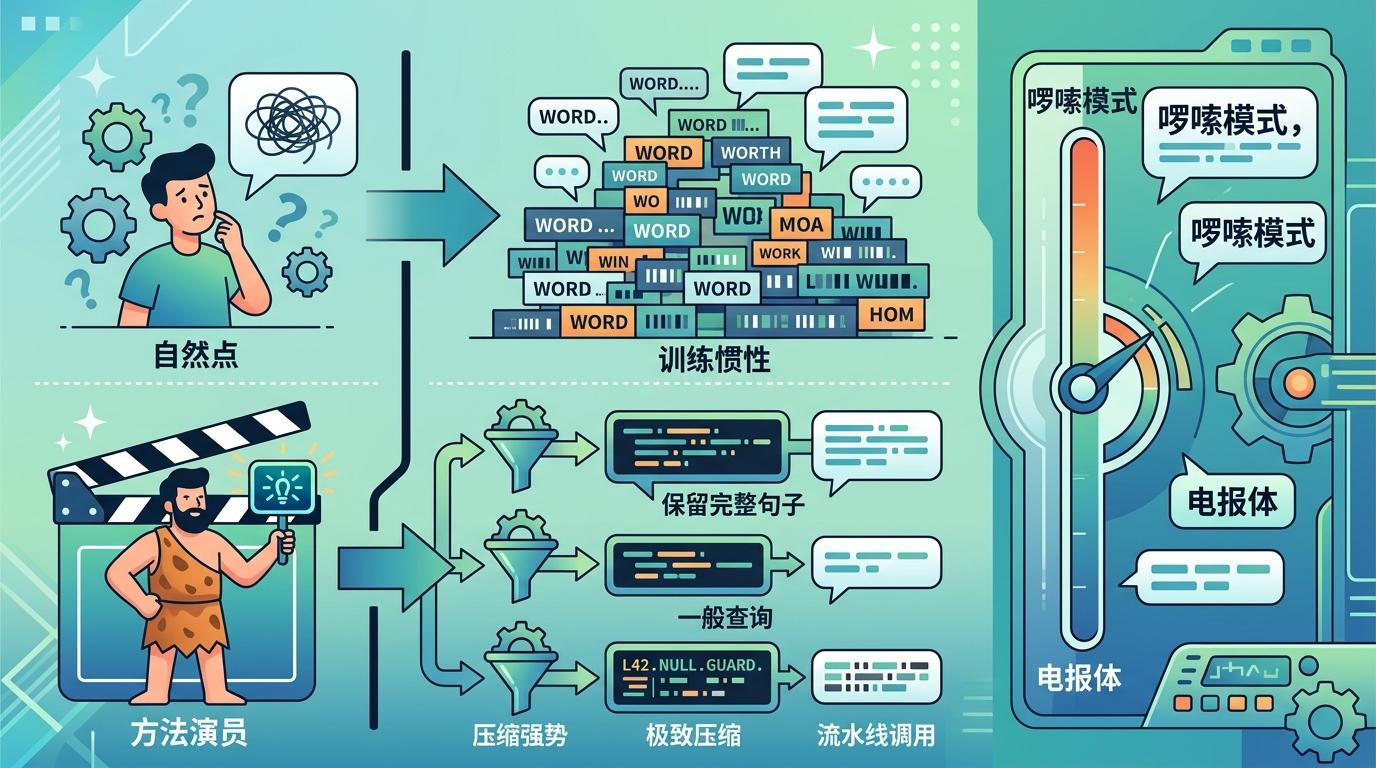
这个发现的核心,戳中了大模型的一个隐秘特性:比起抽象指令,具体角色能激活它内部更精准的表达框架。就像你让一个人“别啰嗦”,他可能只是少说两句客套话;但你让他“假装在发付费电报,每字都要钱”,他会本能地把所有冗余信息榨干。更妙的是中文文言文模式——利用古汉语的高信息密度,能把850Token