对抗知识焦虑,从看懂这条开始
App 下载
大模型用了10年的残差连接,被Kimi改了
ResNet|注意力残差|残差连接|Moonshot AI|Kimi大模型|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载ResNet|注意力残差|残差连接|Moonshot AI|Kimi大模型|大语言模型|人工智能
你有没有想过,现在动辄几百层的大模型里,近一半的层可能在“摸鱼”?2026年3月,Moonshot AI在自家48B参数的Kimi大模型上验证了一个惊人的结论:用了10年的残差连接——那个让深层网络能被训练起来的核心设计,正在悄悄拖垮模型效率。他们用一种叫注意力残差(AttnRes)的新方法,让所有测试任务的性能全线上扬,甚至能以80%的算力达到原模型的效果。问题到底出在残差连接的哪里?为什么这个用了十年的“标准答案”突然失效了?
要理解这个问题,得先回到2015年——何凯明团队用残差连接让ResNet在图像识别竞赛中夺冠,从此它成了所有深度学习模型的标配。你可以把残差连接想象成公司里的“全员邮件”:每一层处理完信息,就把结果和原始输入打包在一起,一股脑发给下一层。这种“原封不动+加工结果”的打包方式,解决了梯度消失的致命问题——让训练信号能从几百层的网络末端,顺畅地传回最开始的层。
