对抗知识焦虑,从看懂这条开始
App 下载
AI越好用越用不起,Token成了新流量焦虑
AI会员费用|算力计价|Token限额|Claude|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI会员费用|算力计价|Token限额|Claude|大语言模型|人工智能
周三晚上十点,博士生苏玉盯着电脑屏幕上的弹窗,指尖悬在键盘上动不了。屏幕里Claude的对话框停在一半,那句“本周Token使用已达90%限额”像一道闸,把她刚理清的论文框架拦在了外面。她花180元开了月度会员,原本指望这个排名全球第一的大模型帮她啃下毕业大论文,现在却要像挤牙膏一样算着Token用——连和AI说句“谢谢”都觉得是浪费。这场景像极了二十年前拨号上网的深夜,盯着浏览器加载条,连开个图片都要心疼半天带宽。只不过当年省的是流量,现在省的是Token,是AI时代最金贵的“数字燃料”。
你可以把AI算力的流动想象成自来水厂供水:上游是GPU芯片和数据中心,像水库和水泵,每一块NVIDIA H100显卡都是一个造价百万的“超级水泵”;中游是云厂商和模型厂商,像小区的供水站,把算力封装成一个个可计量的Token——简单说,就是AI能读懂的最小语言单位,100个Token大概对应75个英文单词或50个汉字;最后流到用户端,就是你和AI的每一次对话、每一段生成的文字,都要按Token计价付费。
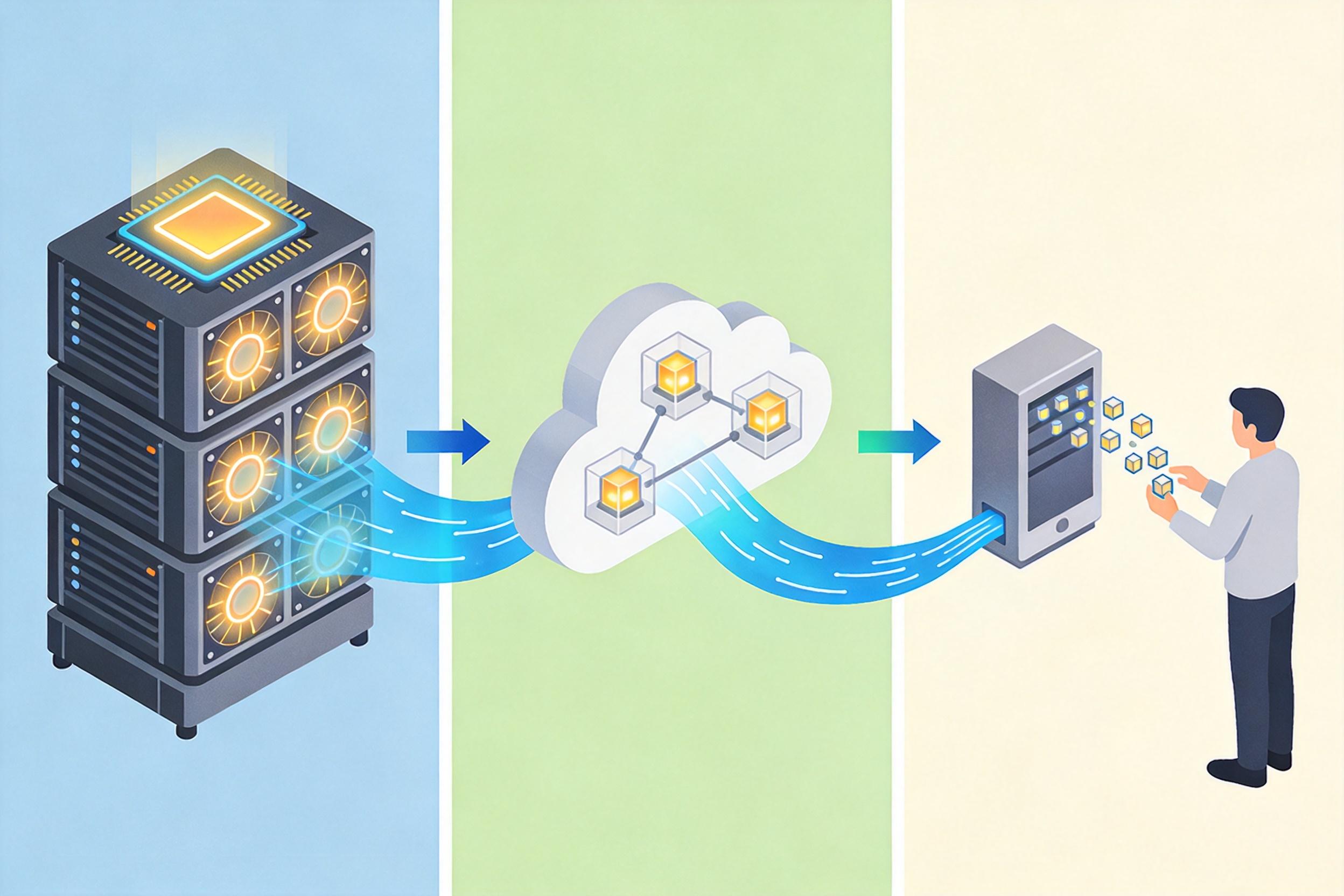
