对抗知识焦虑,从看懂这条开始
App 下载
一次训练出百款模型,AI训练成本砍到6%
成本优化|训练算力|模型矩阵|弹性训练|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载成本优化|训练算力|模型矩阵|弹性训练|大语言模型|人工智能
当GPT-4级别的模型训练成本还在以亿美元为单位飙升时,有团队交出了一份颠覆行业的成绩单:用同规模模型6%的算力,训练出了性能接近国际顶尖水平的AI。这不是实验室里的理论推演,而是已经落地的工程方案——他们没有从零开始反复训练不同大小的模型,而是在一次训练中就“攒”出了一个覆盖从微型到大型的模型矩阵。怎么做到的?这背后藏着大模型行业从“堆参数拼算力”转向“提效率降成本”的关键拐点。
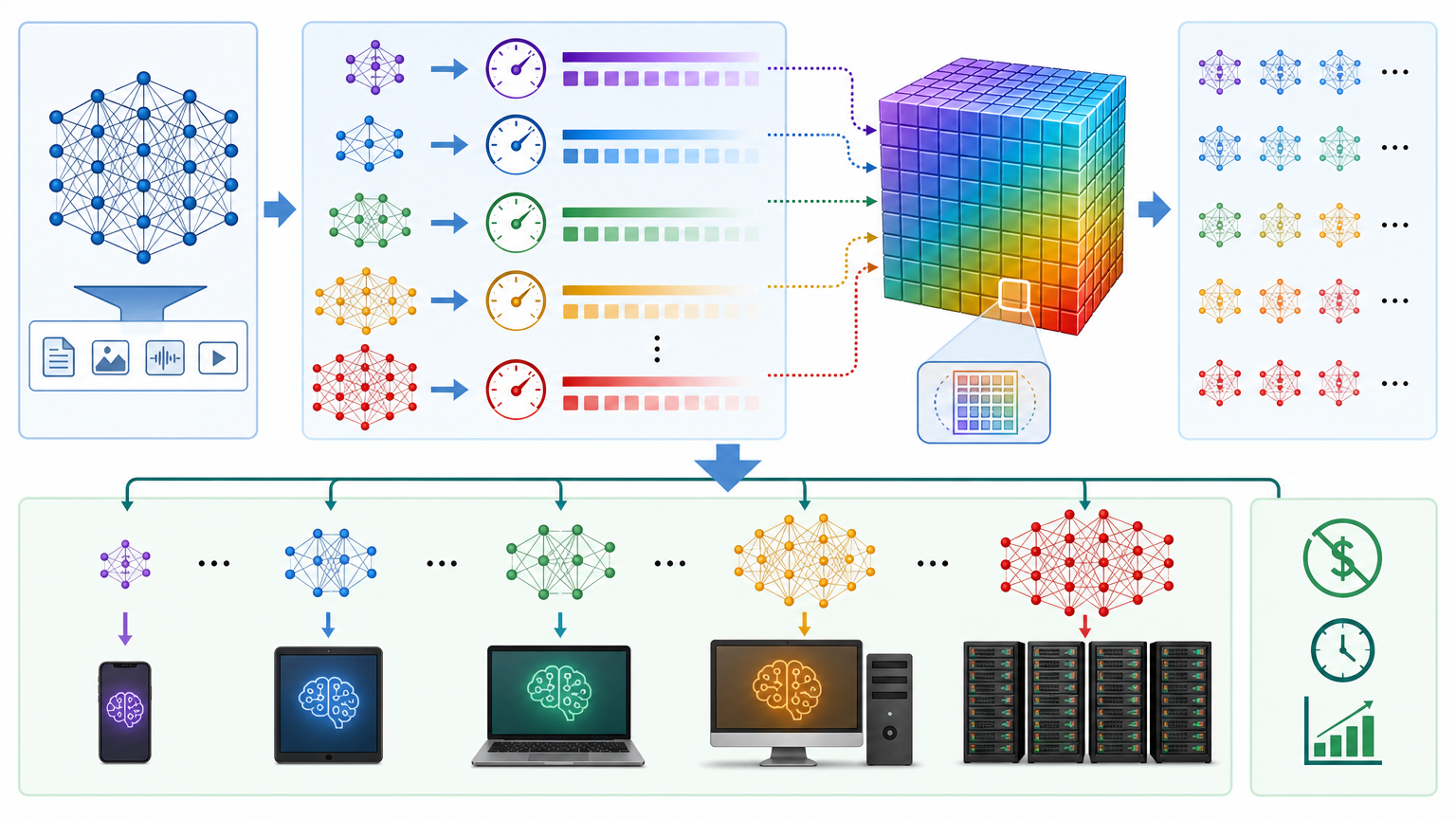
你可以把传统大模型训练想象成批量生产衣服:要做S、M、L三种尺码,就得开三条生产线,买三次布料,雇三批工人,成本翻三倍。而弹性训练更像做一件“变形衣”——只用一次布料、一条生产线,做出的衣服能根据需求自动拉伸或收缩成任意尺码。

这套叫Once-for-All的核心方法,简单说就是“先建母模型,再拆子模型”。训练时从最大规模的模型开始,通过动态采样技术,随机抽取不同层数、不同通道数的子模型进行同步优化。就像在织一件大毛衣的同时,随时抽出不同针数的线团,确保每一段线的松紧度都符合单独织成小毛衣的标准。
