对抗知识焦虑,从看懂这条开始
App 下载
140万亿次调用背后,AI正在重构中国产业
快递柜智能化|机械臂自动化|智能问诊APP|词元调用量|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载快递柜智能化|机械臂自动化|智能问诊APP|词元调用量|大语言模型|人工智能
当你在智能问诊APP上传一张胸片,当工厂里的机械臂自动调整焊接角度,当快递柜根据你的取件习惯提前弹出柜门——这些细碎场景的背后,是一组足以颠覆认知的数字:截至2026年3月,中国AI大模型的日均词元(Token)调用量突破140万亿,较上年末增长超40%。这意味着每一秒,就有超过16亿个文本、图像或语音片段在AI的神经网络中流转。为什么这个数字值得我们停下脚步?因为它标志的不是技术的炫技,而是AI从实验室真正扎进了实体经济的土壤。
要理解140万亿这个数字的分量,得先搞懂什么是词元——它是AI处理信息的最小单位,一个汉字、半个英文单词,甚至一个标点都可能成为一个词元。这个指标就像电力系统的发电量,直接反映AI的实际使用强度。国家统计局披露的这组数据,不是某家企业的营销噱头,而是全国范围内AI商业化的集体成绩单:从政务大厅的智能审批系统,到医院里的辅助诊断模型,再到工厂车间的预测性维护算法,AI已经从“尝鲜品”变成了刚需工具。

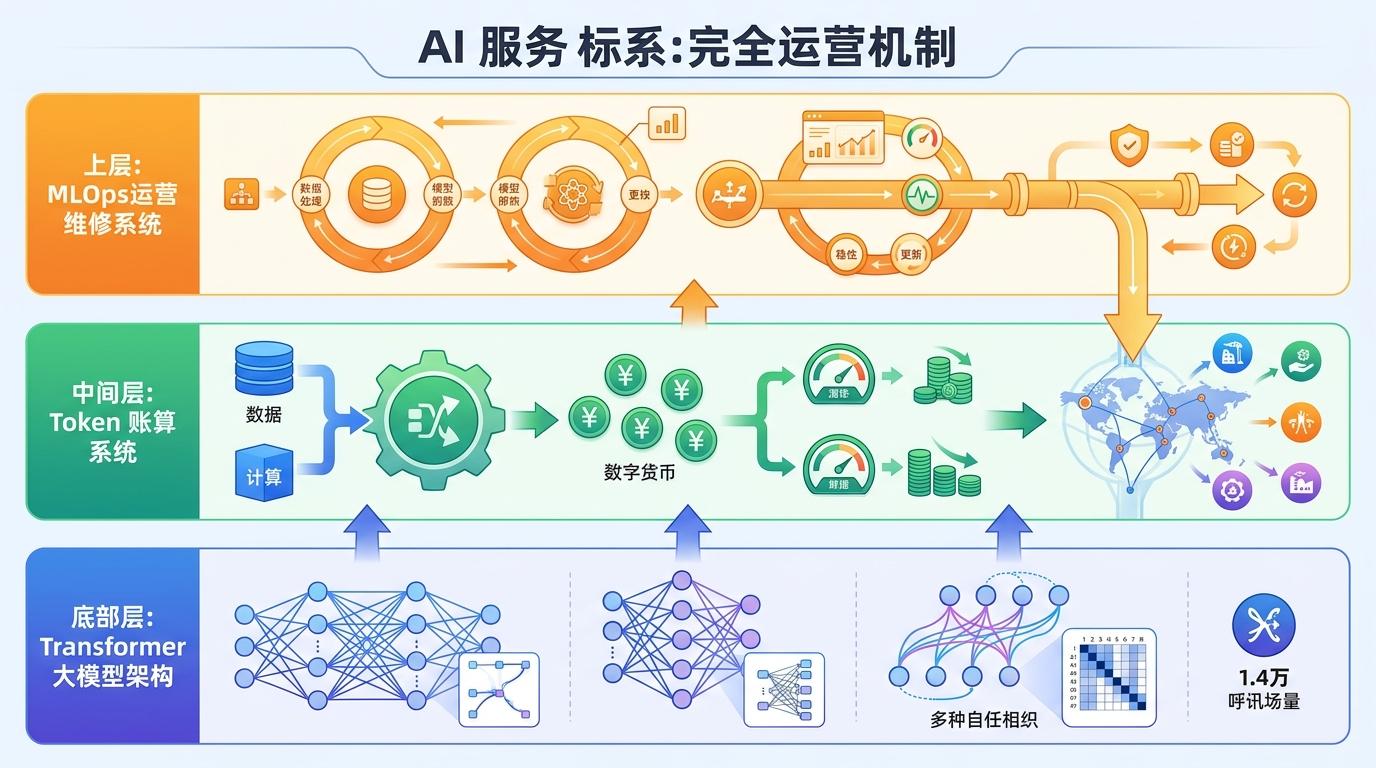
支撑起这140万亿调用量的,是一套从技术到商业的完整运转机制。底层是Transformer架构的大模型,通过自注意力机制捕捉信息间的关联;中间是Token计费体系,把AI的算力消耗变成了可计量、可交易的“数字货币”——企业不用再为闲置的算力付费,只用为实际调用的词元买单;上层则是MLOps运维体系,确保模型在生产环境中稳定运行、持续迭代。这套机制就像一个高效的物流网络,把AI的能力精准递送到每一个需要的场景。
当然,这股增长浪潮背后也藏着隐忧。当前中国AI产业仍面临算力瓶颈,高端芯片的供应限制着大模型的进一步升级;数据隐私与合规的边界仍在探索,算法偏见、数据泄露的风险如影随形;高端AI人才的缺口,更是制约着技术创新的速度。这些问题不是一时能解决的,但它们也恰恰是AI产业从“规模化”走向“精细化”的必经关卡。
把视线拉向全球,中国AI的优势正在显现:我们拥有最庞大的应用场景,最活跃的开发者生态,以及最快速的落地能力。美国在高端芯片和闭源大模型上保持领先,但中国的开源模型凭借低成本、高适配性,正在赢得更多发展中国家的青睐。未来的AI竞争,不再是单一技术的比拼,而是技术、场景、生态的综合较量。
站在140万亿这个节点上,我们看到的不只是数字的增长,更是一个智能社会的雏形。AI不再是实验室里的“黑科技”,而是像水电煤一样的基础设施,渗透进每一个行业的毛细血管。或许用不了多久,当我们谈论AI时,就像现在谈论互联网一样自然——这,就是140万亿次调用背后,正在发生的未来。