对抗知识焦虑,从看懂这条开始
App 下载
烧光千亿后,OpenAI把算力用在了刀刃上
AI工作流|个人助理AI|GPU资源分配|Sora|OpenAI|AI算力|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI工作流|个人助理AI|GPU资源分配|Sora|OpenAI|AI算力|人工智能
2026年4月的一个下午,OpenAI的工程师们关掉了Sora的大部分训练节点——这款曾让全网惊叹的视频生成工具,如今只能分到公司算力池里的残羹冷炙。外界哗然,说这家AI巨头要从消费者市场彻底退守B2B。但很少有人注意到,同一时间,他们把所有能调动的GPU,都砸向了两个看起来不那么“酷炫”的方向:一个能记住你所有习惯的个人助理,和一套能接管80%工作的AI工作流。没人知道这步棋是对是错,但所有人都清楚:OpenAI手里的算力,已经不够再支撑一场“全面开花”了。
你可以把AI公司的算力池想象成一个刚发工资的钱包——每一分钱都要花在刀刃上,而OpenAI的钱包虽然鼓,却要养一群嗷嗷待哺的“吞金兽”。联合创始人Greg Brockman在访谈里把这个过程形容为“最残酷的优先级排序”:公司内部清单的顶端只有两件事,剩下的项目要么排队,要么直接被砍掉。
Sora不是第一个被牺牲的。这款能生成60秒视频的工具,每生成一帧画面消耗的算力,够ChatGPT回答上千次提问。在“能直接创造收入的推理模型”和“暂时看不到盈利点的视频生成”之间,OpenAI选了前者。这不是退守B2B,而是在算力的硬天花板下,放弃了“既要又要”的幻想。
