对抗知识焦虑,从看懂这条开始
App 下载
算力正在变成水电,芯片却越分越细
AI接口|token消耗|GPU芯片|Agent机器人|大模型流量|半导体技术|AI算力|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI接口|token消耗|GPU芯片|Agent机器人|大模型流量|半导体技术|AI算力|前沿科技|人工智能
2026年春节前后,国内大模型的流量突然暴涨了一倍——不是因为国内用户突然爱上了AI聊天,而是海外的Agent机器人在集体“薅羊毛”。这些自动运行的程序像不知疲倦的工人,批量调用国内更便宜的AI接口,把token(AI处理文本的最小单位)消耗量推到了指数级。没人再关心后台跑的是哪款GPU,就像你拧开自来水龙头时,不会在意水是从哪个水库来的。当算力彻底变成了“看不见的商品”,一场关于芯片和规则的暗战才刚刚开始。
你可以把算力的封装历程,类比成手机的进化:从需要自己焊电路板的大哥大,到只要点图标就能用的智能手机——每一层封装都把复杂的底层逻辑藏起来,只给用户留一个最简单的接口。
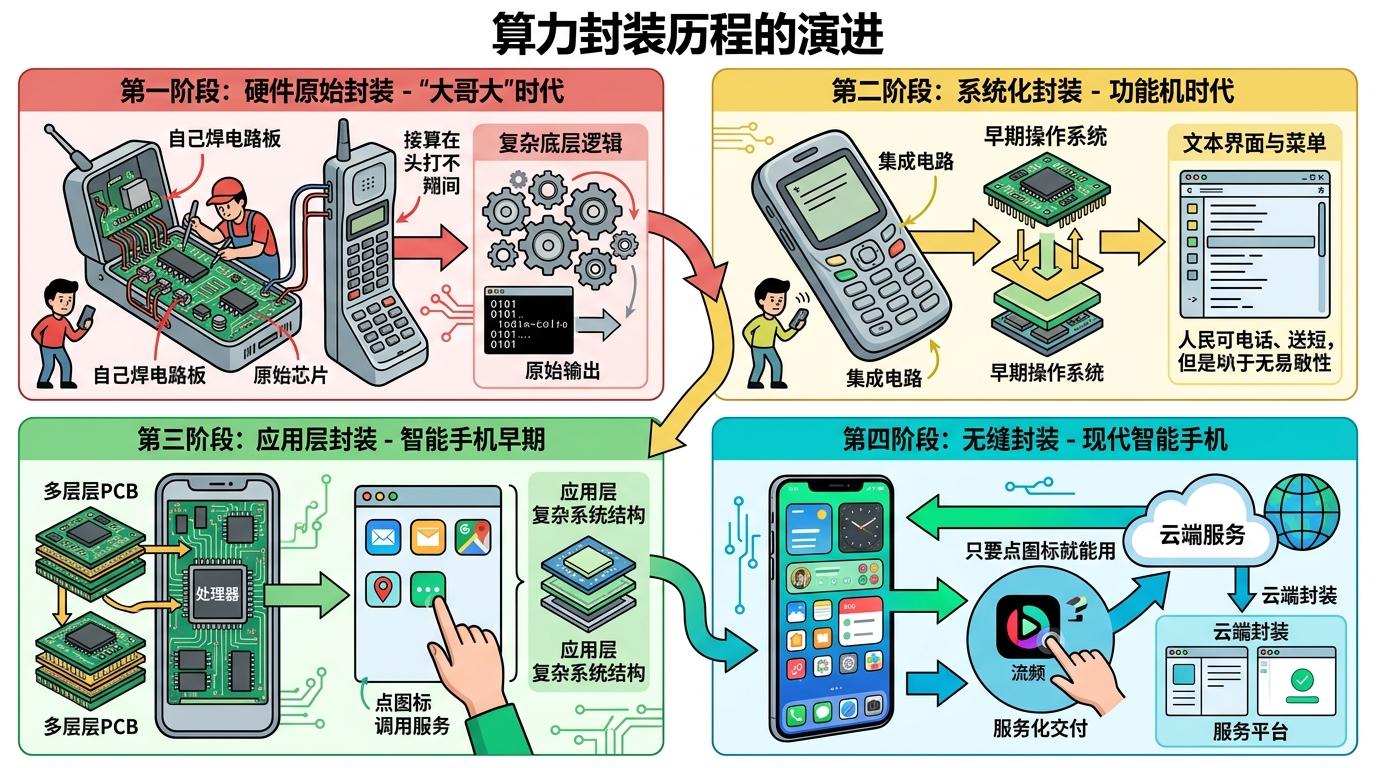
现在,这个接口变成了token。
这是个很聪明的设计:不管你是做量化交易需要微秒级延迟,还是医院做影像诊断要准确率,抑或是工厂质检要稳定吞吐,所有需求最终都被换算成“处理多少个token”。就像用电按度数收费、用水按吨数收费,token成了算力的统一计价单位,不同质量的算力对应不同的token价格,形成了从免费到超高速的五层阶梯。
