对抗知识焦虑,从看懂这条开始
App 下载
不炼丹无数据,8个参数搞定暗夜视觉
深度学习模型|智能搜索|参数优化|低光图像增强|曼彻斯特大学|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载深度学习模型|智能搜索|参数优化|低光图像增强|曼彻斯特大学|多模态视觉|人工智能
想象一下:深夜的厂区里,巡检机器人举着摄像头却像个瞎子——画面黑得只剩噪点,连地上的螺栓都看不清;自动驾驶的传感器对着路灯,要么过曝成一片白,要么暗部细节全丢。过去要解决这种“怕黑”的问题,得收集几千上万张明暗配对的图片,花几天甚至几周“炼丹”训练模型,换个场景又得重来。但曼彻斯特大学的一群研究者,用8个参数加一套智能搜索,直接跳过了所有训练环节,在行业标准测试里干翻了一堆深度学习模型。这怎么可能?
你可以把低光图像增强想象成调一杯鸡尾酒:要平衡甜度(亮度)、酸度(对比度)、酒精度(去噪强度),还要加装饰(细节保留)。过去的深度学习方法是先尝几千杯调好的酒,记住配方再调;而FLARE-BO直接给你8个精准可控的旋钮,让算法自己试出最适合这杯“酒”的比例。
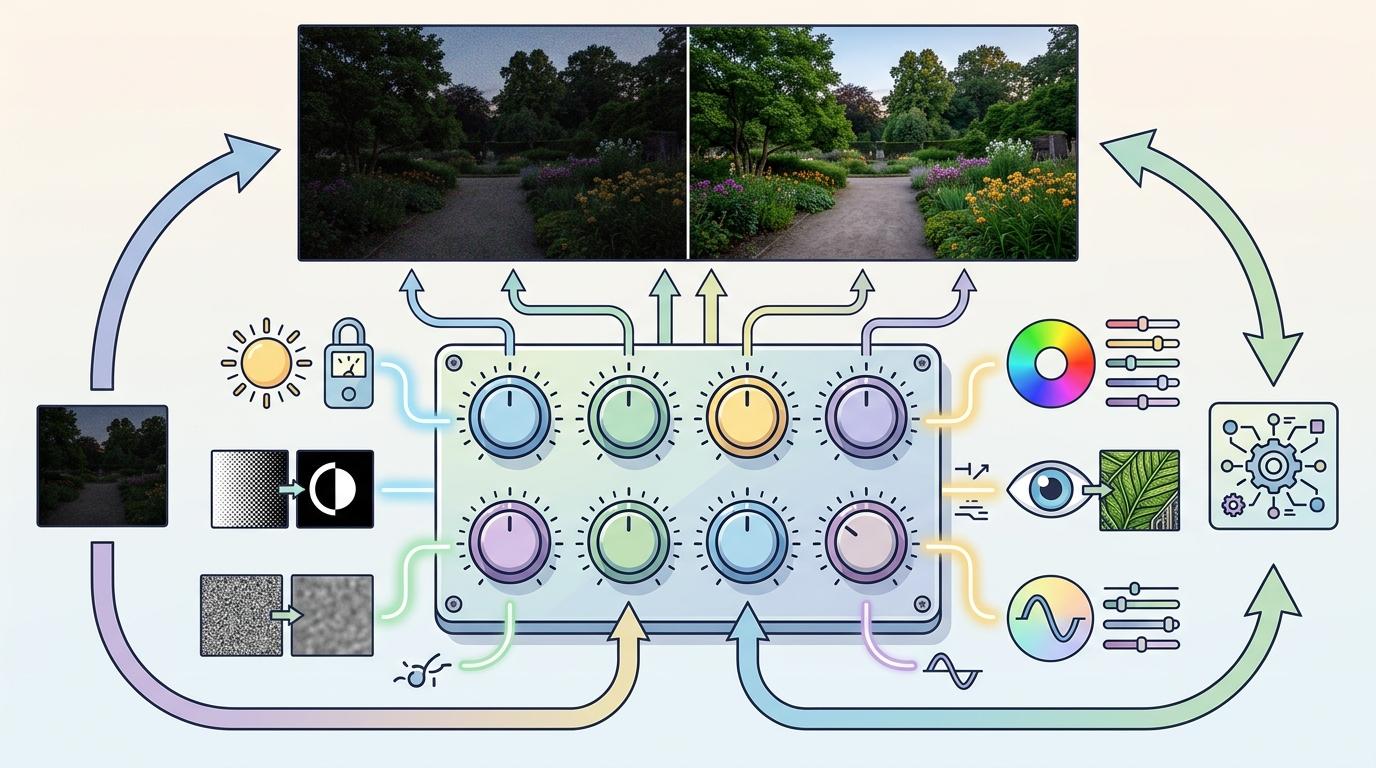
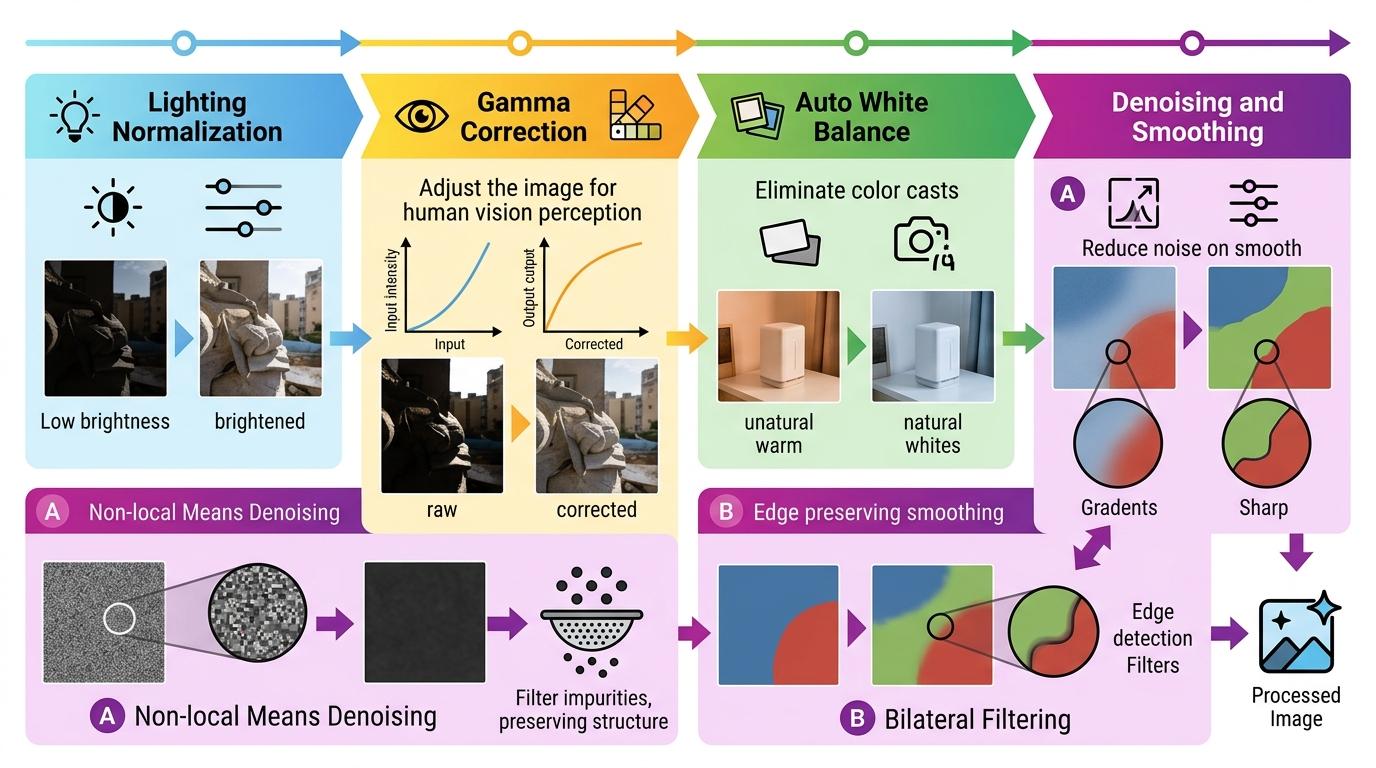
这8个参数覆盖了从照明到色彩的全流程:从拉亮暗部的照明归一化,到让画面更符合人眼的Gamma校正,再到消除色偏的自动白平衡,最后是去噪和平滑的收尾。每个旋钮都对应一个经典的图像处理技术——比如用非局部均值去噪时,就像在酒里过滤掉杂质,却保留原有的香气分子;双边滤波则是既能把酒摇匀,又不破坏冰块的棱角。
