对抗知识焦虑,从看懂这条开始
App 下载
阿里新AI把音视频生成焊在了一起
AI视频生成|音视频同步|Transformer架构|统一序列|阿里巴巴|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI视频生成|音视频同步|Transformer架构|统一序列|阿里巴巴|多模态视觉|人工智能
雨丝顺着破庙的瓦檐滴成细线,镜头从这滴水拉远,巷口的武侠少年突然拔剑——金属交击的脆响和剑刃的寒光同步炸开,连少年下颌绷紧的弧度都和呼吸节奏严丝合缝。这不是实拍的电影片段,是一款AI生成的15秒短视频。它来自阿里巴巴的多模态模型,登顶了全球AI视频盲测榜单,把音视频同步的精度推到了新的高度。
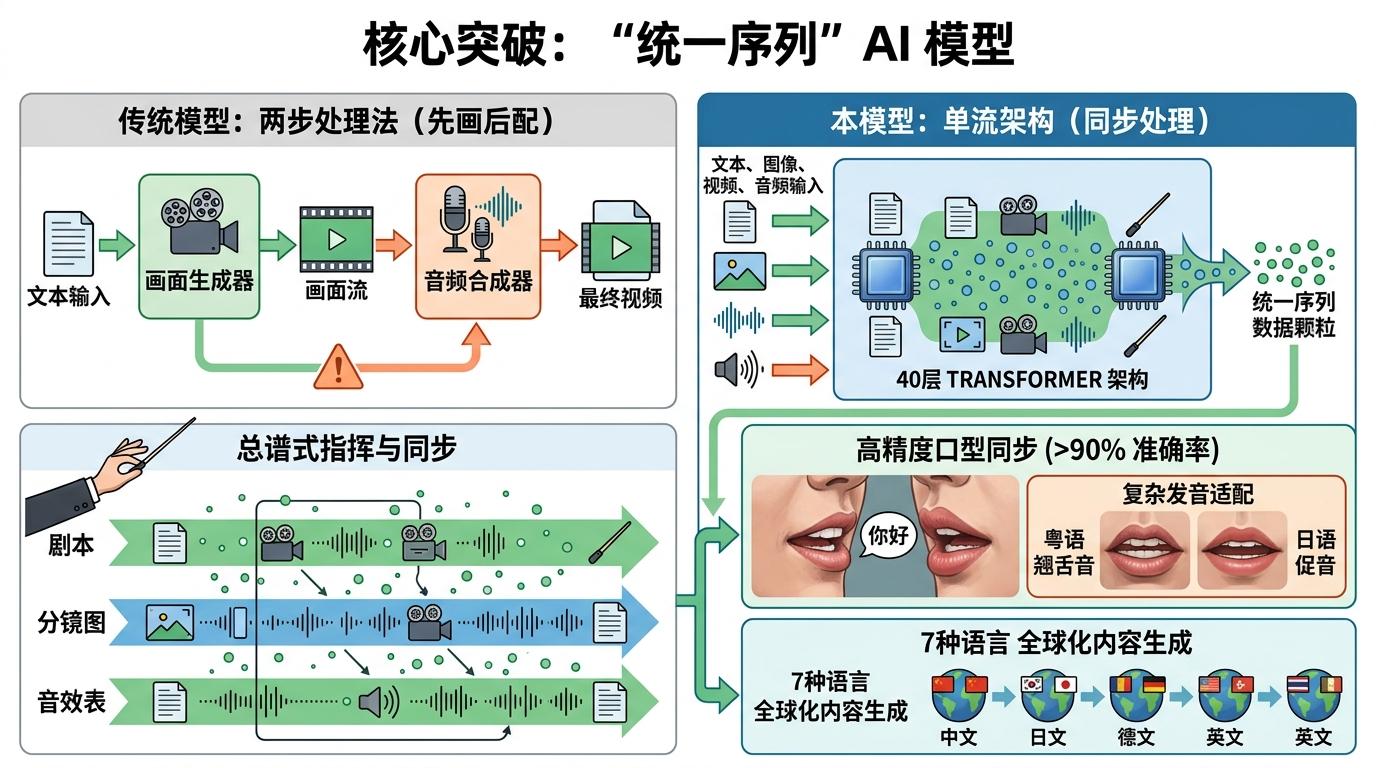
它的核心突破藏在那串看不见的「统一序列」里。和传统模型先画画面再配声音的两步走不同,它把文本、图像、视频、音频的信息都编码成同一种「数据颗粒」,塞进40层的Transformer架构里同步处理——就像把剧本、分镜、音效表揉成一份总谱,让AI同时指挥画面和声音的节奏。这种单流架构让口型同步准确率超过90%,连粤语的翘舌音、日语的促音都能精准对应唇形,7种语言的适配能力刚好踩中了全球化内容生产的痛点。
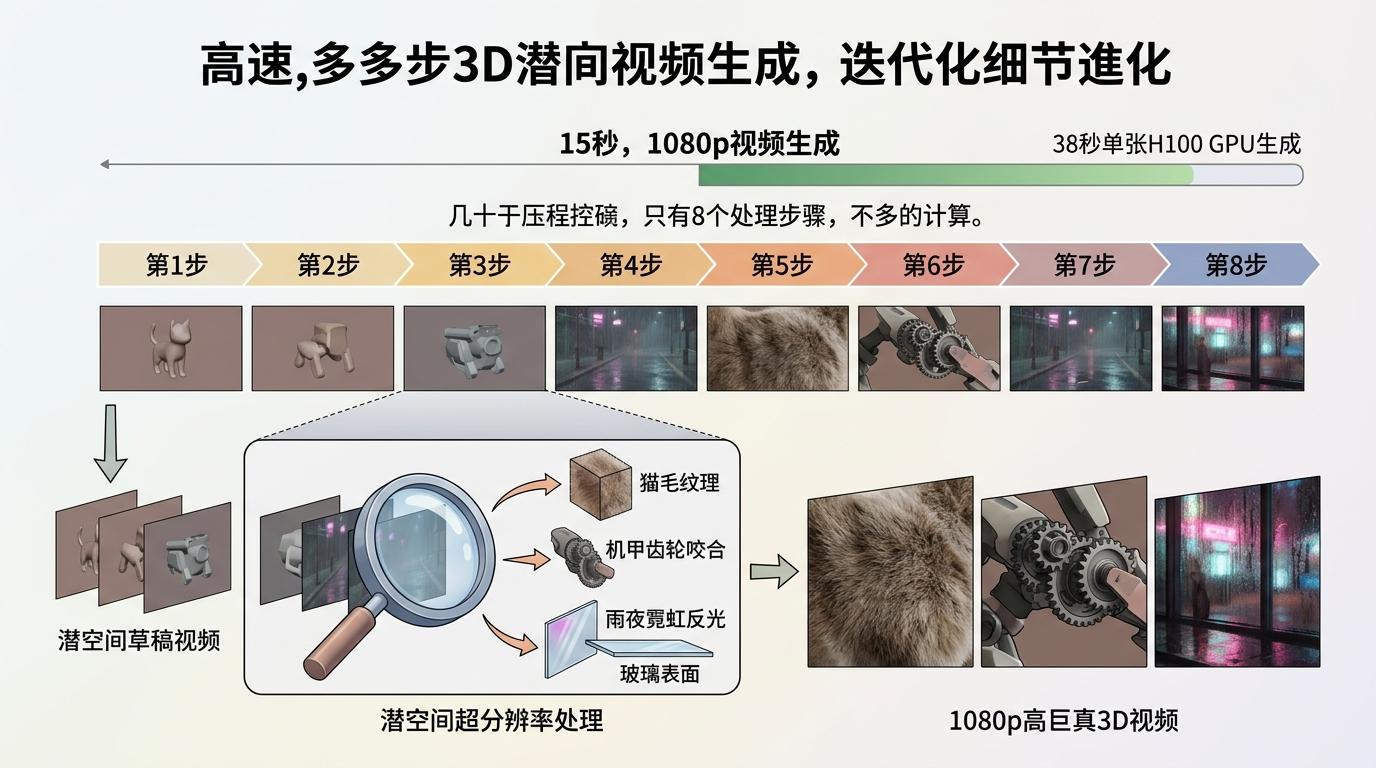
