对抗知识焦虑,从看懂这条开始
App 下载
算力卡脖子下,两家中国公司跑出AGI新路径
训练算法优化|缓存压缩技术|底层架构创新|高端GPU出口|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载训练算法优化|缓存压缩技术|底层架构创新|高端GPU出口|大语言模型|人工智能
当美国把高端GPU的出口阀门越拧越紧时,没人想到中国的AGI竞赛会以这样的方式突围:不是靠砸钱堆出更多芯片,而是让每一块芯片的效率翻了十倍。2026年4月,两家相隔1.4公里的中国团队先后发布新模型,用一套全新的底层架构,把万亿参数模型的训练成本砍到原来的1/10,还让AI的长文本处理能力直接突破了百万token大关。更有意思的是,他们的技术路线像两条缠绕的藤蔓——你用了我发明的缓存压缩,我跟进了你优化的训练算法,甚至连创始人的理念都如出一辙:比起抢流量,先把AGI的地基打牢。
传统大模型像个全能选手,处理任何任务都要调动全身所有“脑细胞”——哪怕只是写一段代码,也要激活全部万亿参数,不仅费电,还容易卡壳。而这两家团队用的MoE混合专家架构,相当于把大模型拆成了上百个“专业小组”:写代码时只唤醒编程专家,解数学题时就调用逻辑专家,每个任务最多只激活1/10的参数。
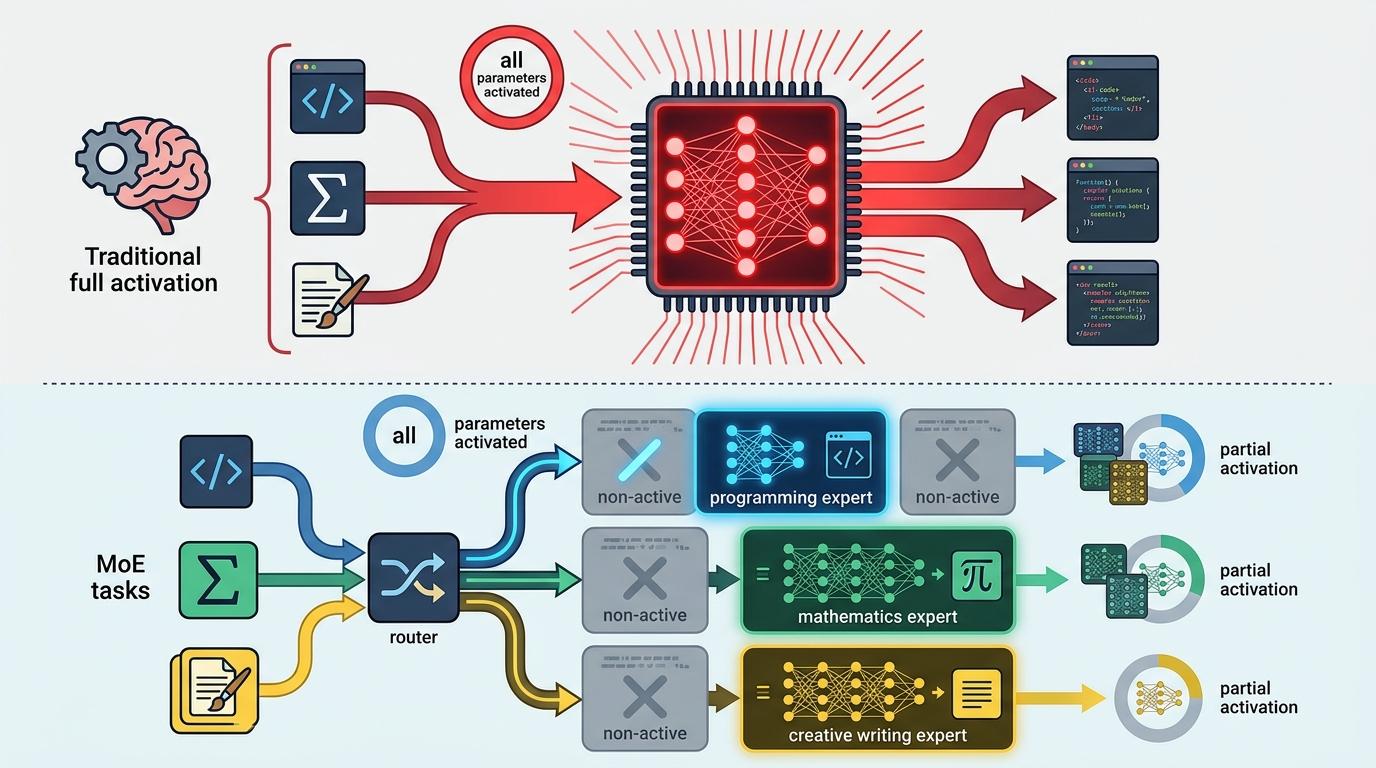
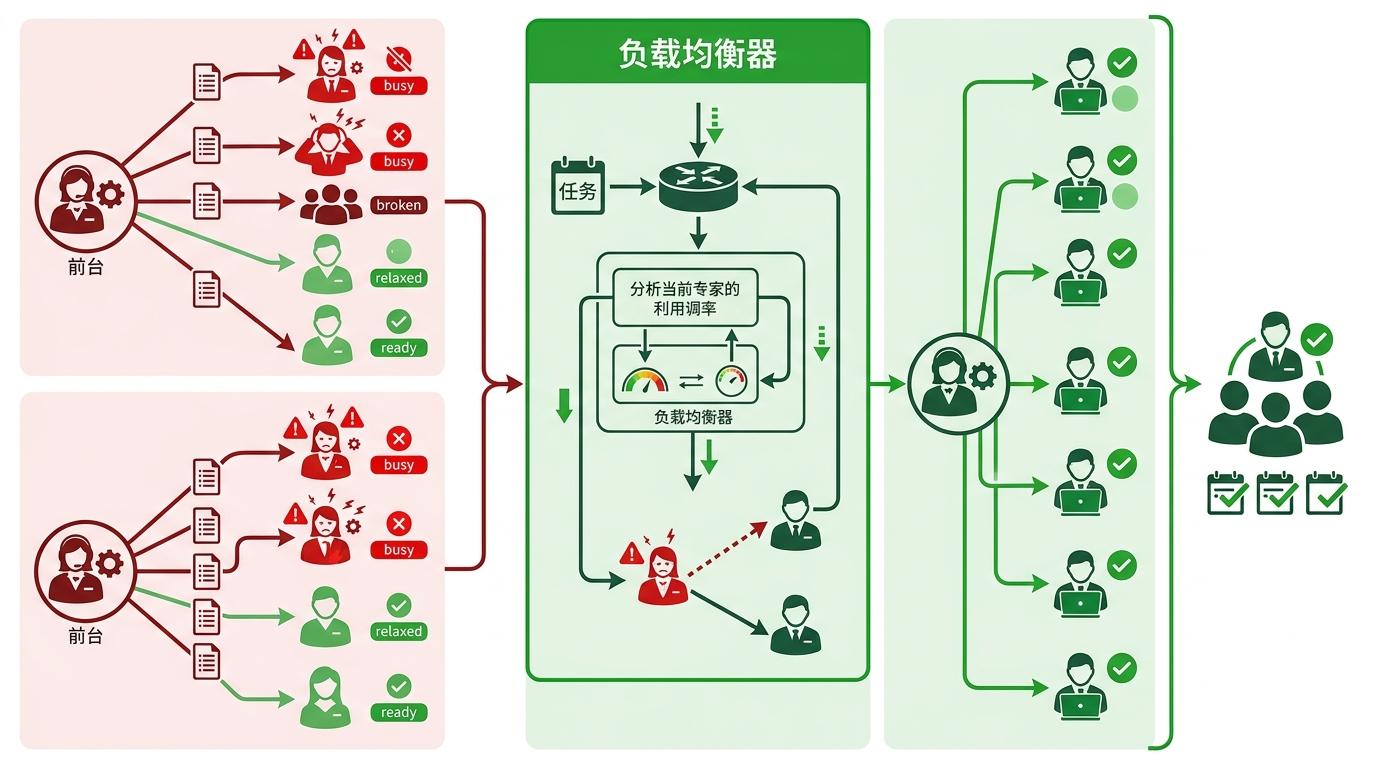
