对抗知识焦虑,从看懂这条开始
App 下载
自动驾驶跨域不懵了,PanDA靠这两招搞定
无标注环境|多模态感知模型|跨域感知|PanDA框架|自动驾驶|人工智能
对抗知识焦虑,从看懂这条开始
App 下载无标注环境|多模态感知模型|跨域感知|PanDA框架|自动驾驶|人工智能
想象一下:你的自动驾驶车在上海的晴天里开得稳稳当当,能精准识别每一个行人和外卖车;可一开到新加坡的雨夜,它突然就像近视加散光,连路边的公交都差点当成护栏。这不是科幻片里的故障,而是自动驾驶感知系统的「日常崩溃」——当训练时的熟悉场景(源域)换成完全陌生的新环境(目标域),模型的性能会断崖式下跌。给新场景重新标注数据?成本高到像给每一条街道都拍一次高精度3D电影。直到新加坡团队的PanDA框架出现,它第一次让自动驾驶车在「无标注新环境」里,也能像老司机一样认路。
要解决跨域崩溃,得先搞懂问题根源:自动驾驶的多模态感知模型(同时用摄像头和激光雷达)太「娇贵」——训练时两个传感器都完美工作,一旦到了雨夜,摄像头模糊、激光雷达点云稀疏,模型就像突然被抽走了一半感官,直接宕机。