的代码审查意见压到420Token,相当于用汉字本身的特性再赚了一笔压缩红利。
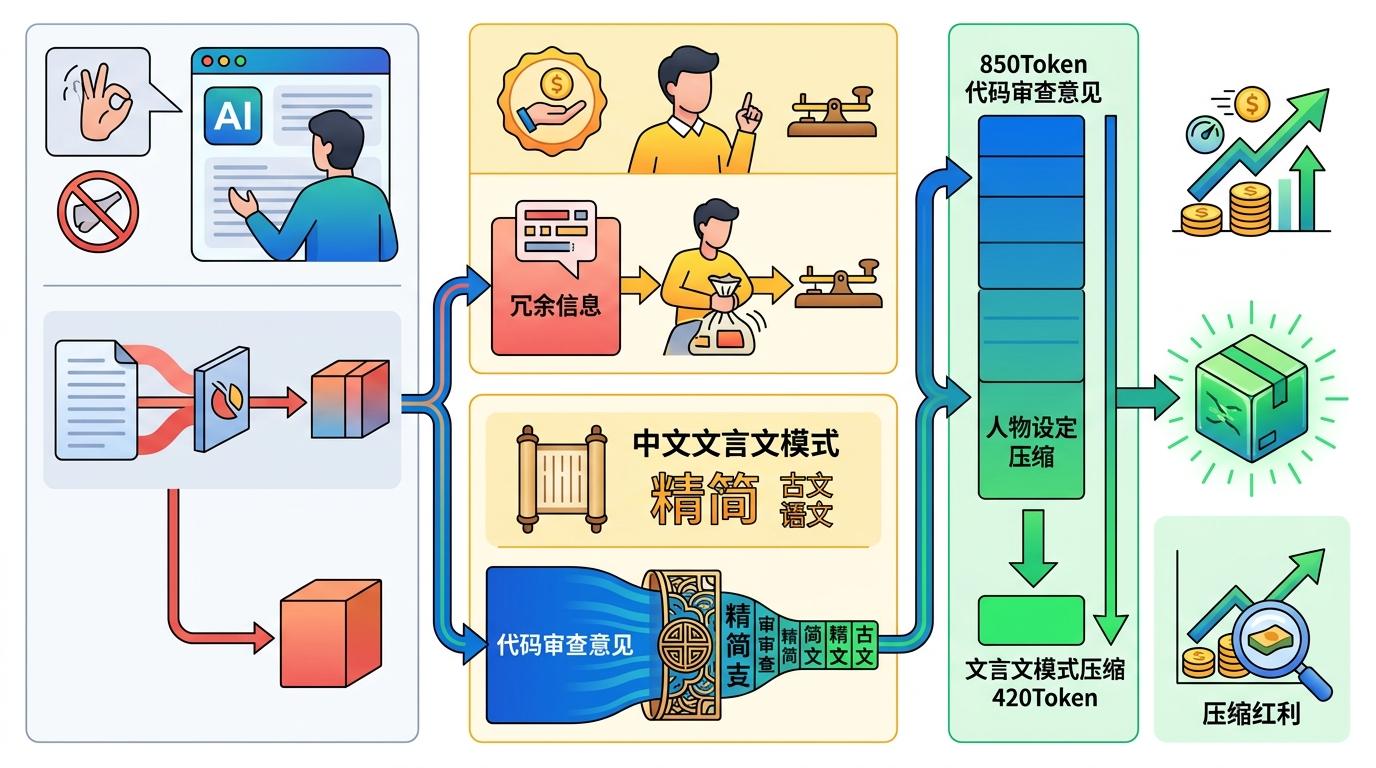
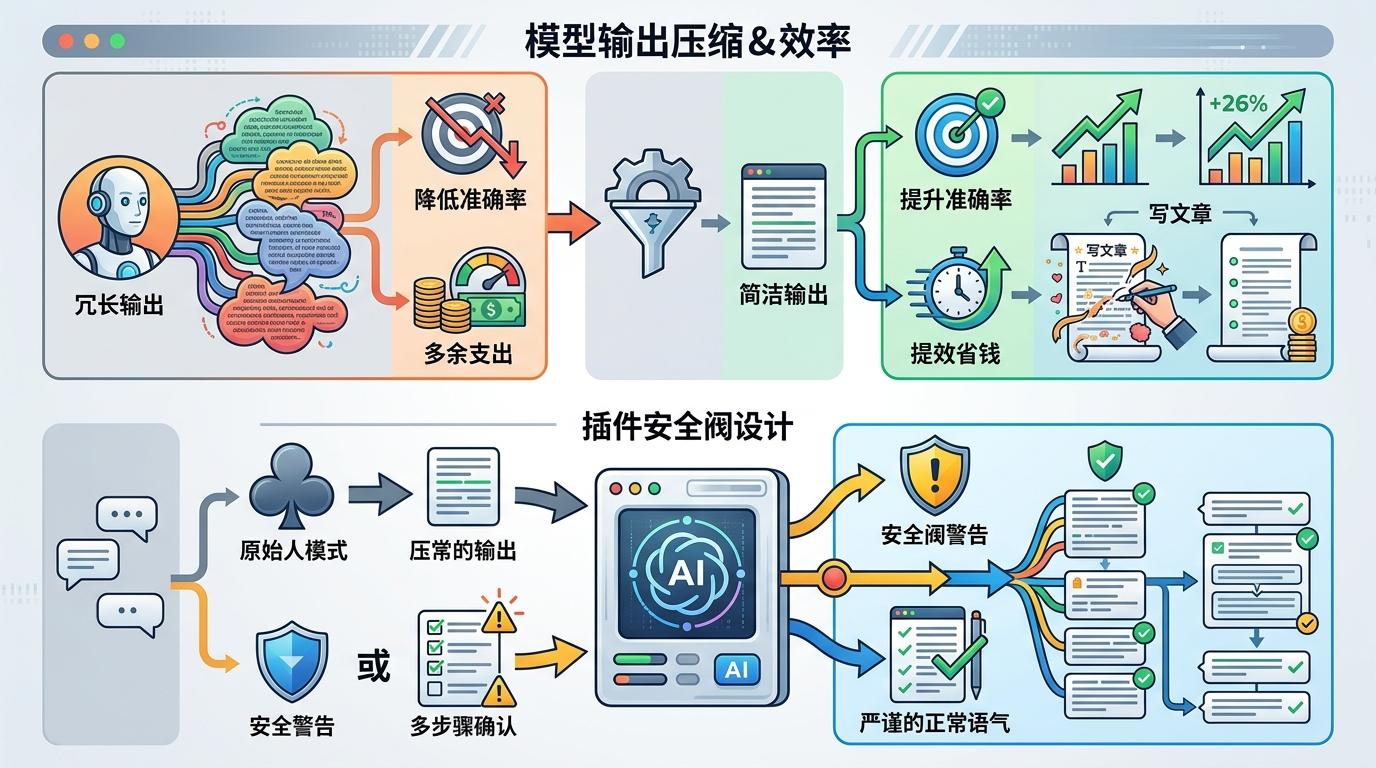
有意思的是,这种压缩不仅省钱,还能提效。2026年的一项研究显示,大模型在7.7%的任务里会因为“过度思考”的冗长输出降低准确率,而强制简洁后,部分任务的准确率反而提升了26%。