对抗知识焦虑,从看懂这条开始
App 下载
加密视频压缩后还能用,这项技术解决了监控隐私难题
东京都立大学|千叶大学|智能监控|加密视频|CFE-PPAR技术|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载东京都立大学|千叶大学|智能监控|加密视频|CFE-PPAR技术|AI产业应用|人工智能
想象一下:你小区的监控摄像头拍下了有人破坏公共设施的画面,云端系统要立刻识别出这个异常动作,但同时不能泄露视频里路过居民的脸和穿着——这是现在智能监控的刚需,也是个技术死结。之前的办法要么把视频模糊到看不清人脸,连动作也识别不准;要么把视频全加密,结果一压缩传输,不仅识别率跌到个位数,连警方取证都解不出清晰画面。2026年5月,千叶大学和东京都立大学的团队拿出了破局方案:CFE-PPAR,让加密视频既能被压缩到原大小的十分之一,又能保持和原视频几乎一样的识别准确率,解密后还能看清人脸。
你可以把普通视频加密想象成把文件搅成碎纸——安全是安全,但碎纸没法塞进压缩袋;而CFE-PPAR的加密更像给文件按8×8厘米的格子分块,每块单独旋转、翻面、换颜色,最后再把所有大块的顺序打乱。
它的核心是“压缩友好加密(CFE)”:先把每一帧视频切成16×16像素的“主块”,对应视频识别模型的最小处理单元;再把每个主块分成4个8×8像素的“子块”——这个尺寸刚好是H.264、JPEG这些压缩算法的基础处理单位。对每个子块,用密钥随机执行旋转、翻转、像素值反转、RGB通道打乱、子块内像素重排这5种可逆变换,最后再用另一组密钥打乱所有主块的顺序。
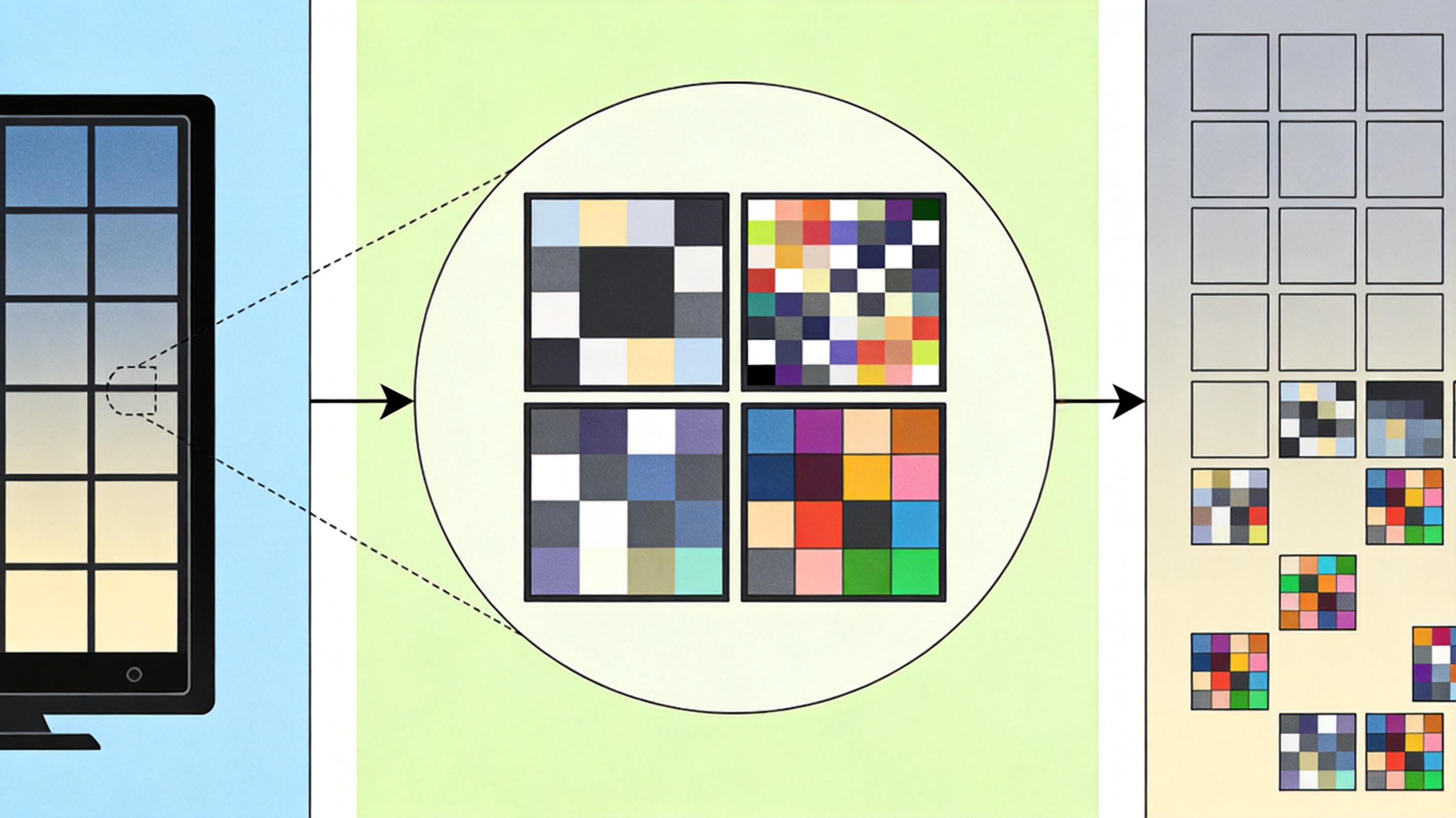
关键的巧妙之处在于:子块内部的像素相关性被完整保留了,压缩算法依然能识别出块内的重复信息进行压缩;但从整体看,视频已经变成了完全无法辨认的噪声。这种加密是无损可逆的,授权用户用密钥就能一步步还原出原视频。
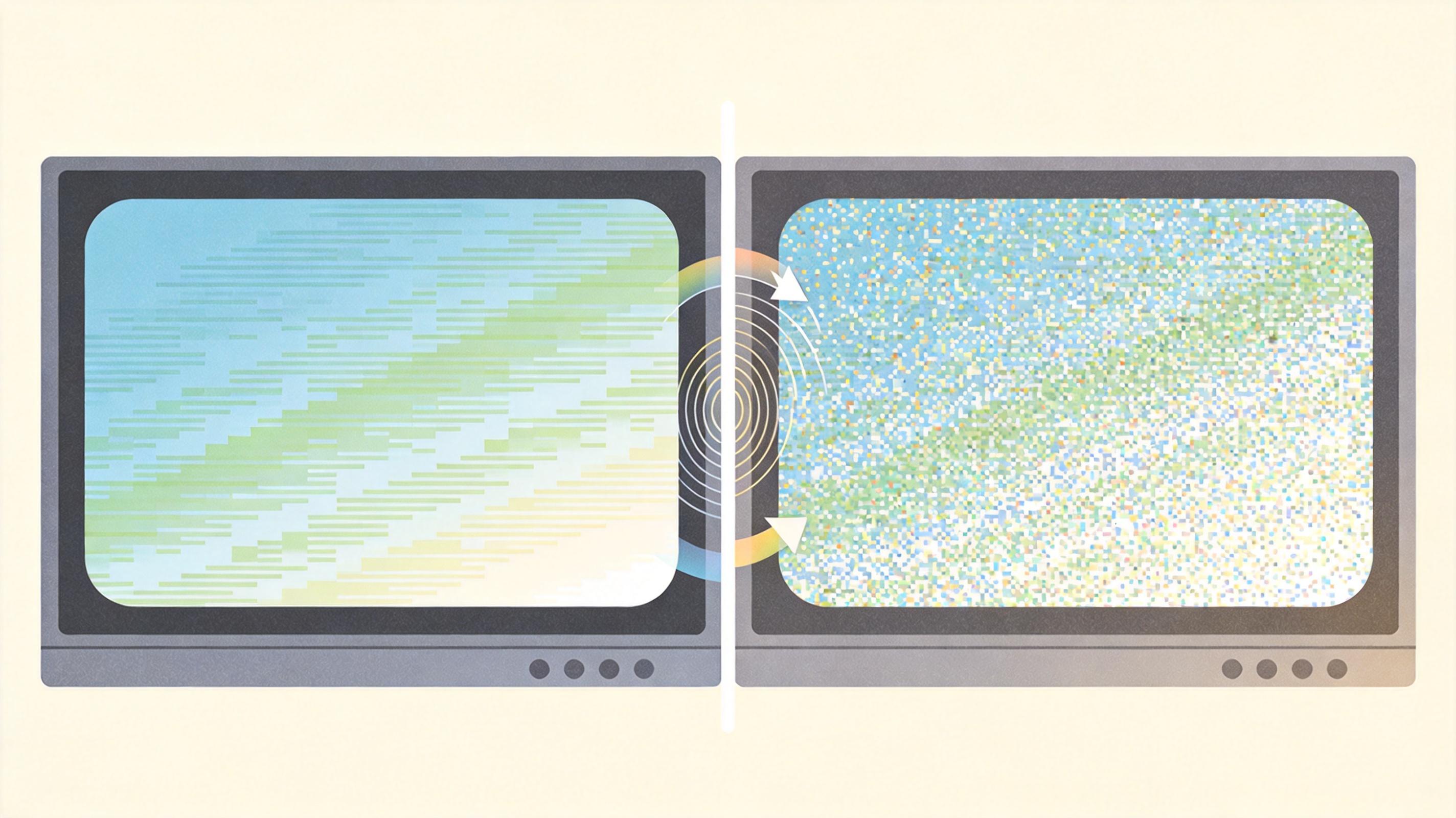
加密后的视频像素全变了,原本训练好的动作识别模型肯定“看不懂”——就像你学的是中文,突然给你一本用中文单词打乱顺序写的书,你也读不懂。CFE-PPAR的解决办法不是重新教模型读“加密书”,而是把模型的“词典”也按同样的规则打乱。