更关键的是,他们把算力集中投向了一个听起来有点抽象的目标:统一AI层。简单说,就是把聊天、写代码、控制浏览器的能力,全部塞进同一个入口——就像把手机里的所有APP,都整合进了一个智能助手。比如你忘记怎么设置Mac的屏幕热角,不用查教程,直接说一句,AI就能帮你完成操作。这背后的逻辑很直白:与其让人类适应机器,不如让机器迁就人类。
在砍掉Sora的同时,OpenAI把所有剩余算力,都砸给了一个叫Spud的新模型。这不是GPT-5的换皮,而是他们憋了两年的大招——用Brockman的话说,这模型有“大模型气息”:当你提问时,它不会再答非所问,而是像一个真正的助手,能听懂你的弦外之音。
Spud的核心突破,是把AI的任务覆盖率从20%拉到了80%。过去的AI只能做一些碎片化的工作,比如写一段文案、改一行代码;但Spud能接管一整套工作流:从写项目提案,到做数据分析,再到生成汇报PPT,它能一口气完成。这就像从“只会拧螺丝的工人”,升级成了“能管整个车间的工头”。
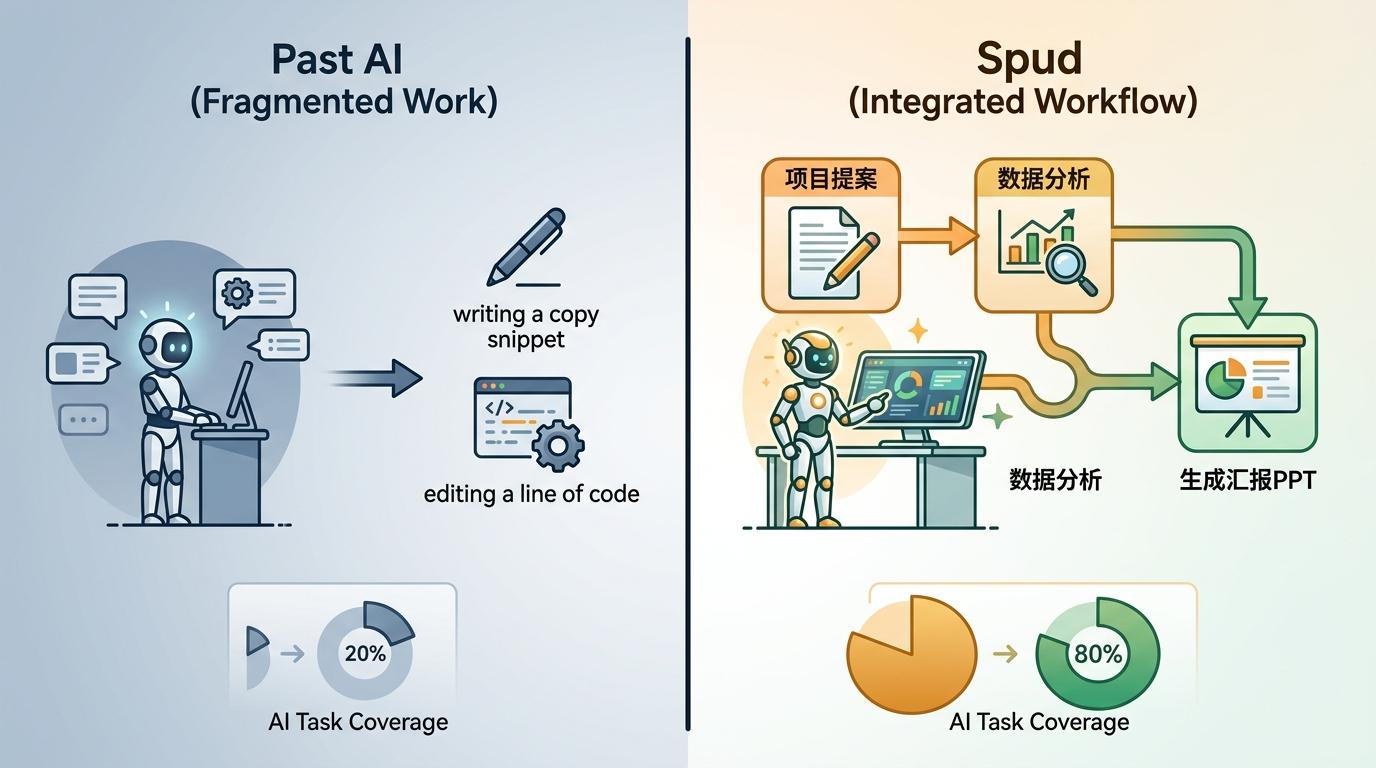
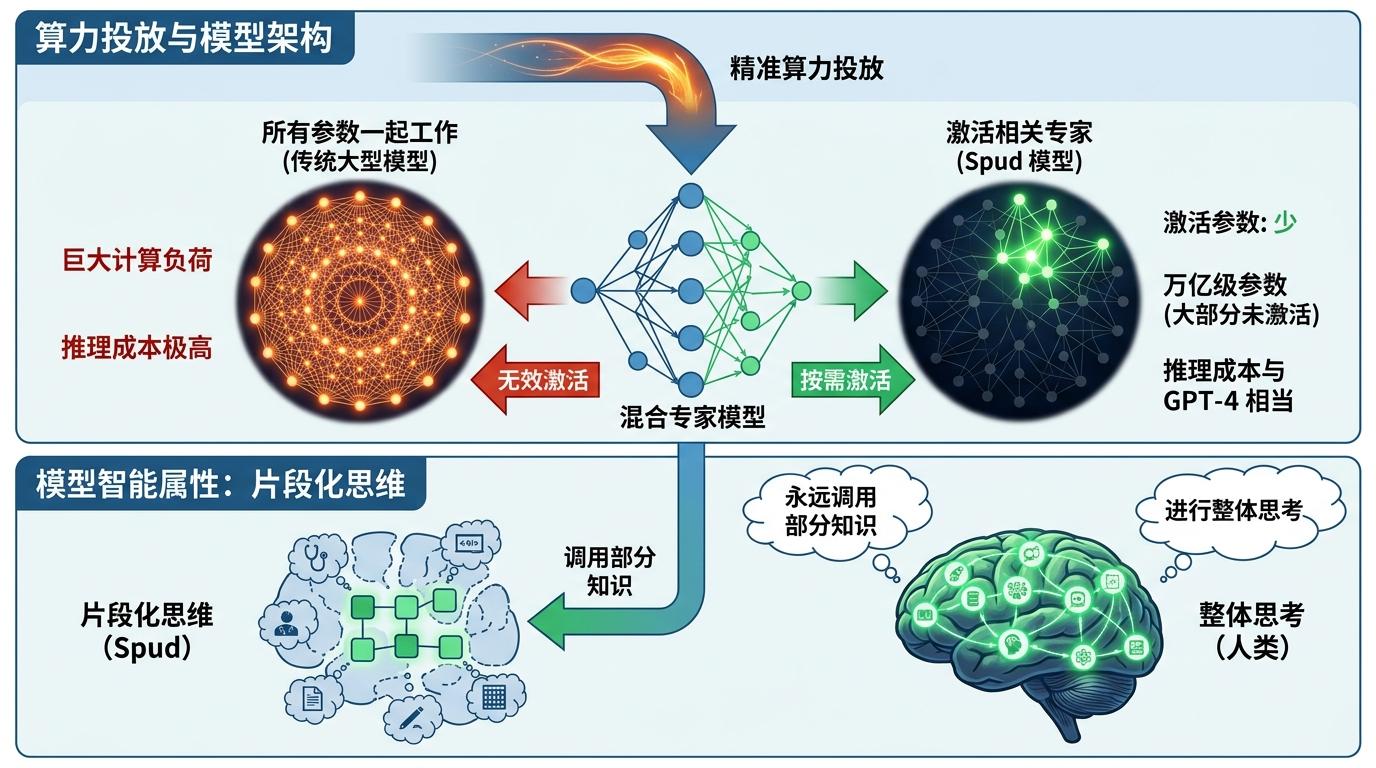
当然,这一切的前提是算力的精准投放。Spud采用了混合专家模型——就像一个专家委员会,每次只激活和任务相关的“专家”,而不是让所有参数一起工作。这样一来,它在拥有万亿级参数的同时,推理成本却和GPT-4差不多。但这也带来了新的问题:模型的智能是“片段化”的,它永远只会调用部分知识,而不是像人类一样进行整体思考。
