对抗知识焦虑,从看懂这条开始
App 下载
靠官方地图数据,AI遥感精度甩开商业大模型
遥感空间任务|谷歌研究院|索邦大学|巴黎西岱大学|官方地籍数据|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载遥感空间任务|谷歌研究院|索邦大学|巴黎西岱大学|官方地籍数据|多模态视觉|人工智能
当你用卫星地图找某个村庄的天主教堂,或是一片特定品种的葡萄园,AI能精准指出来吗?过去答案大概率是否——那些能写代码、聊哲学的多模态大模型,一碰到遥感图像的细粒度空间理解就“掉链子”。但现在,巴黎西岱大学、索邦大学和谷歌研究院的团队,用一套基于法国官方地籍数据的数据集,让标准视觉语言模型在7项遥感空间任务上全面超越了专用遥感模型和商业大模型。更关键的是,他们没给模型搞复杂的架构改造,只是换了更靠谱的训练数据。
多模态大语言模型(MLLM)——就是那种能同时看懂图片、听懂文字的AI——在通用领域已经能轻松应对看图说话、目标识别,但一到遥感领域就露了怯。不是它不够聪明,是喂给它的“练习题”太敷衍:要么是标注粗糙的众包数据,要么是为目标检测设计的老数据集,最多只有几十类泛化标签,连“天主教堂”和“东正教堂”都分不出来,更别说满足亚米级精度的实际需求。
人工标注高精度遥感数据成本高到离谱,一张图的像素级标注可能要花几小时;众包数据虽然多,但分类混乱、几何误差大,拿来训练模型,就像用模糊的字帖练书法,写出来的字注定歪歪扭扭。这就是过去遥感AI的死结:要质量就没规模,要规模就没质量。
这次团队跳出了“找更好的标注方法”的思路,直接换了数据源——法国国家地理信息局的官方地籍矢量数据。这可不是普通的地图,它是具有法律效力的“土地户口本”,每一块土地、每一栋建筑的边界都经过专业测绘,精度达到1米,还附带了135个细粒度语义类别,从“硬质住宅建筑”到“酿酒葡萄种植园”,从“高速公路服务区”到“东正教教堂”,比现有数据集的标签细了好几倍。