但真正的巧思在于,这些旋钮不用人来拧。贝叶斯优化会像个专业调酒师:先试3杯不同比例的酒,记住口感反馈,再根据这些反馈精准猜下一杯该怎么调,而不是瞎碰。它用高斯过程建立一个“口感预测模型”,每次选参数时都兼顾“探索新口味”和“优化现有配方”,用最少的尝试次数调出最佳味道。
很多人对“优化”的理解还停留在“把所有参数组合试一遍”——8个参数哪怕每个只试10次,都要1亿次组合,根本不现实。但贝叶斯优化是个“聪明的试错者”,核心逻辑只有两步: 第一,用高斯过程建个“代理模型”。就像你试了3杯酒,就能大概猜到“甜度加1、酸度减0.5”会是什么味道,还能知道这个猜测的靠谱程度。高斯过程会给每个参数组合一个“预测分数”和“不确定性”——分数越高说明效果越好,不确定性越高说明这个区域还没怎么探索过。 第二,用采集函数选下一个试的参数。FLARE-BO用的是Log Expected Improvement(对数期望改进),简单说就是“优先选那些可能大幅提升效果,同时又没怎么试过的参数组合”。它不会死磕当前最好的配方,也不会乱试完全没头绪的新方向,始终在“利用已知”和“探索未知”之间找平衡。 曼彻斯特大学的团队还给这个优化过程加了几个buff:把所有参数都缩到0到1之间,保证每个旋钮的权重平等;用Sobol序列生成初始尝试点,比随机采样覆盖得更均匀;把目标函数标准化,让优化过程更稳定。这些细节看似不起眼,却让8维参数空间的搜索效率提升了一个量级。