但这背后藏着一个更关键的变化:AI的交互模式已经从“人机对话”变成了“Agent对Agent的自动协作”。人用AI是聊几句天,消耗的token是线性的;但Agent用AI是跑完整的工作流,比如自动生成报表、调度物流、甚至写代码,token消耗是指数级的。这种爆发式需求,逼着算力必须像水电一样随取随用,而封装,就是把算力变成“公共服务”的必经之路。
当token变成了硬通货,芯片的命运也被彻底改写了。
过去大家默认GPU是AI的“万能钥匙”,但现在才发现,训练和推理根本是两种完全不同的活儿——就像火车和快递,一个要拉得重,一个要跑得快。训练是计算密集型的,需要GPU这种“大卡车”一次性处理成千上万的并行任务,靠的是暴力计算堆出来的效率;但推理是存储密集型的,要的是低延迟、快响应,用GPU做推理,就像用大卡车送快递,灵活度不够,还浪费油。
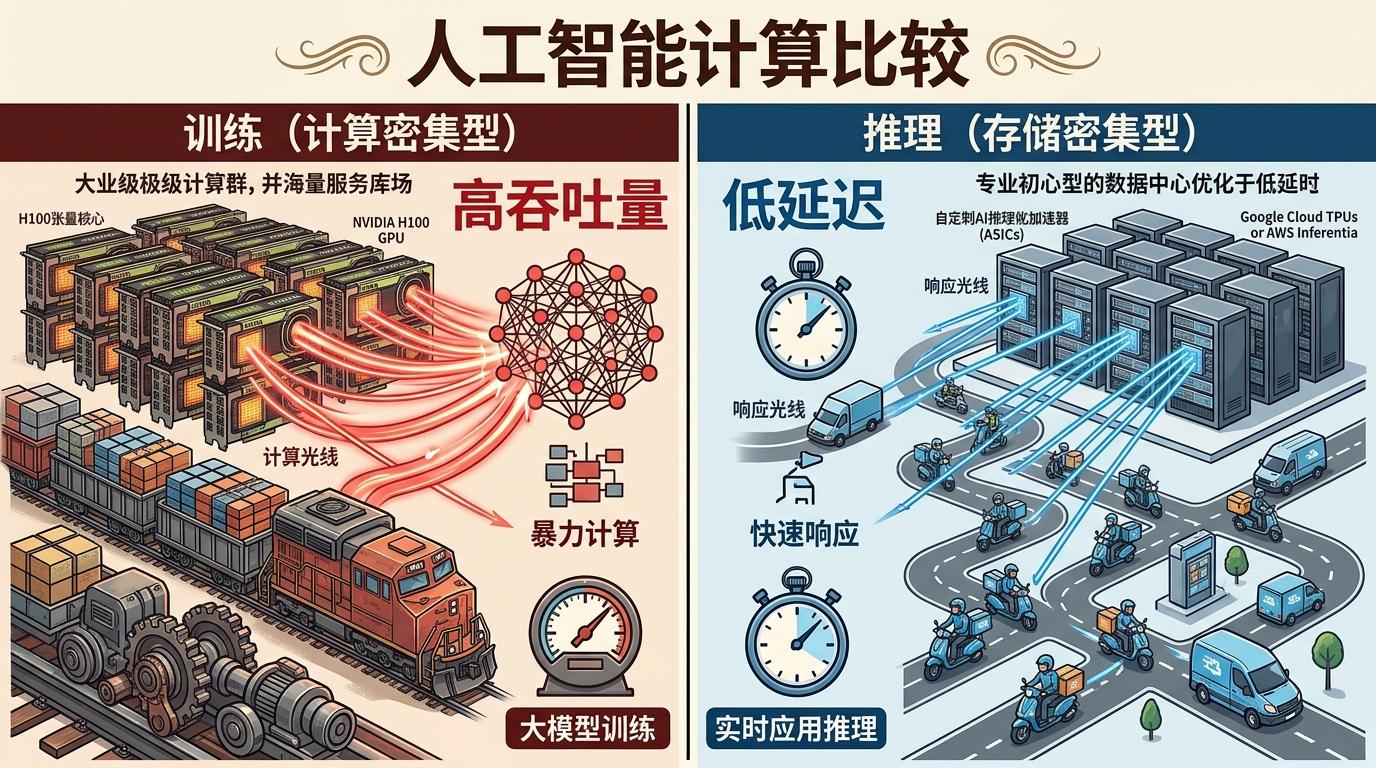
于是芯片开始分家:
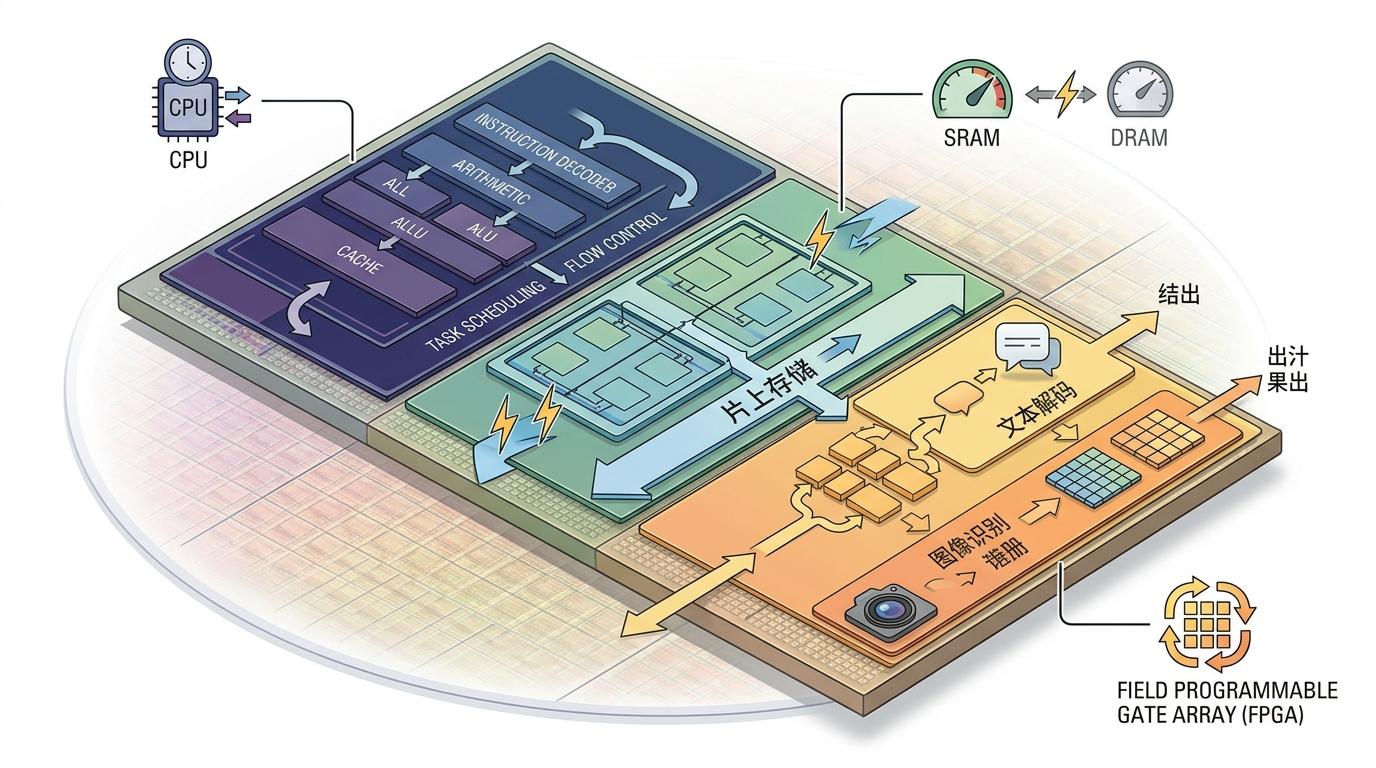
这种分化不是技术爱好者的狂欢,而是被市场需求逼出来的——当每一个token都要算成本,没人愿意为了“万能”而浪费算力。
当算力的“水电网络”越来越完善,创业公司还有机会吗?
