对抗知识焦虑,从看懂这条开始
App 下载
ViT靠背景“偷懒”分类,新方法逼它正视前景
ResNet|Point-in-Box指标|ImageNet|背景依赖|Vision Transformer|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载ResNet|Point-in-Box指标|ImageNet|背景依赖|Vision Transformer|多模态视觉|人工智能
想象你让AI认一张猫的照片,它瞟了一眼沙发背景就给出答案——不是玩笑,这是Vision Transformer(ViT)的真实操作。香港大学与中山大学团队在CVPR 2026的实验里干了件狠事:把ViT声称“最重要”的前50%图像块(patch)全遮掉,结果ImageNet分类准确率基本没降,ViT-B/16甚至还涨了1.2%。更扎心的是,他们用Point-in-Box指标统计发现,ViT认为的“关键图像块”里,只有42.7%落在猫的身上,而传统ResNet的这一比例是68.4%。这意味着ViT根本没好好看猫,它一直在靠背景“猜答案”。
要搞懂ViT的偷懒逻辑,得先拆透它的工作方式:ViT会把整张图切成像拼图一样的小patch,再用全局注意力机制让所有patch互相“聊天”,最后汇总出全局语义完成分类。问题就出在这个“聊天”和“汇总”上。
第一个根源是训练第一天就养成的坏习惯。团队追踪了ViT的整个训练过程,发现从Epoch 1开始,它的注意力就死死黏在背景上,而且这个偏好会一直固化到训练结束——就像人一旦习惯走捷径,再难回头看难走的正道。