你可以把它想象成一家高效的咨询公司:客户来了不用全员开会,前台(路由器)会根据需求直接对接对应部门的专家,既节省时间又降低成本。实际数据更直观:同样是万亿参数规模,MoE模型的训练成本只有传统密集模型的1/5,推理速度却能提升3倍。
但这背后藏着一个技术难题:怎么让“前台”精准分配任务,避免某些专家忙到崩溃,另一些却闲得发慌?他们给路由器加了个“负载均衡器”,如果发现某个专家被调用得太频繁,就会稍微降低它的优先级,强迫任务分流到其他专家那里。就像公司里的项目分配,既要让专业的人做专业的事,也要保证每个人都有活干。
如果说MoE架构是他们突破算力瓶颈的第一步,那接下来的技术复用更像是一场心照不宣的协作。其中一家团队先搞出了MLA多头潜在注意力机制——简单说就是给AI的“短期记忆”做了个压缩包,原来要占100M内存的上下文信息,现在只需要10M就能存下,还不影响AI理解内容。另一家团队看到后直接把这个机制用到了自己的长文本模型里,瞬间解决了百万token上下文的内存爆炸问题。
没过多久,后者又推出了Muon二阶优化器,把AI的训练效率又提了一倍——相当于让学生做一套题就能掌握原来两套题的知识点。前者也很快跟进,把这个优化器用到了新一代模型的训练中。
这种“你进步我跟进”的模式,让他们的技术迭代速度比单打独斗快了30%。一位研究员说,他们甚至不需要刻意交流,看对方的论文就知道下一步该往哪走,“就像两个一起爬山的人,你拉我一把,我扶你一下,谁也不想被落下”。当然,这种协同也有局限:目前他们的底层架构还主要依赖国外芯片,虽然已经开始适配国产硬件,但要实现完全自主还有2-3年的路要走。