PanDA的第一招「非对称多模态丢弃(AMD)」,就是专门治这个「娇贵病」的。你可以把它想象成驾校的「极端路况训练」:在有标注的源域数据上,刻意模拟传感器失效——随机把摄像头图像里的物体边界抠掉一块,或者把激光雷达点云里的实例内部数据删掉,而且每次只坏一个传感器,要么瞎眼要么聋耳,逼模型必须学会用剩下的那个感官补全信息。
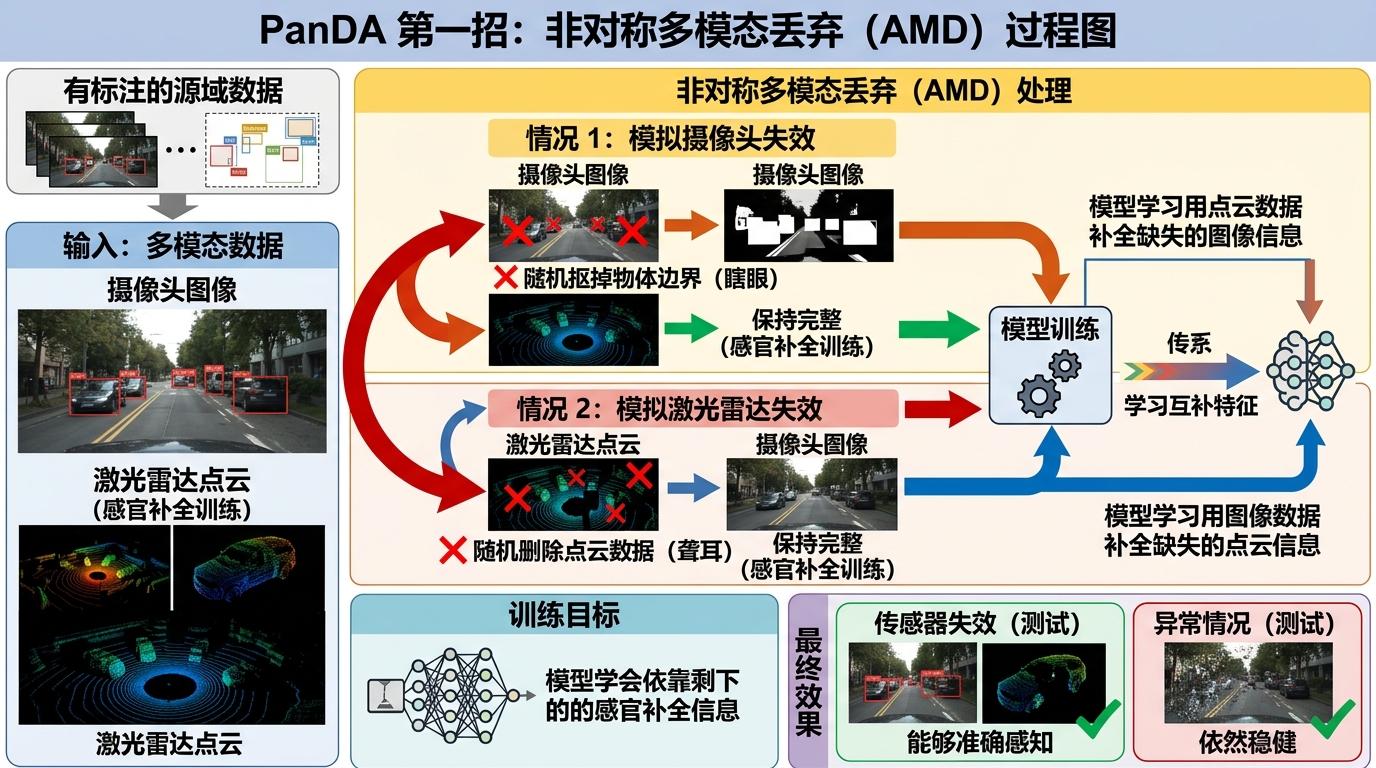
比如训练时,它会50%概率随机让摄像头「看不见」行人身后的边界,70%概率让激光雷达「扫不到」汽车的侧面点云。这种「结构化退化」不是乱删数据,而是精准针对全景分割最依赖的边界和实例区域,让模型在训练时就练出「单感官也能认全路」的本事。实验数据显示,仅这一招,就让模型在跨域场景下的全景质量(PQ)提升了8%以上。
无监督域适应的核心难题,是如何用无标注的目标域数据训练模型——传统方法靠「伪标签」,也就是让模型自己给自己打标签,但这种标签往往像草稿画,边界模糊、类别错误,甚至把「树」标成「路灯」。
