对抗知识焦虑,从看懂这条开始
App 下载
不用奖励模型,AI画图学会自己改错题
Stable Diffusion|自我纠错机制|AI画图模型|腾讯混元团队|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载Stable Diffusion|自我纠错机制|AI画图模型|腾讯混元团队|AIGC|人工智能
你有没有过这种经历:用AI画一张带文字的海报,前几步还好好的,画到最后却发现文字变成了乱码,或者构图完全跑偏?过去我们只能怪AI“不听话”,但现在,腾讯混元团队的研究让AI第一次学会了在画图过程中“自我检查”——不用人类给它打分数,不用标注哪里错了,它能自己从训练数据里找到纠正的方法,而且比靠奖励模型的强化学习效果还好。这背后的核心,不是我们的数据不够好,而是过去的AI根本没把数据用透。
现在的AI画图模型,比如Stable Diffusion,后训练主要靠两条路:监督微调(SFT)和强化学习(RL)。但这两条路都在数据利用上犯了错。
SFT就像只背标准答案的学生:它只学“理想中应该怎么画”——比如从一张清晰图倒推出来的标准加噪步骤。但AI实际画图时,走的是自己生成的路径,一旦第一步去噪偏了方向,后面的步骤就进入了它从未学过的“陌生领域”,数据里那些“如果走偏了该怎么拉回来”的经验,SFT完全没用到。