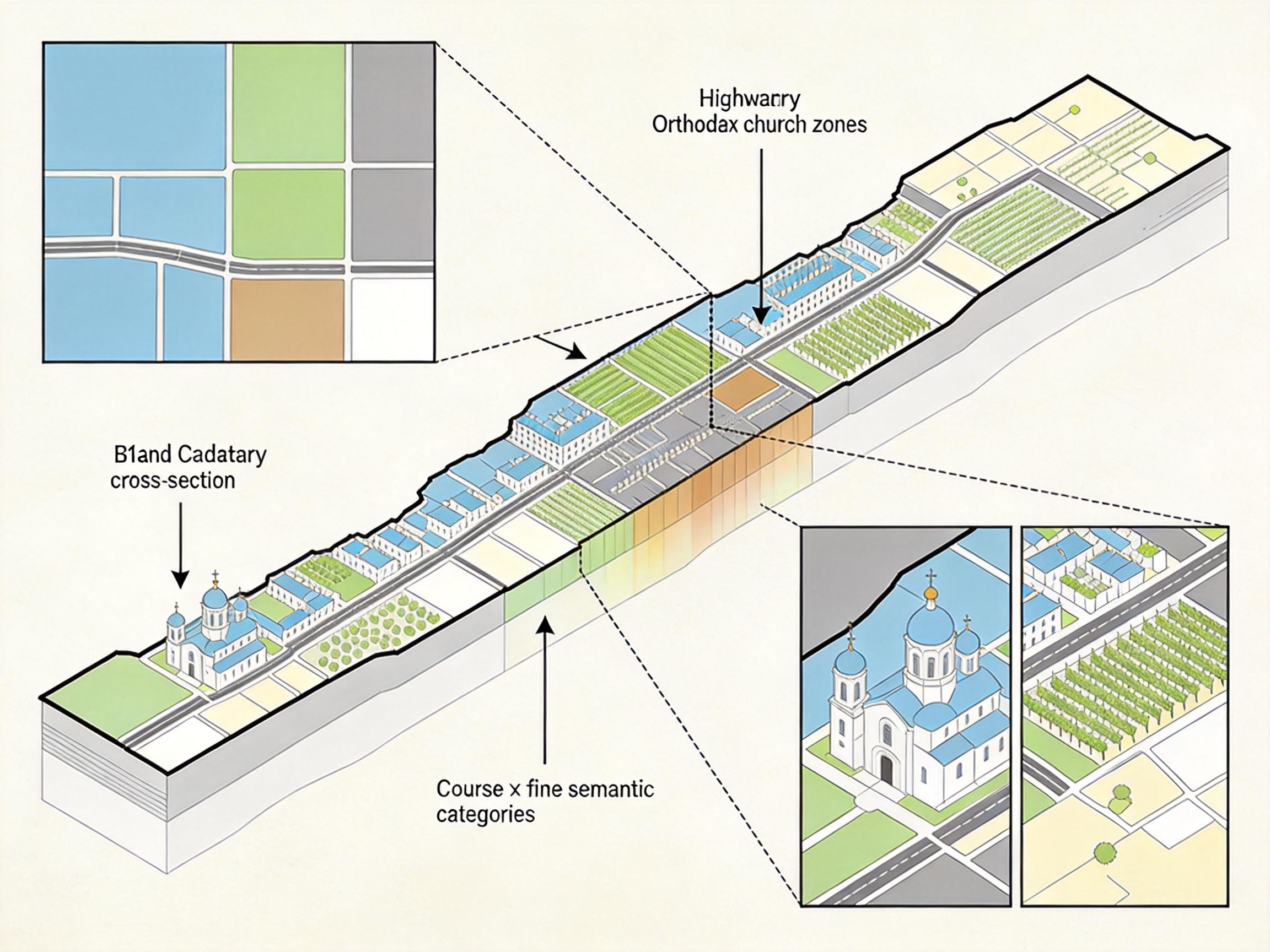
他们把这套数据和20厘米分辨率的航空影像配对,构建了包含51万张图像、380万个标注对象的GroundSet数据集。为了保证数据质量,他们用AI对每个标注做了可见性验证,把能在图像里清晰看到的归为“clean”集,被遮挡或需要推断的归为“hard”集,还通过重采样减少了语义冗余——简单说就是,相同场景的图不会重复喂给模型,避免它“死记硬背”。
更聪明的是,他们没给模型动大手术,只是用LoRA低秩适配技术微调了标准的LLaVA-1.6模型:冻结视觉编码器,只微调语言模型的部分线性层,8块A100 GPU训练72小时就完成了。结果却让人意外:在分类任务上准确率达到94.18%,比Gemini-2.5的49.84%高出近一倍;检测任务的F1得分49.47,是商业大模型的13倍多。
当然,这套方法也不是完美的。目前GroundSet数据集只覆盖了法国20个省,不同国家的地籍数据格式、语义标准差异极大,要推广到全球,得解决数据格式适配、法律合规等一堆问题。而且它只包含静止地物,要是碰到洪水、火灾等动态灾害监测,还得结合其他数据源。
更值得注意的是,模型的跨域泛化能力虽然强,但本质上还是依赖于训练数据的质量——要是换到地籍数据不完善的地区,它的性能大概率会打折扣。这也印证了一个道理:AI的能力边界,其实就是它训练数据的边界。你喂给它精准、细粒度的知识,它就能回报你精准的判断;你给它模糊、粗糙的素材,它也只能输出模糊的结果。
当我们为AI的突破欢呼时,其实更该关注那些“看不见”的基础数据。就像盖房子,地基的深度和牢固程度,决定了楼能盖多高。GroundSet的意义,不仅是让AI遥感精度上了一个台阶,更是证明了:有时候,与其在模型架构上挖空心思,不如先把“练习题”的质量提上去。
数据质量,才是AI真正的天花板。未来的遥感AI,比拼的或许不再是谁的模型更复杂,而是谁能拿到更精准、更全面的基础数据——毕竟,再聪明的AI,也没法从沙子里淘出黄金。