但真实的机制比这更复杂:输入Token和输出Token价格差3到8倍,AI“思考”过程中产生的推理Token,价格甚至比输出Token还高。一个看似简单的智能体请求,背后可能是十几次API调用,Token消耗呈指数级增长。就像你只是拧开了水龙头,却不知道水管在地下绕了十圈,账单下来时才发现水费翻了倍。
2023到2025年,单个Token价格降了40倍,但用户的总花费却涨了好几倍。这不是商家坐地起价,而是AI的“胃口”变大了——智能体、多模态这些新功能,就像从喝水变成了洗澡,耗水量翻了几十倍。
苏玉给自己的AI工具做了个“优先级梯队”:Claude只用来搭论文框架、分析核心访谈材料;ChatGPT负责写公文、整理简报;Gemini就处理画图、初始编码这些“体力活”。她算过,把核心任务交给顶级模型,边缘任务交给轻量模型,能省60%以上的Token成本。
这不是她一个人的精打细算。AI影视创业者会同时接入五六个模型API,把特效生成交给最贵的模型,字幕校对交给最便宜的;开发者们在社交平台上分享“文言文对话技巧”,就为了用更少的字数换更多的信息——毕竟每多一个字,就是多消耗一个Token。
更隐蔽的鸿沟藏在产业链上游。高端GPU市场90%被一家公司垄断,数据中心的电力成本占了算力成本的30%以上,小团队根本租不起整机架的H100显卡。OpenAI 2025年上半年赚了43亿美元,却亏了135亿美元,这些亏损全砸在了算力上——普通用户看不到这些,只知道好用的模型越来越贵,免费额度越来越少。
你手里的Token数量,正在悄悄定义你的“数字阶层”。能随便用顶级模型的人,和只能蹭免费额度的人,就像二十年前能随便用宽带的人和只能拨号上网的人,效率差的已经不是一星半点。