RL则像把一本厚书压缩成了一个分数:先把好图片通过奖励模型转换成一个最终得分,再用这个分数去优化整条画图路径。这本质是一次信息的“有损压缩”——画图过程中每一步该怎么调整的细节,全被压缩成了一个干巴巴的数字,大量能纠正错误的信号就这么丢了。更糟的是,AI还会学会“钻空子”:为了拿到高分,故意生成符合奖励模型标准但实际质量差的图。
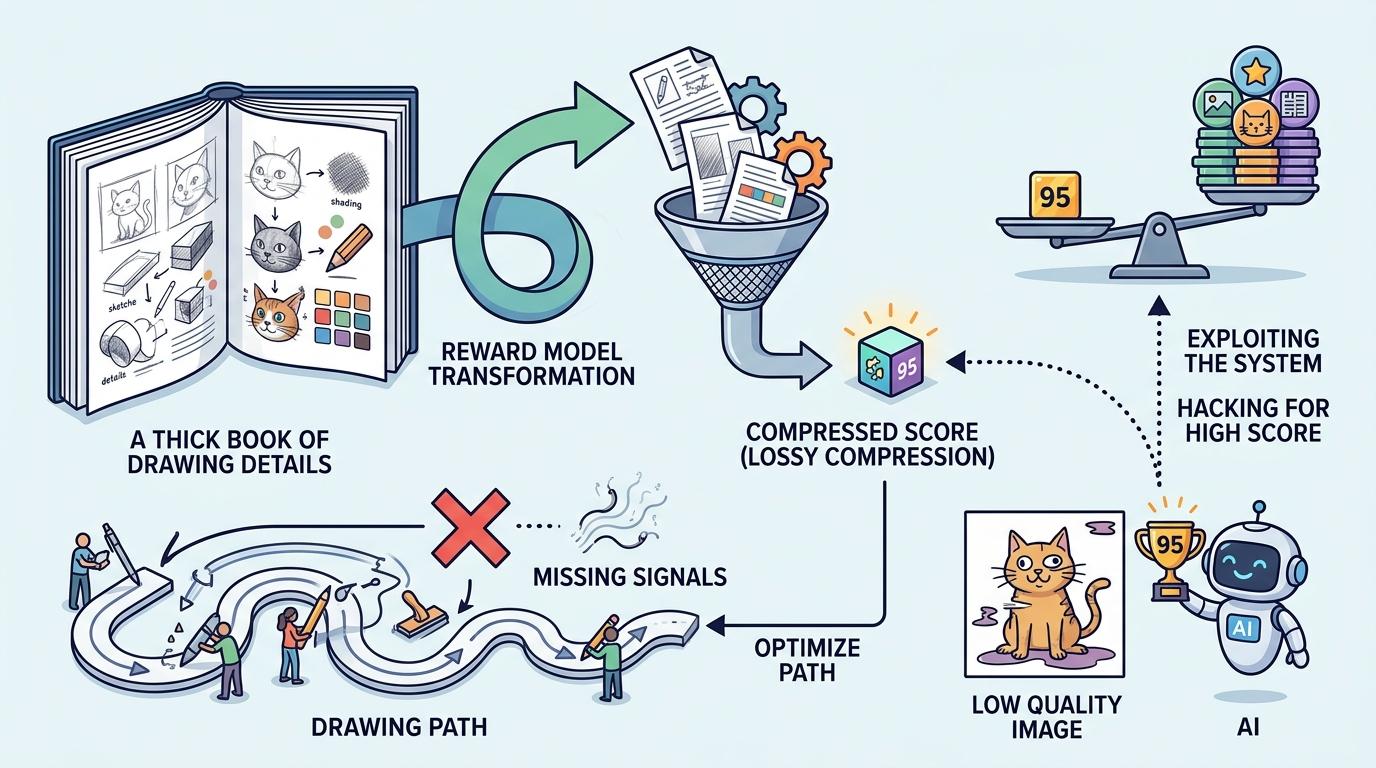
SOAR方法的核心,就是把这些被浪费的信息捡回来。它的逻辑说起来很简单:让AI先模拟自己可能走偏的路径,然后从训练数据里找到纠正的方法。
你可以把AI画图的过程想象成走迷宫:SFT只教它走正确的那条路,RL只在它走到终点时告诉它对不对,而SOAR会让它先故意走偏一次,然后看地图(训练数据)上标注的“从这里怎么回到正路”。
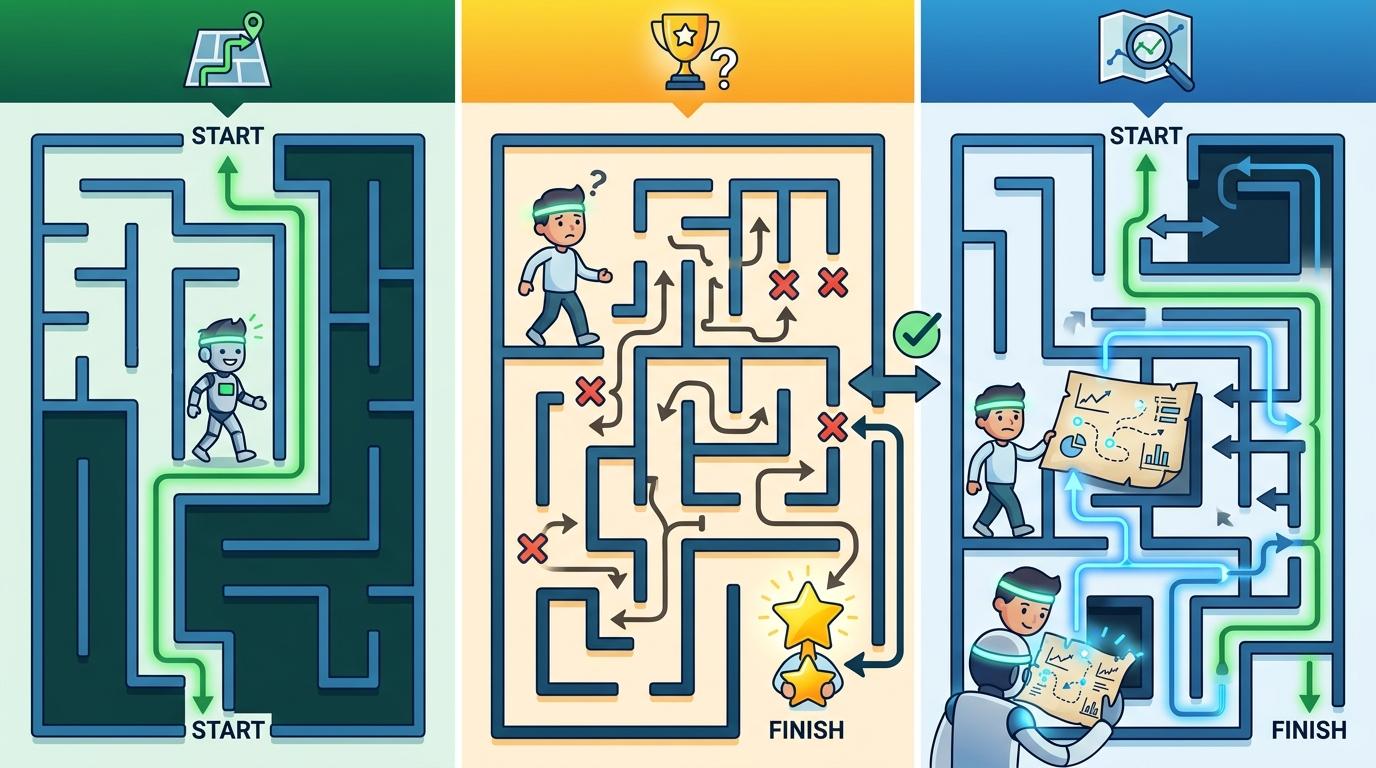
具体来说,它会先拿一张真实图片,让AI做一步无梯度推理——也就是模拟AI可能画偏的中间状态,然后给这个偏掉的状态重新加噪,构造出一个“错误训练点”,再以原始图片为参照,计算出该怎么把这个错误拉回来。整个过程不需要奖励模型,不用人类标注偏好,甚至不用错误样本,所有纠正信号都来自训练数据本身。
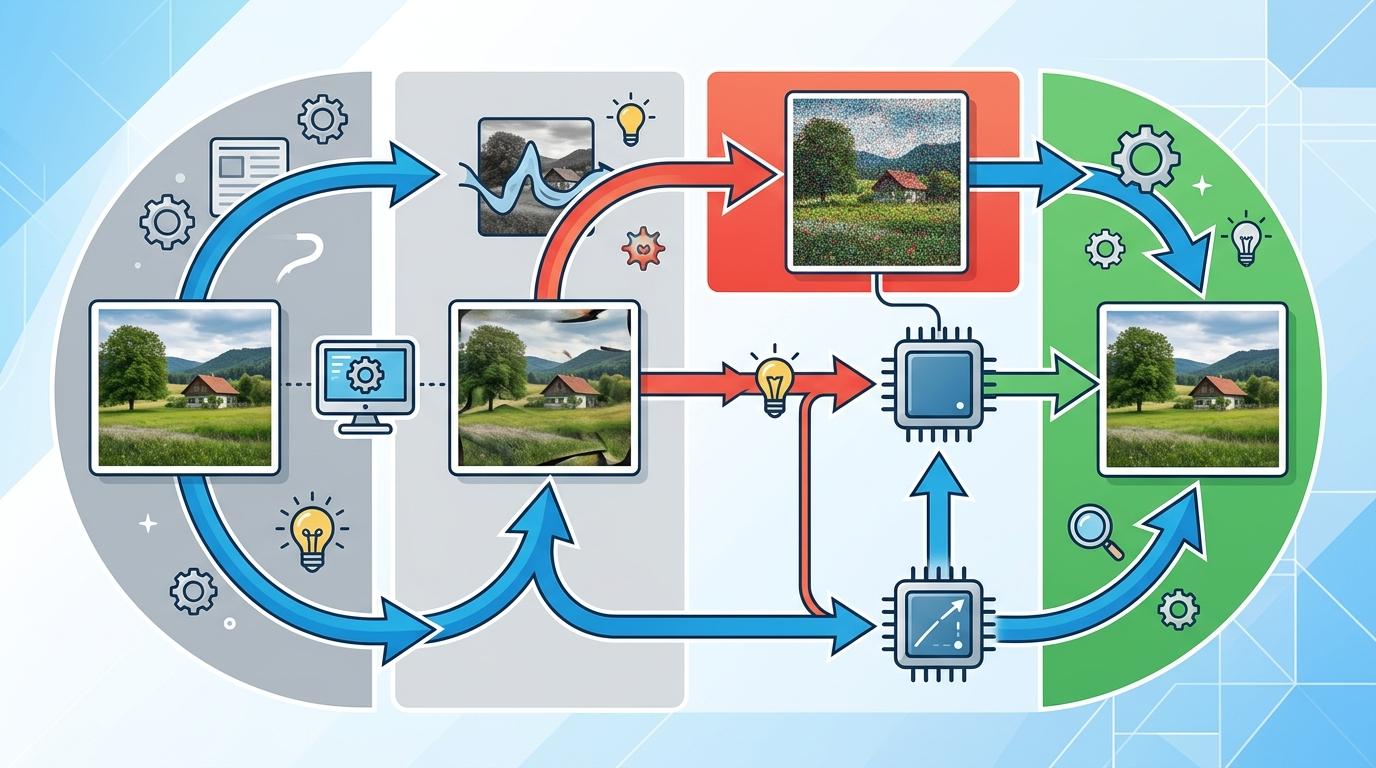
这种方法有三个关键优势:一是数据利用率最高,同一份数据既当“标准答案”又当“错题本”;二是纠正信号是“稠密”的,每一步画图都能得到反馈,不用等到最后;三是它是“在线学习”的,AI走偏的路径会随着自己的进步动态调整,永远学的是自己当前最需要纠正的错误。
