对抗知识焦虑,从看懂这条开始
App 下载
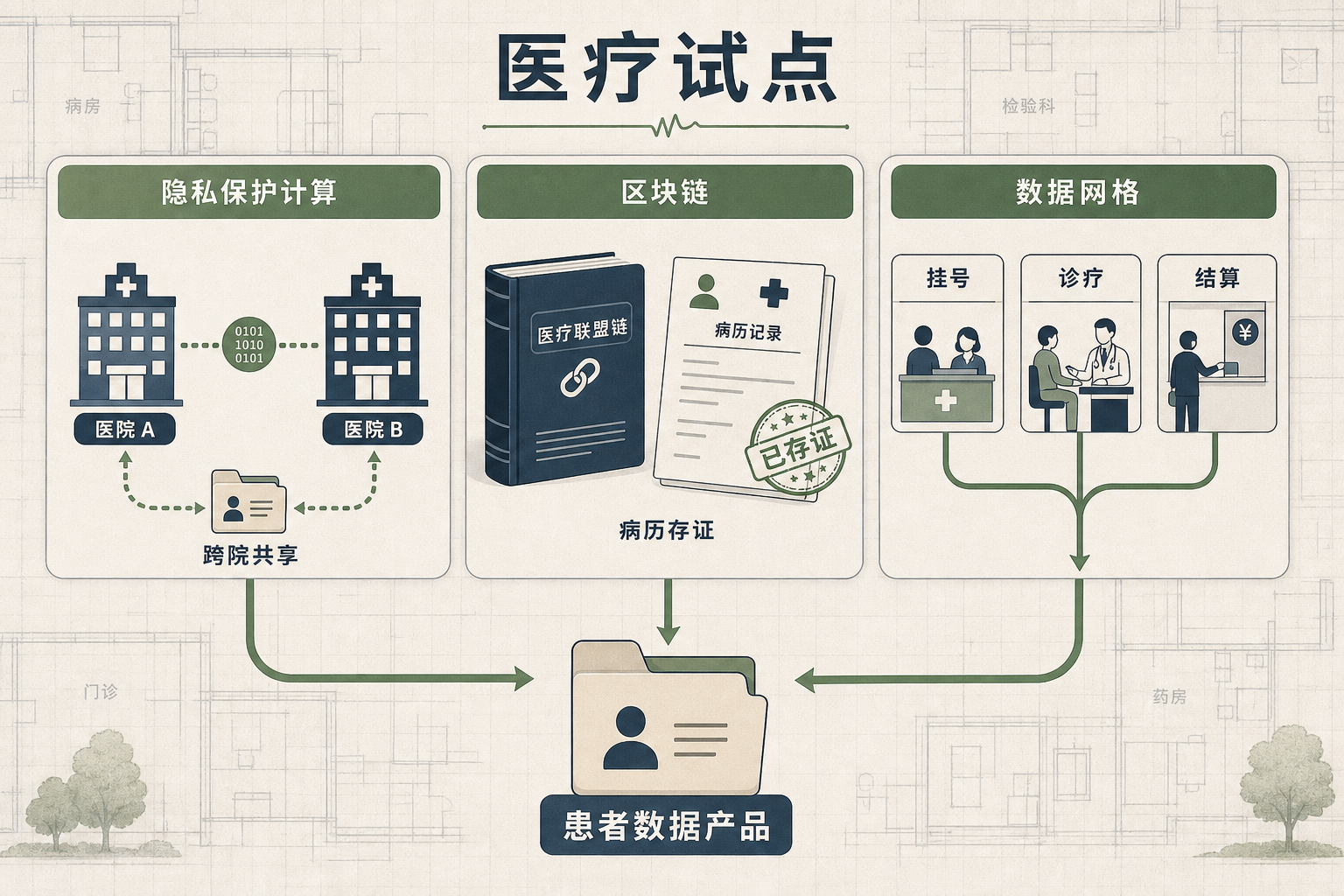
43城1.9万主体协同,数据基建不再单打独斗
技术路线|数据产品|数据孤岛|数据共享网络|国家数据局|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载技术路线|数据产品|数据孤岛|数据共享网络|国家数据局|AI产业应用|人工智能
当你在医院刷医保结算时,当车企调取路况数据优化自动驾驶时,当银行跨机构排查信贷风险时,你可能没意识到:这些顺畅的数字服务背后,曾是一个个老死不相往来的“数据孤岛”。医院的病历不敢随便给医保局,银行的客户数据不能共享给同行,大家守着数据金矿却挖不出价值——直到一套“组队挖矿”的规则出现。国家数据局的两批试点,让43个城市、1.9万个机构放下戒备,用6种技术路线搭起共享网络,上架了3.8万个数据产品。这不是简单的数据搬家,而是一场从“各自为战”到“协同共生”的基建革命。
你可以把数据基建的协同,想象成一群邻居共享自来水:每家都有自己的蓄水池(数据),但直接把水管连起来怕被偷水(数据泄露),也怕水质不一样(数据标准不统一)。现在有了两套核心工具解决这个问题:
一套是**隐私保护计算**——就像给每家的水管装了个“加密水龙头”,水(数据)流到公共管道里是加密状态,经过共同的净水器(计算节点)处理后,只流出大家需要的“纯净水”(计算结果),没人能看到别家的原水。比如银行跨机构做联合风控,不用把客户的具体流水共享,就能算出共同的风险指数;医院联合做疾病研究,不用交换患者病历,就能得出统计结论。
另一套是区块链——相当于给公共管道装了个“不可篡改的流量计”,谁什么时候取了多少水、水的来源是哪家,都记在账本上,没人能偷偷改记录。比如供应链上的商品溯源,从工厂到超市的每一步数据都存在链上,消费者扫二维码就能看到完整路径,造假者根本没法动手脚。
但真实的机制比这更精确:隐私保护计算里的安全多方计算,能让多个参与方在数学层面证明计算结果的正确性,不用依赖第三方;区块链则通过分布式账本和智能合约,自动执行数据访问的权限规则,不用人工审核。