但真实的机制比这更精确:训练过程中,系统会给每一个可能的子模型都分配“训练权重”,确保母模型的参数能适配所有尺寸的子结构。最终产出的不是一个单一模型,而是一个包含上百亿种可能的“模型矩阵”——从手机能跑的微型模型,到服务器用的大型模型,都能直接从这个矩阵里提取,无需再花一分钱训练成本。
光有弹性训练还不够,要把成本压缩到6%,还得在整个训练流程上“挤水分”。团队用了三个关键动作:
第一招是拆分工序。把训练、推理、奖励计算、智能体循环四个原本绑定的环节彻底拆开,像工厂里的独立车间一样各自运转。比如推理环节算力不够,就单独加推理服务器,不用动训练的GPU集群;奖励计算慢了,就给这个模块单独扩容。各车间之间用高速网络传递数据,流水线重叠作业,整体训练时间直接缩短了三分之一。
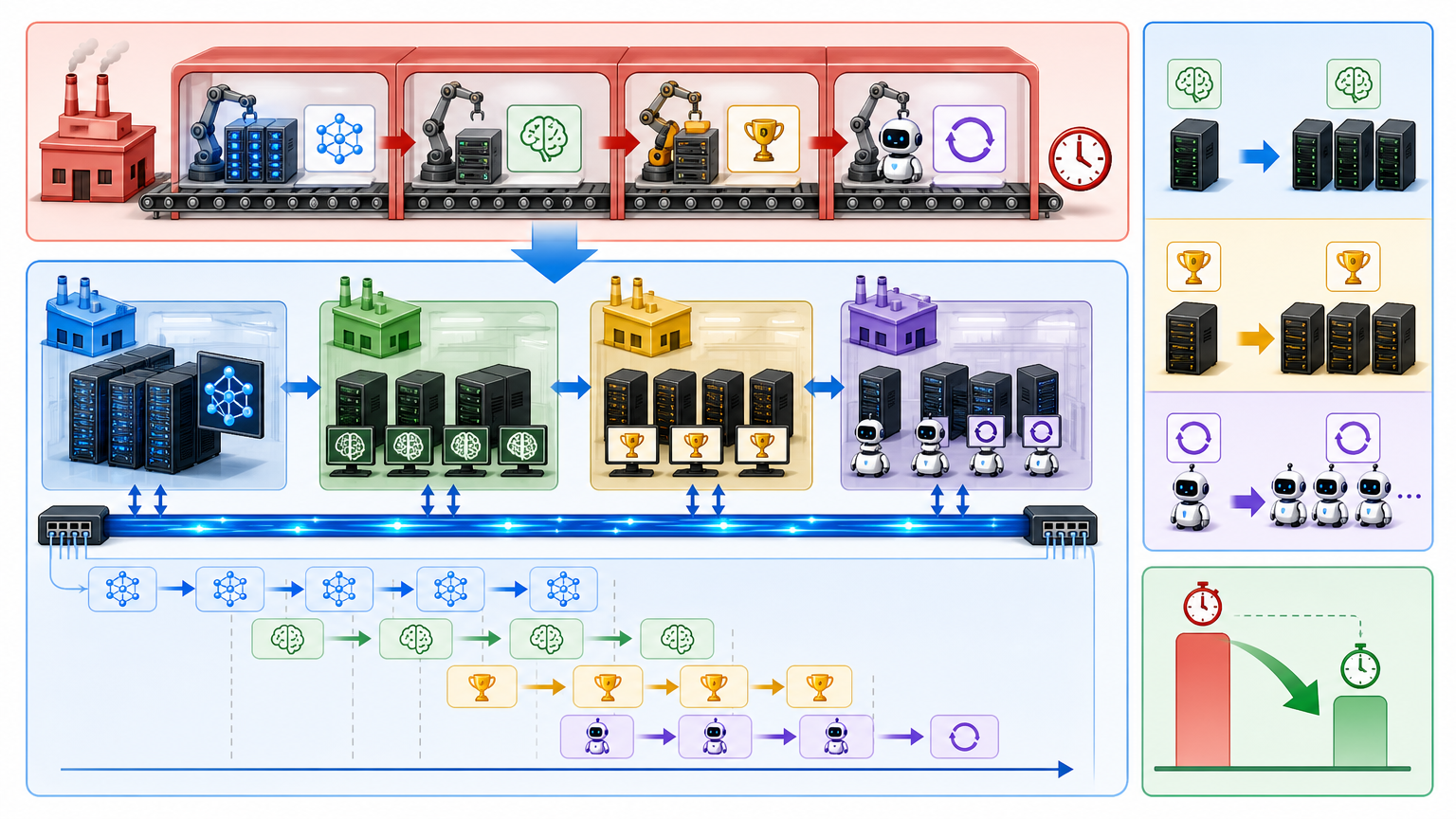
第二招是用低精度算准账。以前训练和推理用不同的精度标准,就像用尺子量布料却用秤裁衣服,容易出错。现在统一用FP8低精度算子库,就像换了一把既能量又能裁的精准工具——训练速度没变慢,关键指标的稳定性反而提升了50%,相当于用更少的电干了更准的活。
第三招是把闲置算力用满。GPU集群里的CPU资源以前大多闲着,现在把它们集中起来,专门处理代码验证、数据清洗这些不需要GPU的“杂活”,让GPU只专注于核心的模型训练。就像让厨师只负责炒菜,切菜、备菜的活交给助手,厨房的整体效率一下就提上去了。