这就是“密钥依赖域自适应(KDDA)”:用加密视频的同一组密钥,对视频Transformer模型的输入层参数做完全对应的变换——把模型的3D卷积核也切成8×8的子块,执行和加密视频一样的旋转、翻转、通道打乱;把模型的位置编码,按主块打乱的顺序重新排列。
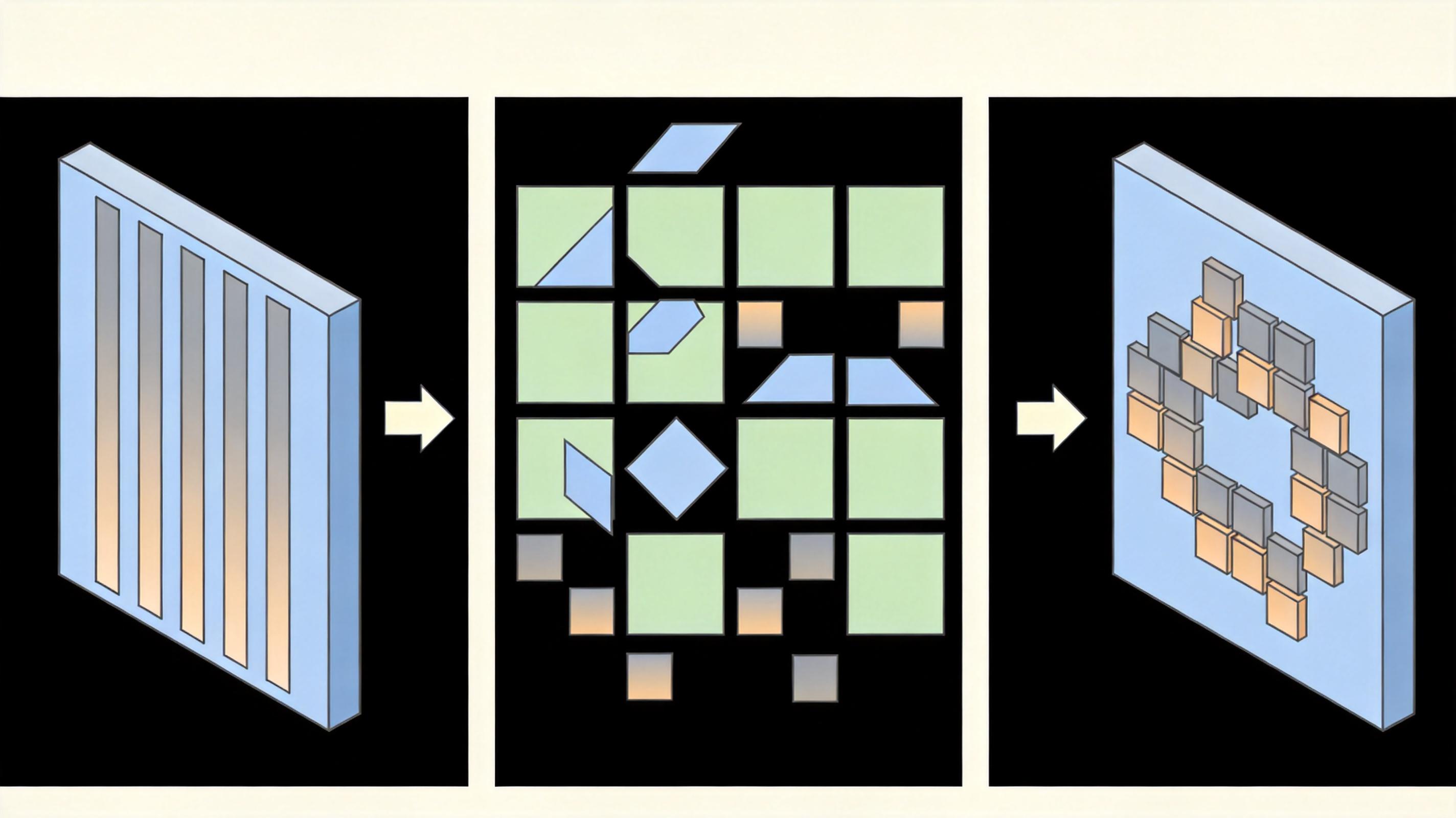
整个过程不需要重新训练模型,只是对预训练好的参数做一次“密钥校准”,模型就能直接在加密视频上进行动作识别。在UCF101数据集的测试中,未压缩时CFE-PPAR的识别准确率和原视频完全一致(92.92%);用H.264高码率压缩后,依然能达到92.52%,而传统加密方法的准确率直接跌到了12.18%。
CFE-PPAR的安全性也经过了严格测试。研究人员用“拼图攻击”——也就是让AI把加密视频的子块像拼图一样拼回原视频——来测试防御能力:在未压缩的情况下,用同一密钥加密所有主块的V1版本,确实能被拼出部分原画面;但给每个主块单独用不同密钥的V2版本,AI完全无法拼出有意义的内容。