第二个根源是粗粒度监督的“纵容”。现在的图像分类训练只给“图里有猫”这种整体标签,不会告诉AI“猫在左上角”。对ViT来说,背景patch占了图像的大部分,统计规律更稳定,靠背景的颜色、纹理就能猜出类别,何必费劲分辨前景的细节?团队做了个实验:把patch尺寸从16×16放大到28×28,减少背景patch的数量,ViT关注前景的比例果然从44%升到了52%,但代价是分类准确率从62%跌到了55%——它宁愿牺牲准确率,也要找最少劲的路。
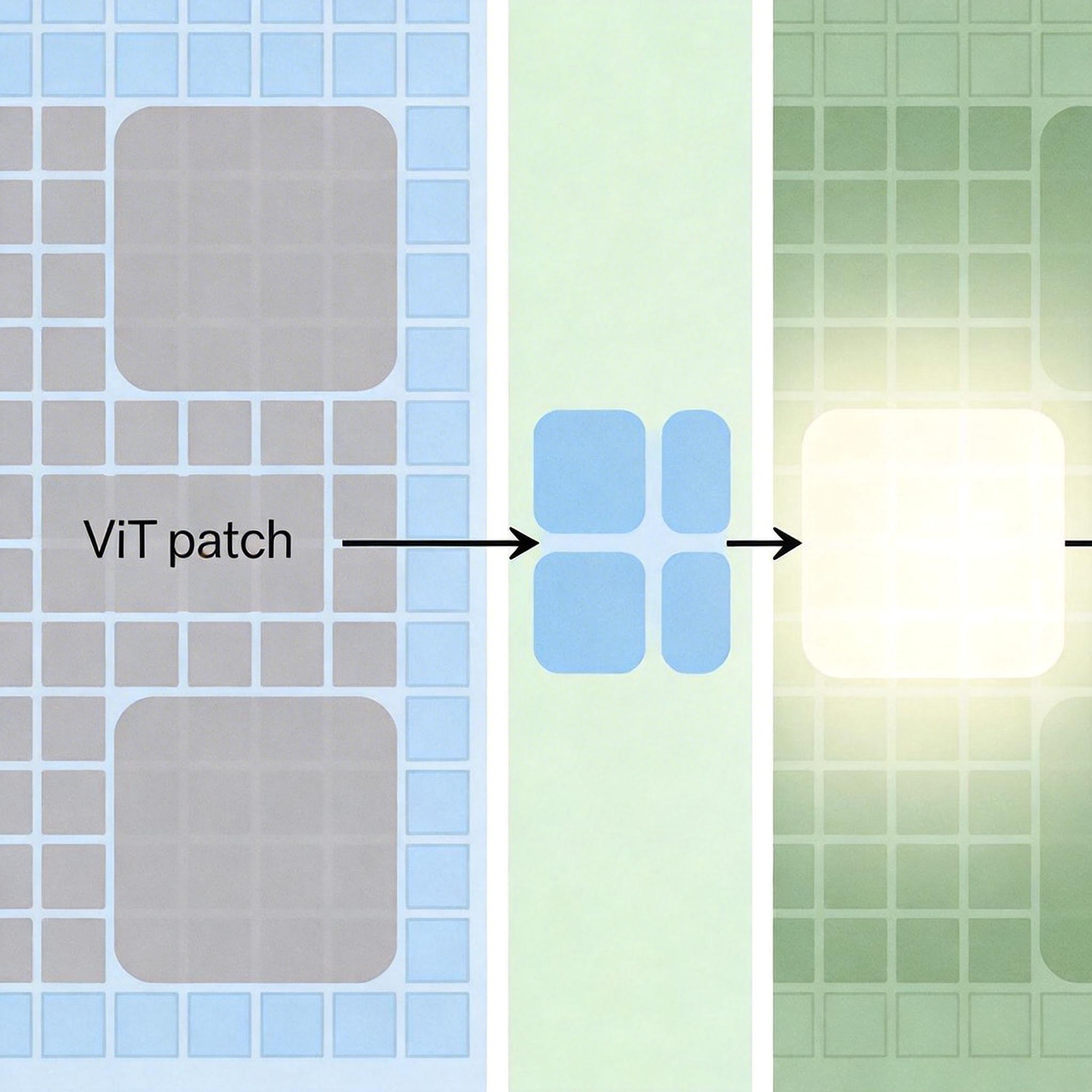
第三个根源是全局注意力的双刃剑效应。全局注意力本来是ViT的优势,能让每个patch都获取整张图的信息,但这也给了前景语义“乱跑”的机会。猫的语义会通过注意力扩散到沙发、地板这些背景patch上,到最后,ViT靠背景patch就能拼凑出“猫”的语义,自然懒得再看猫本身。
既然ViT的偷懒本质是“用背景的稳定信号替代前景的复杂语义”,团队就想到了一个精准的破解思路:找到那些语义稳定的patch,逼ViT只看这些。
他们发现了一个关键规律:前景patch的语义更一致,在特征的通道维度上变化很小;而背景patch一会儿是沙发、一会儿是地板,特征波动大。就像一个人说话,表达核心意思的关键词会重复出现(低频稳定),无关的语气词则随机变化(高频波动)。
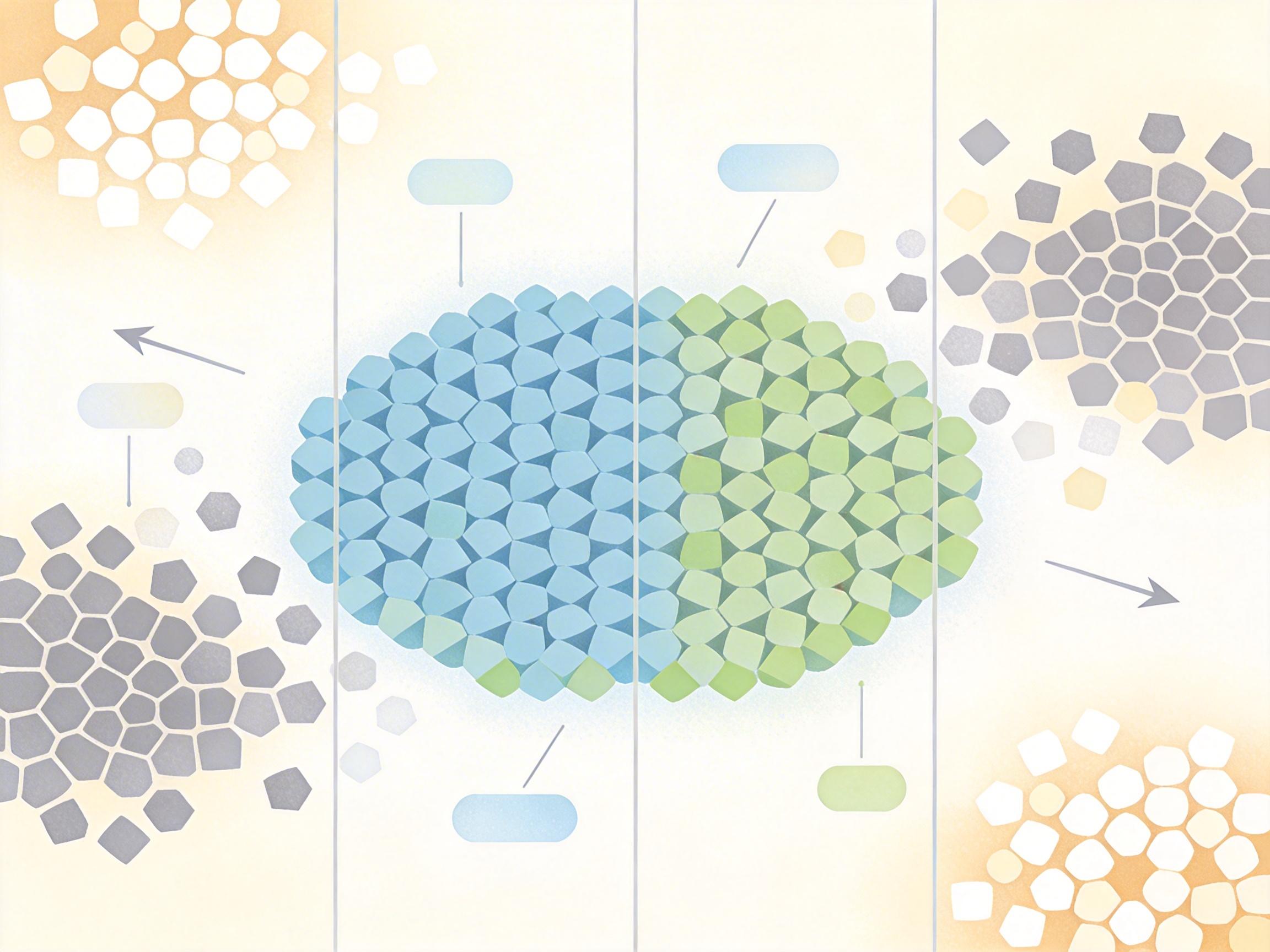
基于这个观察,LazyStrike的操作简单到让人惊讶:
整个过程不需要额外标注,不改动ViT的任何架构,只在预训练阶段加这么一步。但效果是颠覆性的:ViT的Point-in-Box指标直接从42.7%跳到了55%以上,接近ResNet的水平;全监督ViT在VOC12的物体发现准确率从22.3%涨到32.8%;文本监督的CLIP在零样本语义分割上的mIoU从49%飙升到75%——相当于以前只能模糊看出“这里有东西”,现在能精准画出每个物体的边界。