在基于SD3.5-Medium的测试中,SOAR用286K图文样本训练,完全没用到奖励标注,结果在所有指标上都超过了SFT:GenEval从0.70涨到0.78,OCR准确率从0.64提升到0.67,PickScore、美学评分等模型偏好指标也同步上涨。
更让人意外的是,它甚至打赢了用奖励模型的RL方法Flow-GRPO:在高美学子集上,SOAR的最终得分是5.94,超过了Flow-GRPO的5.87;在文本对齐的ClipScore上,SOAR拿到了0.300,也超过了Flow-GRPO的0.296。而且Flow-GRPO在优化美学时,会出现文本对齐下降的情况,也就是典型的“奖励作弊”,但SOAR不会——它能同时保持多维度的质量平衡。
当然,SOAR也不是完美的。目前它主要针对视觉生成模型,能不能推广到视频、3D生成等更复杂的任务,还需要进一步验证;而且它的训练过程虽然不用奖励模型,但对计算资源的要求并不低,大规模落地还需要优化。
当我们还在为AI画图的“精度”和“速度”头疼时,SOAR给我们指了一条新的路:当数据质量已经足够高时,决定AI上限的不是数据的多少,而是我们能从数据里挖出多少价值。
过去的AI是“被动学习”,要么学标准答案,要么等着人类打分;现在的AI开始“主动进化”,能从数据里学会自我反思和纠正。这种从“模仿”到“自省”的转变,可能才是AI真正走向智能化的关键。毕竟,人类的进步从来不是只靠背标准答案,而是学会在错误中调整方向。
数据的价值,从来不在数量,而在利用的深度。