更关键的是,实际应用中视频一定会被压缩。压缩过程会给视频带来不可逆的失真,相当于给每个子块都“磨了边”,AI再也找不到子块之间的拼接线索。测试显示,经过0.40 bpp低码率压缩后,不管是V1还是V2版本,拼图攻击都完全失效。
团队还采用了“一次一密”策略,每个视频用唯一的密钥组加密,彻底避免了密钥复用带来的已知明文攻击风险。解密后的视频质量也远超传统方法:高码率下PSNR超过30dB,能清晰辨认人脸和动作细节,完全满足取证需求。
在视频监控、云端视频分析的刚需下,隐私保护和数据实用性的矛盾已经存在了很多年。之前的技术要么牺牲隐私换效率,要么牺牲效率换隐私,始终没有找到两全的方案。CFE-PPAR的出现,第一次让“加密视频可压缩、可识别、可还原”从理论变成了现实。
更值得关注的是,它不是靠某一项突破性的新技术,而是把块级加密、密钥域自适应这些现有技术,精准地组合到了视频识别的场景中,踩中了压缩算法的“工作节奏”。这也给我们提了个醒:很多技术难题的破局点,往往不是颠覆式的创新,而是对现有技术的精准适配。
隐私保护的终极目标,从来不是把数据锁死,而是让数据在安全的前提下流动。