解决了训练成本的问题,还有一个行业难题:想让AI同时擅长代码、推理、聊天,往往练好了这个就丢了那个,像在同时教一个孩子数学、画画和唱歌,容易顾此失彼。
团队的解法是把“专家训练”和“能力融合”拆开。先给AI打基础,用多领域数据做一次通用微调,让它具备基本的指令理解能力;再像培养专科医生一样,并行训练代码专家、推理专家、聊天专家,每个专家只专注自己的领域,互不干扰;接着用“在线策略蒸馏”技术,把所有专家的能力“浓缩”进同一个模型——就像把各科老师的笔记整合成一本复习资料,学生既能学到每个老师的专长,又不会混淆知识点。
最后,针对聊天、创意写作这类需要多样性的任务,再单独做强化学习。就像给复习资料加了一本“拓展阅读”,保证AI既能精准解题,又能灵活创作。这套流程下来,训练周期缩短了一半,还避免了不同能力之间的“打架”。
当大模型行业还在为“参数越大越好”的路径依赖烧钱时,这套弹性训练方案像一盆冷水,浇醒了“算力即正义”的迷思。它证明了,大模型的未来不是比谁能堆更多的GPU,而是比谁能用更少的资源做更多的事。
更值得关注的是,这种降本增效的技术正在降低AI的门槛——以前只有巨头能玩得起的大模型,现在中小企业甚至科研团队也能负担。这就像从只能定制高级西装,变成了能批量生产平价成衣,AI的普及速度会比我们想象的更快。
算力不是壁垒,效率才是未来。当AI不再是少数巨头的奢侈品,它才能真正渗透到每个行业的毛细血管里,变成普通人能用、好用的工具。