当Token价格像过山车一样波动,有人开始把算力当成大宗商品来交易。黄仁勋提出的“Token经济学”,正在从概念变成现实——就像石油有期货市场,未来Token也可能有期货合约,企业可以提前锁定算力成本,避免突然涨价的冲击。有研究显示,这种期货工具能把企业的算力成本风险降低60%以上。
企业也在学着“省着用”。一种叫AI FinOps的方法开始流行:实时监控Token消耗,给不同部门设预算,用智能路由把请求自动分配给最便宜的模型,甚至把高频查询的结果缓存起来,不用每次都调用AI。就像企业里的财务总监,一分一厘地算着算力的账。
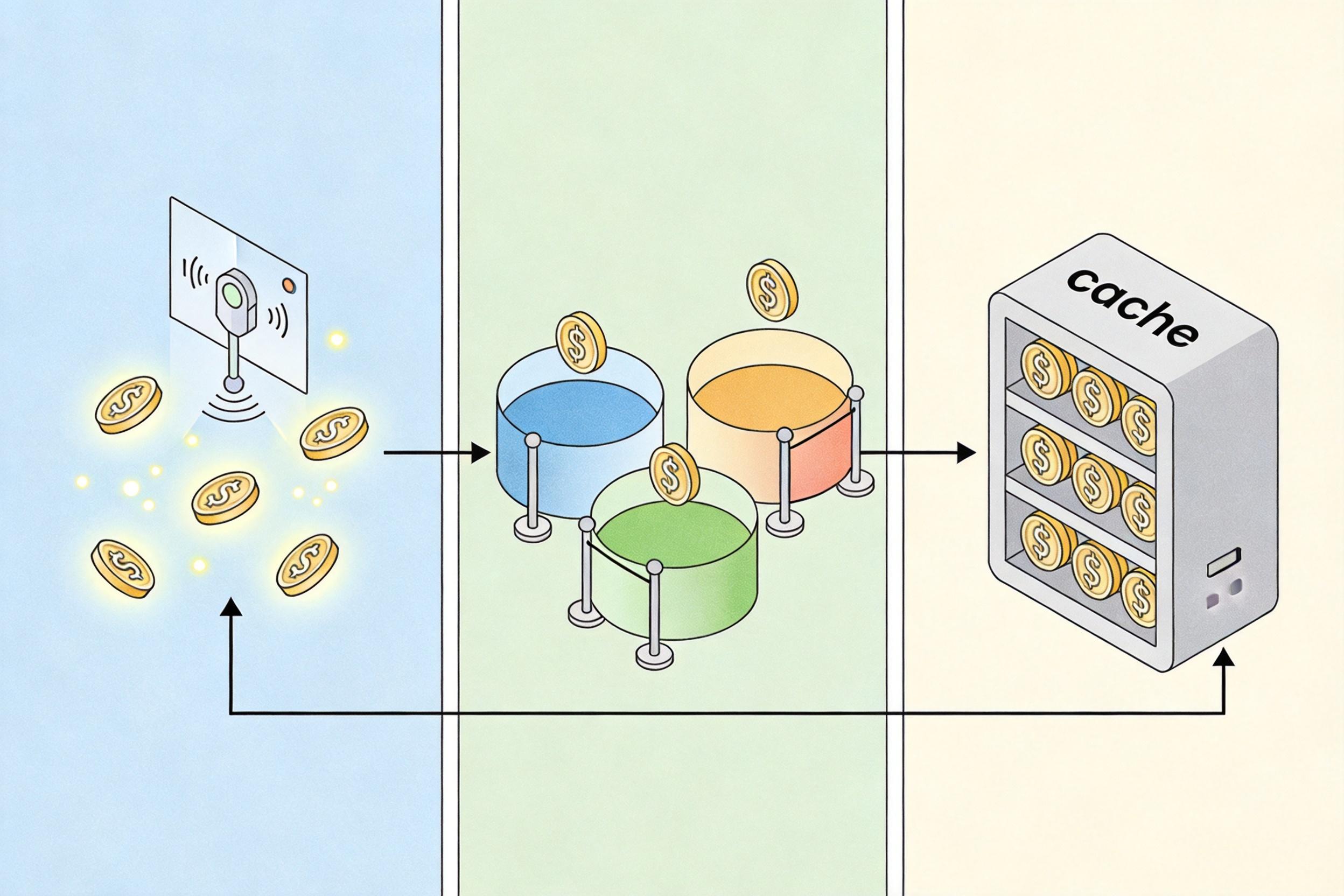
但这些方法都只是“治标”。真正的问题在于,AI算力的供给瓶颈不是短期能解决的:高端GPU的生产周期要18到24个月,数据中心的电力扩容要等电网改造,这些都是物理世界的硬限制。就像你再怎么省水,水库里的水不够了,还是要停水。
苏玉最近又发现了一个新技巧:把Claude给出的分析框架复制给Gemini,让Gemini帮她做后续的编码工作。“虽然不如Claude准,但能省不少Token,”她笑着说,“就像请不起资深律师,先找个助理打打下手。”
我们总说AI会让世界更公平,但现在看来,它可能先让不公平变得更明显。Token不是简单的数字,它是算力的计量单位,是AI时代的“数字入场券”。算力有界,效率分层——未来的竞争,或许不再是比谁更努力,而是比谁能更聪明地用好每一个Token。
深夜的实验室里,苏玉关掉Gemini的页面,又点开了Claude。她盯着输入框,想了半天,只敲了一行字:“帮我检查这段逻辑是否通顺。”这次她没说“请”,也没说“谢谢”。