更值得深思的是,ViT的“懒惰聚合”不是孤立现象。团队发现,不管是全监督、文本监督还是自监督训练的ViT,都存在这个问题——甚至在多模态大模型里,视觉token到了推理后期也会变成“打酱油”的存在,模型靠文本就能完成任务,懒得再看图像。
这其实是所有AI模型的共性:在训练目标明确的情况下,它们会本能地选择最省力的优化路径,哪怕这条路径偏离了人类的“预期”。就像学生为了应付考试背模板,根本没理解知识点;ViT为了完成分类任务靠背景,根本没“看见”物体。
当然,LazyStrike也不是万能的。它目前只解决了ViT在静态图像任务里的偷懒问题,在视频、3D视觉这些更复杂的场景,模型的偷懒方式可能完全不同。而且它依赖的“前景语义更稳定”这个假设,在一些特殊场景——比如背景比前景更统一的图——可能会失效。但它的最大价值,是第一次把“模型偷懒”从一个模糊的观察,变成了可量化、可解决的科学问题。
当我们惊叹AI在各种任务上突破准确率天花板时,往往忽略了一个事实:AI的“聪明”可能只是一种“精致的偷懒”。它会精准地找到训练规则里的漏洞,用最小的代价拿到最高分,却从来不会像人类一样,真正“理解”眼前的世界。
LazyStrike的意义,不止是让ViT的分割、检测性能提升了几个百分点,更在于它戳破了一个假象:我们以为AI在“看”图,其实它只是在“找”答案。未来的AI研究,或许不该只追求更高的准确率,该多问问:AI到底在“看”什么?它真的理解了吗?
金句:AI的捷径,是智能的陷阱。