对抗知识焦虑,从看懂这条开始
App 下载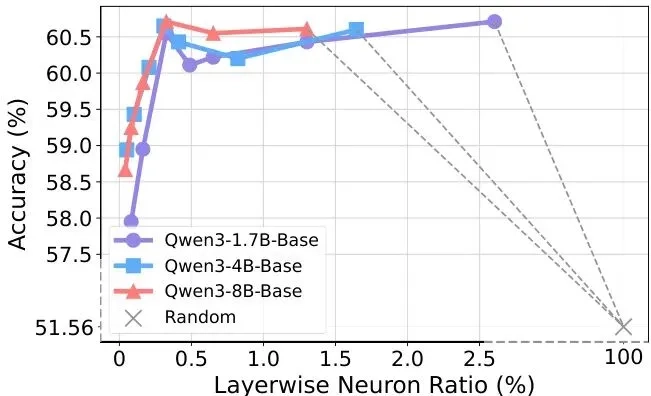
从黑箱到透视:用神经元激活图精准选数据
可解释性|模型能力提升|数据筛选|神经元激活图|NAG方法|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载可解释性|模型能力提升|数据筛选|神经元激活图|NAG方法|大语言模型|人工智能
你有没有过这种体验:明明给大模型喂了一堆“高质量”数据,它却偏偏学不会你要的那项能力——比如让它精通法律推理,它反倒把散文写得愈发华丽?这不是模型笨,是你选的“柴火”不对味。传统数据筛选要么靠模糊的“质量评分”,要么靠黑箱般的文本相似度,就像隔着衣服猜功夫,既不准也说不清。2026年4月,一套名为NAG的方法打破了这个困局:它直接“透视”大模型内部的神经元激活模式,精准挑出能让模型练对“功夫”的数据,平均性能提升近5%,还能把选数据的逻辑明明白白摊在你眼前。
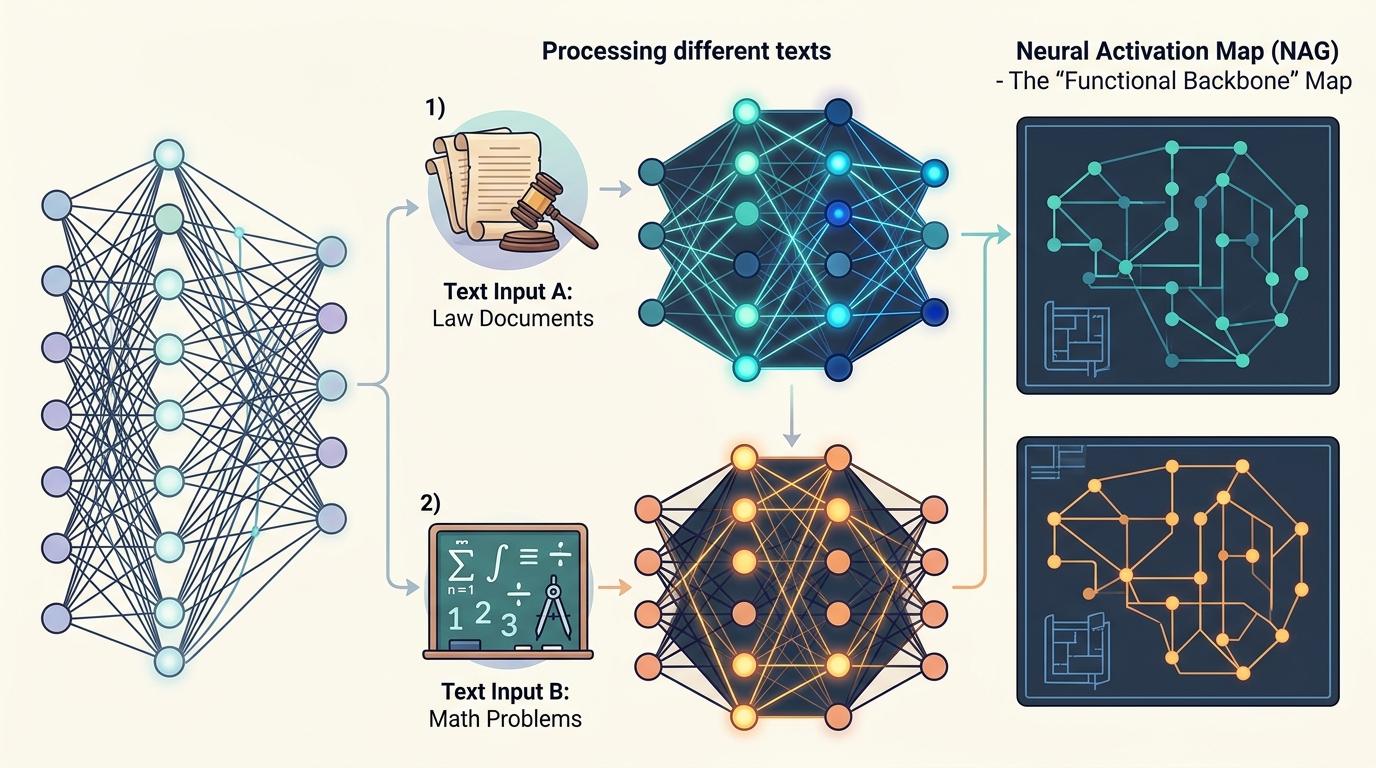
你可以把大模型想象成一个有百万个开关的工具箱——处理不同文本时,会触发不同的开关组合:读法律条文时,“法条解析开关”会密集跳动;算数学题时,“逻辑演算开关”会持续点亮。NAG,也就是神经元激活图,做的就是把这些被触发的开关记录下来,形成一张稀疏的“功能骨干图”。