就像写文章时,删掉所有修饰和铺垫,核心观点反而更清晰。插件里的安全阀设计更显贴心:遇到安全警告、多步骤确认这类不能含糊的场景,它会自动退出原始人模式,变回严谨的正常语气。
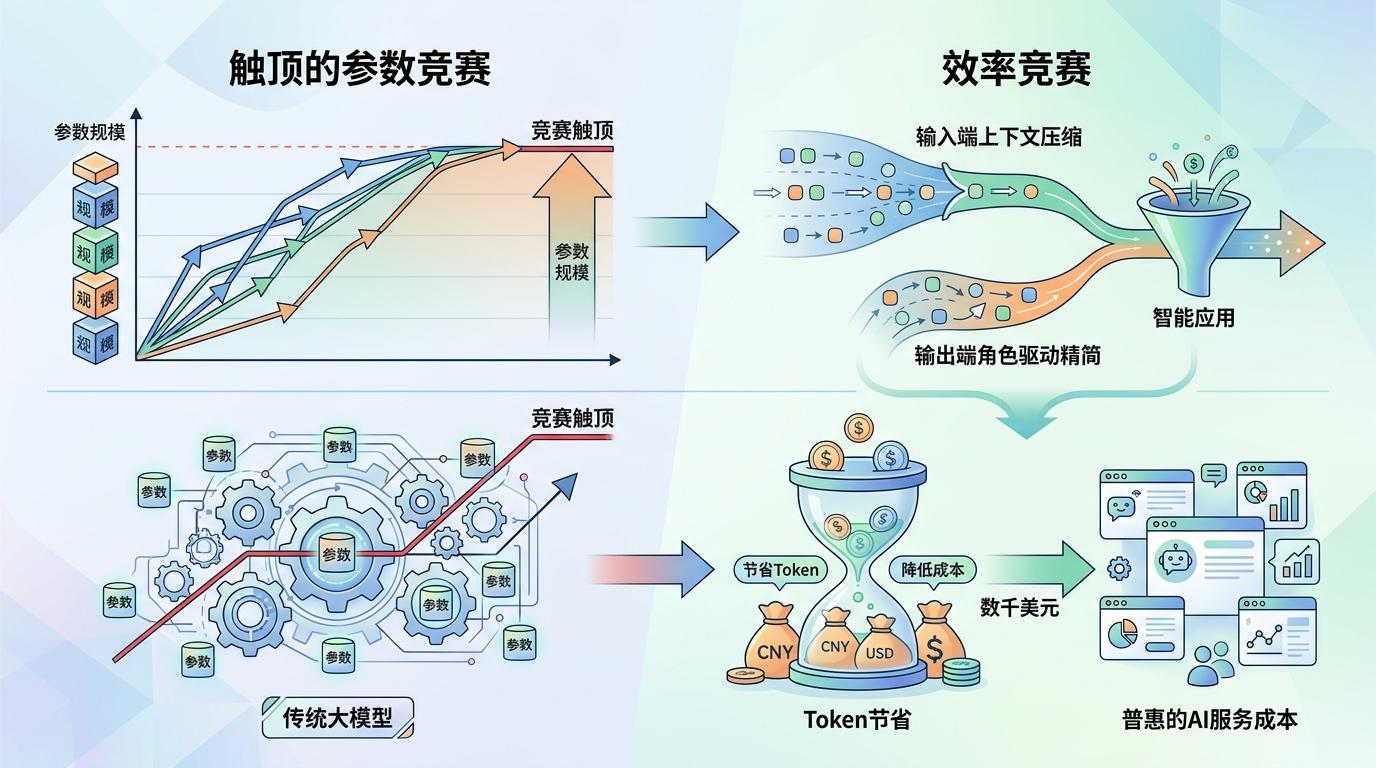
这背后藏着一个更值得琢磨的趋势:当大模型的参数竞赛逐渐触顶,人们开始转向“效率竞赛”——不是训练更大的模型,而是让现有模型用得更聪明。从输入端的上下文压缩,到输出端的角色驱动精简,每一分Token的节省,都是在给AI的规模化落地铺路。毕竟,对企业来说,每天一万次调用里省出的数千美元,最终都会变成更普惠的AI服务成本。
就像原始人用最少的音节传递最关键的生存信息,未来的AI交互,或许会回到最朴素的本质:用最少的字,解决最实际的问题。