为了让这份「总谱」跑得更快,研发团队用DMD-2蒸馏技术把原本几十步的生成过程压缩到8步,砍掉了冗余的计算环节。在单张H100 GPU上,生成一段1080P的15秒视频只需要38秒,比多数竞品快了近一倍。更关键的是,它在潜空间里完成超分辨率处理,不是简单把低清画面拉伸,而是像用放大镜对着草稿一点点补细节——猫毛的纹理、机甲齿轮的咬合痕迹、雨夜霓虹在玻璃上的反光,这些容易露馅的AI破绽,都被它填得足够逼真。
但它还不是完美的「全能创作者」。目前它最长只能生成15秒的视频,复杂场景里偶尔会出现人物手指变形、物体穿模的小bug,参考图编辑的功能也还不够稳定。在真人互动的复杂场景中,为了跟上提示词的动作指令,有时会牺牲物理合理性——比如生日蛋糕的蜡烛被吹灭的瞬间,烛火的晃动轨迹可能不符合气流规律。这些瑕疵,恰恰是AI视频生成从「做对」到「做好」要跨过的门槛。
它真正的意义,或许不是生成了多少逼真的画面,而是重新定义了内容创作的成本。过去要拍一支符合海外市场的多语言广告,需要租场地、找演员、后期配音,至少要一周时间;现在只需要输入一段提示词,几小时就能拿到7种语言版本的成片,成本只有传统方式的十分之一。这种效率的跃迁,正在让内容创作从专业团队的特权,变成每个创作者都能调用的工具。
当AI能把「猫脸特写,耳朵随微风抽动」的文字,变成连瞳孔反光都清晰可见的视频,我们其实在见证一场内容生产的革命——不是取代创作者,而是把那些重复、机械的环节交给机器,让人的创意能更快落地。毕竟,好的故事永远需要人来写,但讲故事的工具,已经变得前所未有的强大。