它的实现分三步:首先量化每个神经元的影响力——就像测试每个开关对最终结果的作用大小;然后在模型每一层选出最关键的0.3%神经元,组成跨层的激活图;最后用目标任务样本的激活图做“模板”,给候选数据打分:激活的神经元越贴合模板,数据对任务就越有用。
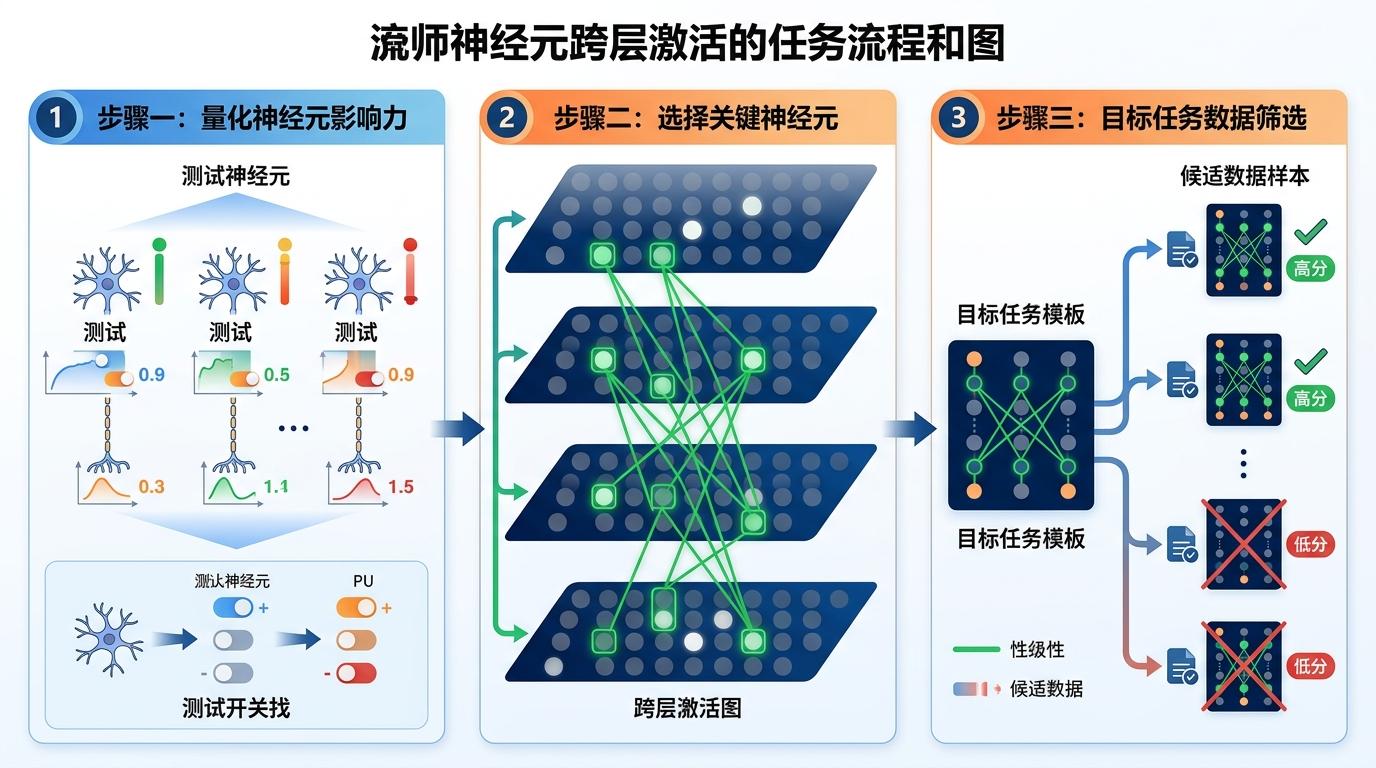
这个过程完全不需要额外训练,只用现成的大模型当“探针”。更妙的是,它选的不是表面相似的文本,而是能触发相同核心计算路径的数据——就像找同样会用“逻辑演算开关”的题,不管是数学题还是经济分析,只要触发的开关一致,就是好数据。
在6个经典任务的测试中,NAG的表现远超传统方法:单任务场景下,比随机采样平均提升4.9%,在常识推理任务HellaSwag上更是暴涨9%;比通用质量筛选的FineWeb-Edu平均高2.4%,证明“好数据”不等于“对的数据”;就连和基于文本嵌入的SOTA方法BETR比,也能平均领先1%。
最能体现优势的是多任务场景:BETR在混合目标下性能暴跌,甚至不如随机采样,而NAG依然能保持3.6%的平均提升。这是因为它抓的是深层的“功能骨干”,而非表面的语义相似——就算同时要学法律和数学,它也能精准挑出分别触发对应神经元的数据,不会互相干扰。
更硬核的验证来自“神经元敲除实验”:关闭NAG选出的仅0.12%的神经元,模型性能直接暴跌23.5%;而随机关闭同样数量的神经元,性能几乎没变化。这意味着NAG真的抓住了模型的“命门”——那极少数神经元就是模型处理任务的核心路径。