但没人注意到,这种“全员邮件”本质是在煮一锅大锅饭。每一层都把自己的内容不加区分地倒进同一个锅里,越往后,锅里的内容越杂:第5层的特征和第12层的特征混在一起,权重完全一样。后面的层根本没法说“我现在只需要第5层的信息”,它只能接收这锅乱炖。
这带来两个实打实的麻烦:一是随着层数加深,锅里的数值会越来越大,后面的层必须输出更大的数值才能不被淹没;二是大量早期层的有效信息被稀释,到了网络深处,很多层的输出其实已经没什么影响力——就像在几百人的群里发消息,很快就会被刷下去。实验证明,删掉大模型里近三分之一的层,性能几乎没变化。
Kimi的解法说穿了很简单:把“大锅饭”改成“自助餐”。他们提出的注意力残差(AttnRes),核心就是让每一层自己决定要从前面哪些层拿信息,而不是被动接收所有内容。
具体怎么做?每一层会生成一个专属的“点单清单”——一个轻量的查询向量,用它去和前面所有层的输出算“相似度”:相似度高的层,权重就大,相当于多拿点;相似度低的就少拿甚至不拿。最后把这些按权重挑选的信息加起来,传给下一层。这就像你去餐厅吃饭,不用把所有菜都端到面前,只选自己想吃的几样就行。
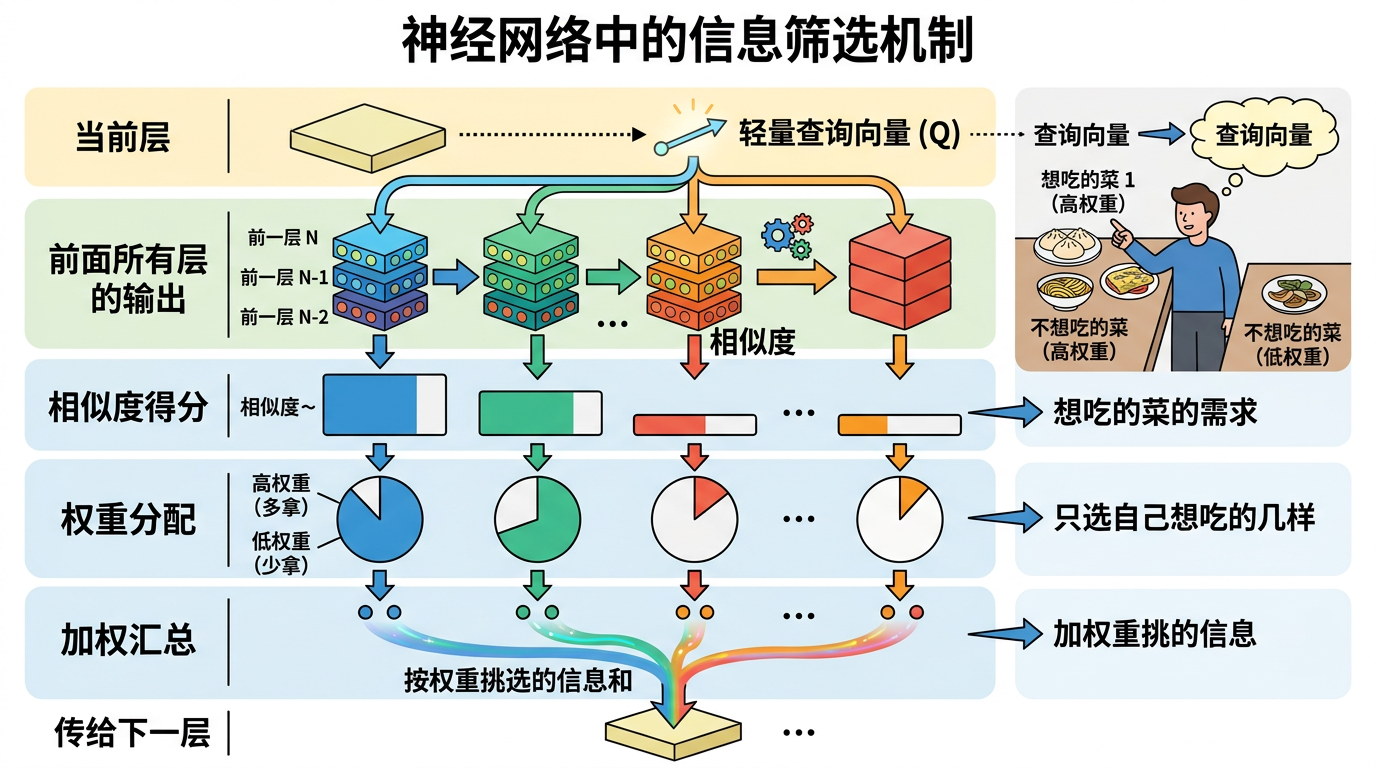