当同行们忙着靠AI聊天工具抢流量、赚快钱时,这两家团队却在做“吃力不讨好”的事:一个坚持开源所有核心技术,哪怕被别人拿去做商业产品;另一个把90%的资金都砸在底层架构研发上,连个像样的C端产品都没有。
2026年,其中一家团队启动首次外部融资,估值直接冲到200亿美元,但他们拒绝了某互联网巨头的投资——对方要求必须把技术优先给自家产品用。另一家团队更绝,创始人直接在内部信里说:“账上还有100亿,未来3年不考虑盈利,先把AGI的基础逻辑搞清楚。”
这种“反商业”的坚持,反而让他们成了资本眼里的香饽饽。一位投资人说:“现在的AI公司要么靠流量讲故事,要么靠技术赚快钱,但只有他们在做能改变行业规则的事——就像当年的特斯拉,不是造了一辆更好的燃油车,而是直接换了赛道。”
知春路的风吹过两家公司的办公楼,窗台上的绿植在夕阳下投下重叠的影子。没人知道他们谁会先摸到AGI的门槛,但可以肯定的是,他们已经走出了一条和美国同行不一样的路:不是靠无限的算力堆出超级模型,而是用架构创新把有限的资源用到极致。
当所有人都在讨论AI能赚多少钱时,这两个团队还在纠结“怎么让AI更高效地思考”。这或许就是中国AGI最珍贵的地方:在资本的喧嚣里,还有人愿意慢下来,做一些真正改变未来的事。
算力受限不是终点,而是创新的起点。