一开始,这些技术路线是各自为战的:有的城市主打隐私保护计算,有的专注区块链,有的在试数据网格——就像邻居们各自试不同的水管和水龙头,有的漏水,有的水压不够。国家数据局的做法是“先试再合”:
但这套体系也有局限:目前跨行业的语义统一还没完全解决——比如金融行业的“客户流失”和电商行业的“客户流失”定义不同,就算数据格式统一了,也没法直接放在一起分析;部分技术的计算成本还很高,比如同态加密的计算速度比普通计算慢100倍以上,只适合特定的高敏感场景。
数据基建的终极目标,不是建一堆技术设施,而是让数据像水和电一样,成为人人能用的公共资源。现在的试点已经显现出这种潜力:
在制造业,数联网把工厂的设备数据、供应链的物流数据、经销商的销售数据连在一起,企业能实时调整生产计划,比如根据经销商的库存数据,提前3天调整生产线的产量,减少了15%的库存积压;在智慧城市,可信数据空间把交通、公安、环保的数据整合起来,能在早高峰时自动调整红绿灯时长,还能根据空气质量数据优化公交线路,让市民的通勤时间平均缩短了8%。
更重要的是,这些数据产品不是由政府或大企业垄断的,1.9万个生态主体里,有大量的中小微企业和科研机构——比如一家创业公司用试点开放的交通数据,开发了面向网约车司机的“最优路线推荐”工具,上线半年就覆盖了10万司机;一所大学用医疗数据产品,研究出了针对糖尿病的早期干预模型,准确率比传统模型提升了22%。
过去我们总说“数据是新的石油”,但石油需要开采、提炼才能用,数据也需要基建、协同才能释放价值。这场从“孤岛”到“网络”的革命,本质上是把“数据私有”的旧逻辑,变成了“数据共享、价值共创”的新逻辑。
数据的价值,不在拥有而在流动。当越来越多的机构放下戒备,当技术路线越来越协同,我们可能会看到更多意想不到的创新:比如跨医院的AI诊断模型,跨银行的普惠金融产品,跨城市的智能交通网络。这些创新不会来自某一家巨头,而是来自1.9万个主体组成的生态——就像无数条溪流汇聚成河,才能真正滋养大地。