在低光图像增强的行业标准测试集LOL上,FLARE-BO拿到了PSNR 22.40、SSIM 0.8427的成绩——PSNR比很多训练过的深度学习模型高了2到3dB,SSIM更是直接拉开了0.1以上的差距。要知道,PSNR每提升1dB,画面的视觉质量就能上一个台阶。 更关键的是,它完全不用训练数据。传统深度学习模型换个场景就“水土不服”,比如在工厂里训练的模型到了野外就失效,但FLARE-BO每张图都单独优化参数,不管是厂区的路灯阴影,还是野外的月光环境,都能自动适配。 当然它也不是完美的:为了优先保证结构细节,它的自然度指标NIQE略高,简单说就是偶尔会出现一点点“塑料感”;而且每张图的优化过程需要几十秒,目前还只能用于离线处理,没法实时给机器人用。但这些问题都是技术迭代的方向,而非原则性的缺陷。
FLARE-BO的意义,不止是搞定了低光图像增强这件事,更重要的是它打破了一种思维定式:“要做好AI,就得用大数据训练大模型”。其实很多时候,把经典技术用对地方,再配上聪明的优化方法,就能得到意想不到的效果。 这就像我们总觉得要做出好菜就得买最贵的食材、用最复杂的技法,但真正的大厨能用普通食材调出惊艳的味道。在AI越来越依赖“堆数据、堆参数”的今天,这种“轻量、高效、自适应”的思路,反而更贴近工程应用的真实需求。 好的技术,从来不是越复杂越好,而是越合适越好。 未来的机器人、自动驾驶,可能不需要动辄几十亿参数的大模型,只需要几个像FLARE-BO这样的“小而美”的工具,就能在黑夜里看清路。