但这个方案有个工程难题:如果每一层都要保存前面所有层的输出,对百层以上的大模型来说,内存和通信开销会直线飙升——就像要给每个食客保存餐厅开业以来所有的菜,根本不现实。
Kimi的工程师们做了个聪明的妥协:把几十层的网络分成8个左右的“区块”,区块内部还是用传统的残差连接煮小锅饭,区块之间再用注意力机制选餐。这样一来,需要保存的内容从“所有层”变成“几个区块”,内存开销直接降到原来的十分之一,训练额外开销不到4%,推理延迟只增加了2%。
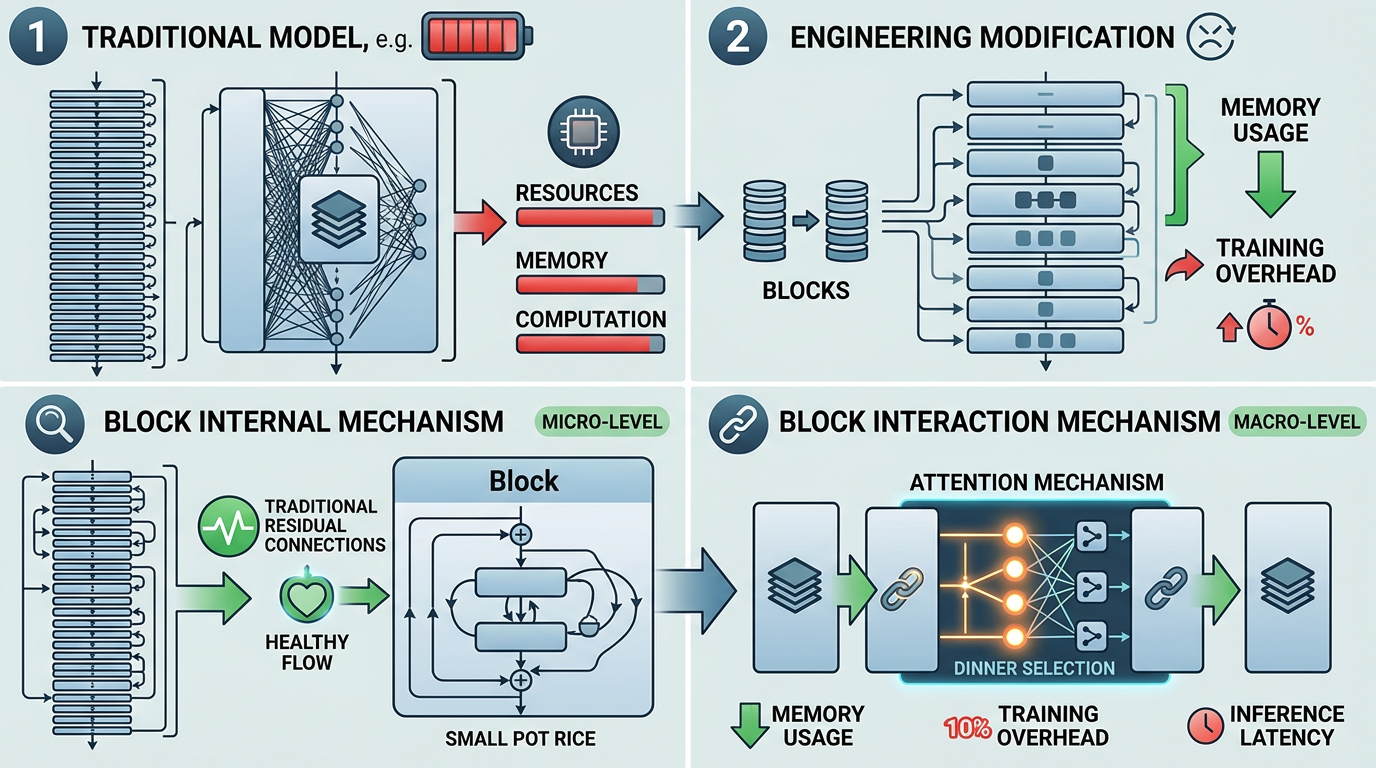
实验结果比预想的更惊艳:在48B参数的Kimi大模型上用1.4万亿tokens预训练后,AttnRes版本在所有测试任务上全线上扬——科学推理任务提分7.5,数学推理提3.6,代码生成提3.1。更重要的是,它解决了残差连接带来的两个核心问题:
一是数值膨胀被按住了。原来的模型越往后,层输出的数值越大,到最后几乎是早期层的10倍;用了AttnRes后,数值被控制在稳定范围,不会出现“后面的层必须喊得更大声才能被听见”的情况。
二是梯度分布均匀了。原来的模型里,最早的几层梯度异常大,后面的层梯度却小得可怜,相当于公司里只有创始人在发号施令,基层员工的意见传不上去;AttnRes让每一层的梯度都能发挥作用,每一层都在真正地学习。