OpenAI的算力焦虑,不是个例。2026年的AI行业,算力已经成了硬通货——全球半导体厂商把70%的产能,都转向了AI专用芯片,消费电子市场的内存价格因此暴涨了30%。谷歌、Meta这些巨头,提前两年就锁定了台积电的产能,而小型创业公司别说训练大模型,就连租GPU都要排队。

这种算力集中带来的后果很直接:行业的创新正在向头部聚集。OpenAI们可以砸千亿建数据中心,而小公司只能在细分领域找机会。更让人担忧的是,算力的短缺正在倒逼整个行业“功利化”——所有能快速变现的项目都被优先投入,而那些看起来“没用”的基础研究,正在被逐渐边缘化。
但也不是没有转机。OpenAI正在开发自动化AI研究员,让AI自己去做实验、写代码、优化模型。如果这套系统能跑通,未来的AI研发效率可能会提升10倍以上——到那时,算力的瓶颈或许就不再是问题。但没人知道,这套系统会不会反过来,把人类研究员也变成“多余的人”。
当我们谈论AI的未来时,我们总是在谈论更强大的模型、更酷炫的功能,却很少谈论算力——这个最朴素、也最关键的约束。OpenAI的选择,其实是整个AI行业的缩影:在算力的硬天花板下,我们不得不放弃“全面开花”的幻想,转而追求“精准打击”。
算力不是无限的,创新也不是。算力有限,创新才能精准落地。未来的AI,不会是无所不能的“神”,而是能把80%的工作做好的“助手”。它不会再追求“更多”“更强”,而是会变得更“实用”、更“贴心”。而这,或许才是AI真正改变世界的开始。