PanDA的第二招「双专家伪标签细化(DualRefine)」,就是给这些草稿式的伪标签做「整容手术」。它找来两位「专家」:一位是3D几何专家,用激光雷达点云的聚类算法(HDBSCAN)把空间里形状一致的点聚成「超点」——这些超点不受天气、光照影响,就像物体的「骨骼」;另一位是2D视觉专家,用预训练的视觉基础模型(Grounding DINO+SAM)给图像做精准分割,相当于物体的「皮肤纹理」。
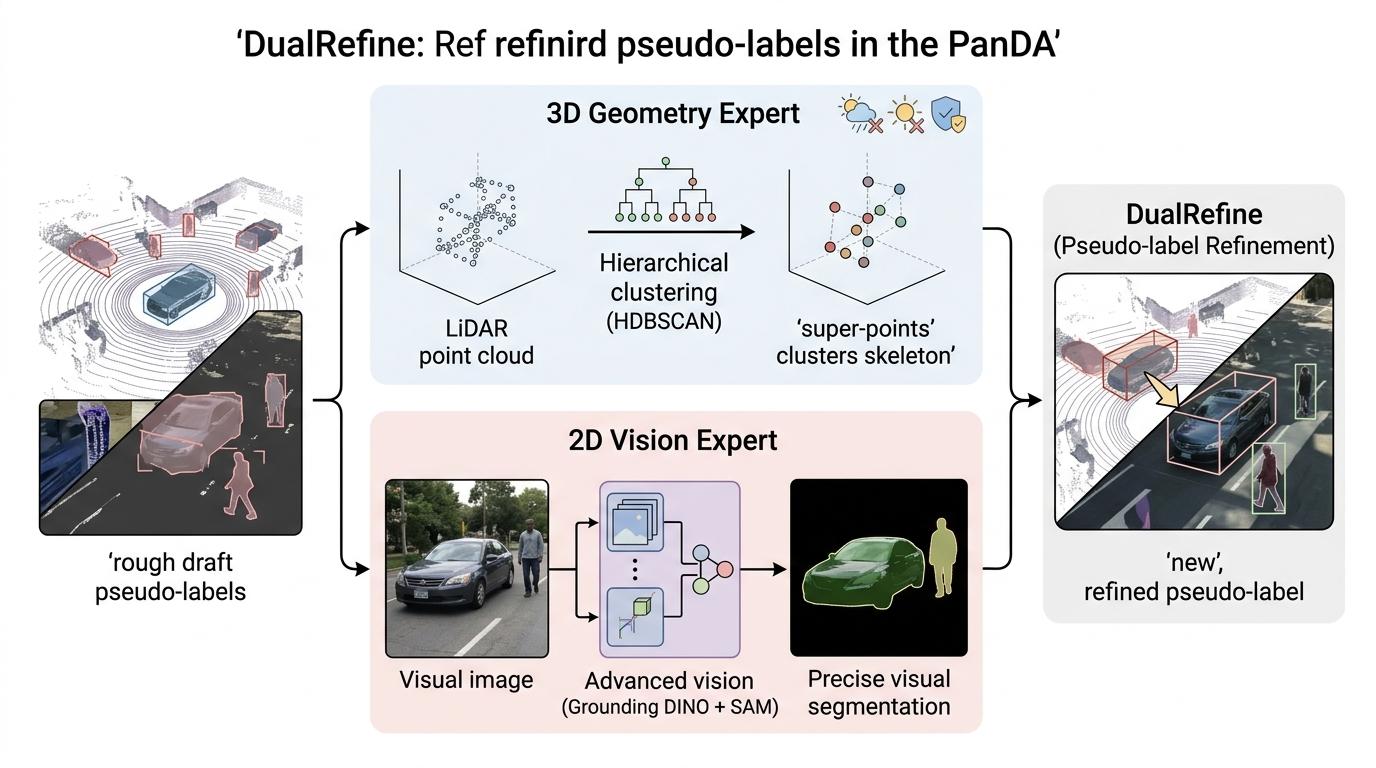
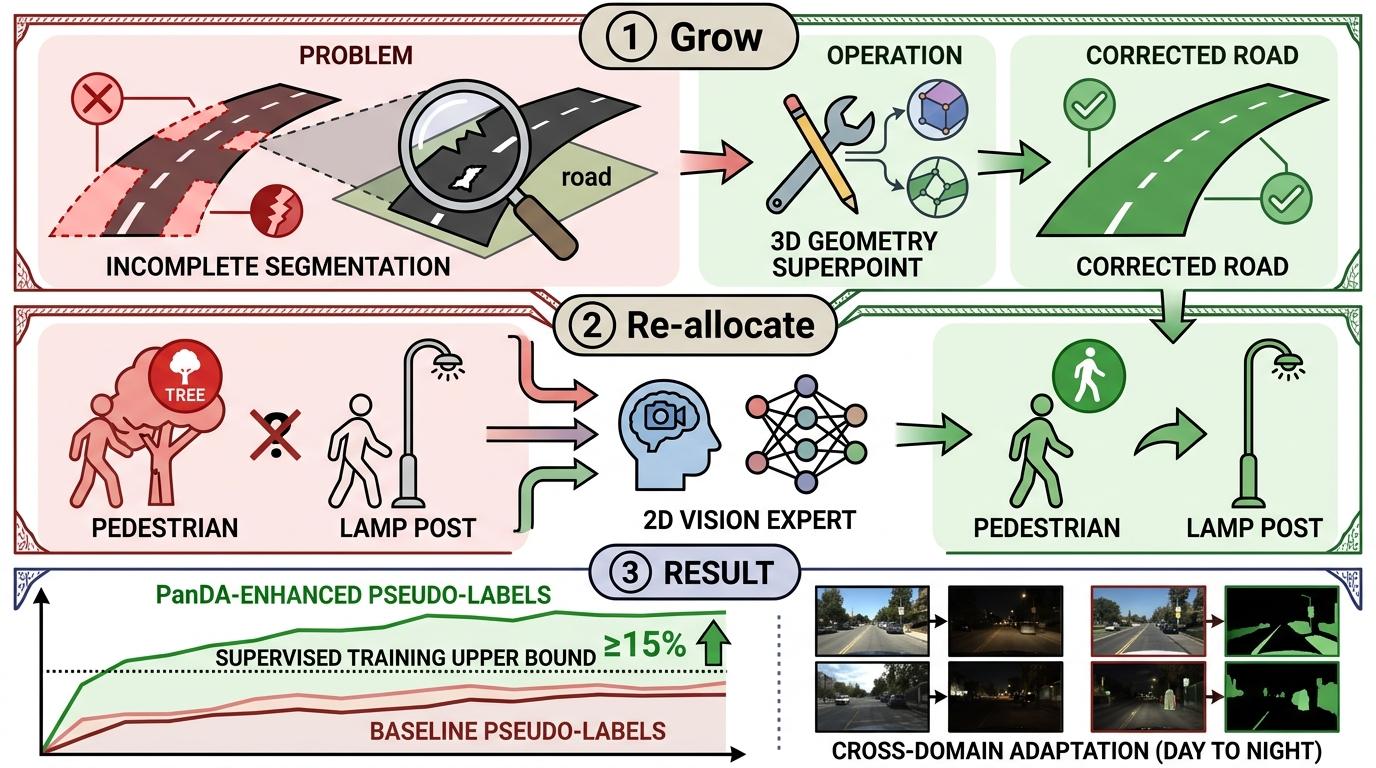
具体操作分两步:第一步「生长」,针对背景类(比如道路、草地)的伪标签断裂问题,用3D几何超点把断裂的部分补全,就像给破洞的布缝上补丁;第二步「重分配」,针对物体类(比如行人、汽车)的类别错误,用2D视觉专家的判断纠正标签,把标错的「树」改回「路灯」。经两位专家把关后的伪标签,准确率提升了15%以上,甚至在白天到黑夜的跨域测试中,PanDA的性能超过了有监督联合训练的上限——这意味着,它靠自己学的东西,比有人教的还准。
和之前的3D语义分割域适应方法比,PanDA的优势不止在模块创新,更在它真正理解了「全景分割」的核心需求——不仅要知道「这是什么」(语义),还要知道「这是哪一个」(实例)。传统方法只解决了语义层面的跨域对齐,却没顾及实例边界的完整性,就像能认出「车」,但分不清是一辆还是两辆。
PanDA的均值教师架构也功不可没:学生模型在源域和细化后的伪标签上训练,教师模型用学生权重的指数移动平均更新,相当于一个经验丰富的老司机在旁边不断纠正新手的错误。这种半监督学习范式,既保证了伪标签的稳定性,又让模型能快速吸收新环境的知识。
在最极端的跨数据集测试(从SemanticKITTI到nuScenes)中,传统基线方法的PQ只有1.2%,几乎完全失效,而PanDA的PQ达到了54.5%——相当于从完全失明恢复到了0.8的视力。
PanDA的出现,不止是自动驾驶感知技术的一次突破,更给「如何让AI适应真实世界」提供了新的思路:与其让AI在完美的实验室环境里当「优等生」,不如先把它扔进「恶劣环境」里练出「抗造能力」;与其依赖昂贵的标注数据,不如让AI学会用多模态的「专家知识」自我纠错。
未来的自动驾驶车,或许不用再依赖高精地图的「保姆式导航」,而是能像人类司机一样,到任何陌生城市、任何恶劣天气里,都能快速适应、安全驾驶。让AI先经历「挫折」,再学会「成长」,这才是真正的通用智能。