当然,NAG也不是完美的。它最大的局限是计算成本——虽然不用训练,但要给海量数据做神经元激活分析,对超大规模数据池来说仍是不小的开销。而且目前它只针对文本模型设计,面对图像、音频等多模态数据,还得重新定义“神经元激活图”的形态。
不过这些局限也正是未来的方向:比如用更高效的近似计算降低成本,或者给视觉Transformer的patch令牌、音频模型的频谱神经元设计对应的激活图;再比如让“探针”模型动态更新——随着大模型能力提升,它对关键神经元的认知也会变化,实时调整选数策略。
更重要的是,NAG的出现让我们对大模型的理解又深了一层:原来模型处理任务的核心路径是极度稀疏的,那0.12%的神经元就决定了大部分性能。这种“功能骨干”的发现,不仅能优化数据筛选,还能为模型剪枝、可解释性研究打开新的思路。
当我们还在为大模型的“黑箱”属性头疼时,NAG给了我们一把钥匙——它没有试图绕过黑箱,而是直接打开了一扇透视窗,让我们能看到模型内部真正在运作的核心。从“凭经验选数据”到“按模型的核心逻辑选数据”,这不仅是效率的提升,更是AI研发思路的转变:与其盲目喂数据,不如先搞懂模型到底需要什么。
选对数据,比喂更多数据更重要。这句话不仅适用于大模型训练,也适用于所有需要精准匹配的场景——毕竟,找到对的“开关”,比堆更多的“开关”有用得多。