答案是肯定的,但机会不在“造卡车”,而在“开快递公司”。那些大玩家擅长的是搭建标准化的算力网络,解决的是通用需求,但在高度定制化的边缘场景,比如工厂的质检摄像头、自动驾驶的车载芯片、手术机器人的感知模块,标准化的芯片就不够用了——这些场景需要的是“量身定制”的算力,既要满足低延迟,又要控制成本,还要能适应复杂的环境。
可重构芯片就是这个缝隙里的机会。它不像GPU那样只能干一种活,也不像专用芯片那样只能干一种活,而是能根据任务动态调整硬件逻辑,比如今天处理工厂的图像质检,明天就能切换成自动驾驶的传感器数据处理,相当于一个“可变形的快递员”,既能跑得快,又能扛得动。
更重要的是,这是少数几个国内与国际差距不大的领域。当大玩家在搭建“水电网络”的时候,创业公司可以在细分场景里做“分布式发电站”——不需要和大玩家抢通用市场,只要把一个场景的算力效率做到极致,就有了自己的生存空间。
当算力彻底变成了水电,我们不用再关心水管里流的是哪条河的水,只需要关心水够不够、压力够不够、价格合不合理。但芯片的分化不会停止,反而会越来越细——就像水电网络背后,有不同类型的发电站、不同材质的管道、不同规格的水龙头。
封装让算力变平,分化让效率变高。
未来的AI世界,不会是某一种芯片的天下,而是一个由不同算力组件组成的生态系统:大玩家搭骨架,创业公司填血肉,最终让每一个token都用在刀刃上。毕竟,当算力真正变成了基础设施,我们需要的不是最好的芯片,而是最适合的算力。