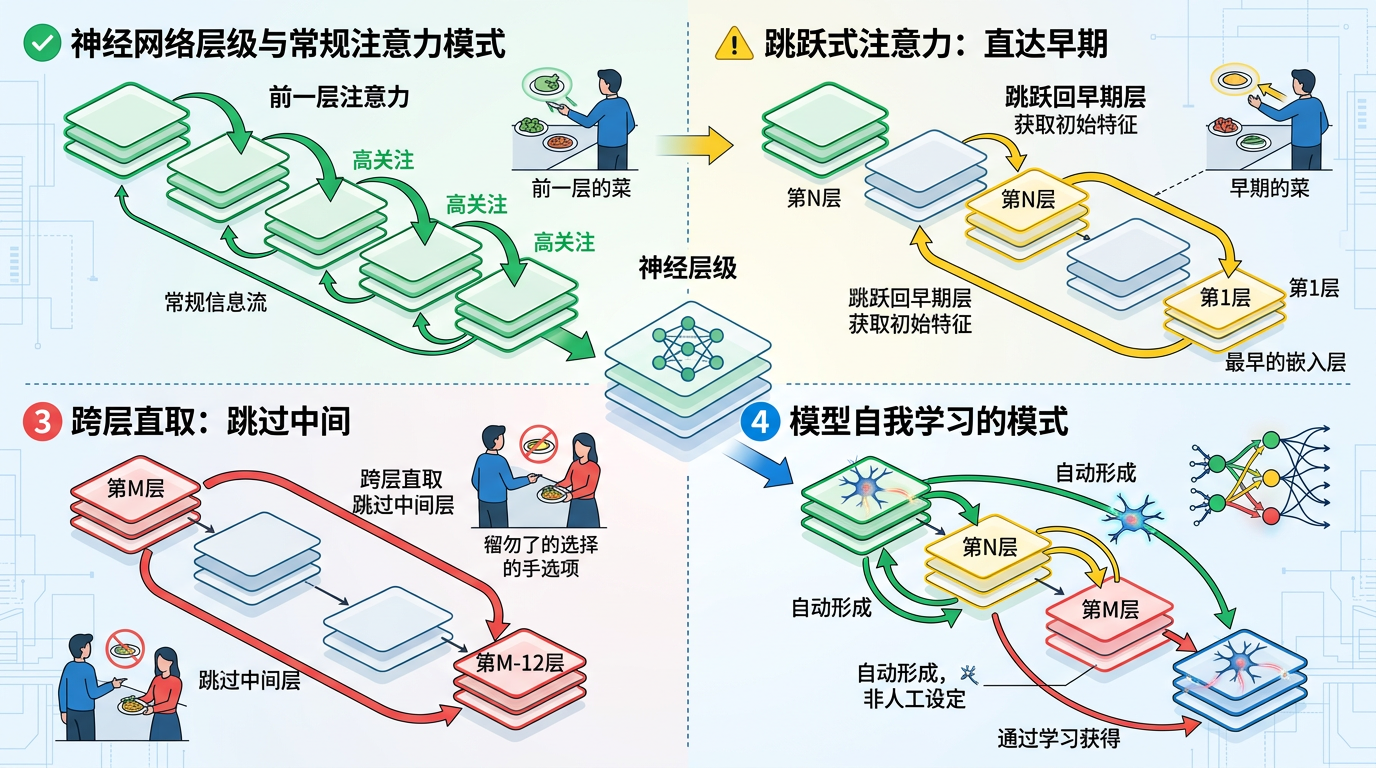
更有意思的是,他们可视化了模型的注意力模式:大多数层还是主要关注前一层——就像你吃饭时主要点刚做好的菜,但有些层会突然“跳”到最早的嵌入层去拿信息,或者跳过中间十几层直接取某一层的结果。这些都不是人工设定的,是模型自己学出来的。
我认为,AttnRes的意义远不止性能提升——它第一次把“按需取用”的逻辑引入了深度网络的层间信息流。过去十年,我们一直在想怎么让网络更深,现在终于开始思考怎么让每一层都更有用。
从2015年的ResNet到今天的AttnRes,深度学习的核心矛盾其实一直没变:怎么在“让信息传得通”和“让信息用得好”之间找平衡。残差连接解决了前者,让几百层的网络能被训练起来;而AttnRes开始解决后者,让每一层的信息都能被精准调用。
这就像城市的发展:最早的城市只需要打通主干道,让人流物流能跑起来;但到了一定规模,就需要修建高架、地铁,让不同的人流能精准到达目的地。AttnRes就是深度学习里的“城市轨道交通系统”。
好的架构,从来不是把路修得更长,而是让每一段路都不堵车。 当我们不再执着于堆层数,转而关注每一层的效率时,大模型的下一个时代,可能才真正开始。