对抗知识焦虑,从看懂这条开始
App 下载
AI把思考藏进暗箱,反而更快更准了
抽象符号|推理压缩|链式思考|浙江大学|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载抽象符号|推理压缩|链式思考|浙江大学|大语言模型|人工智能
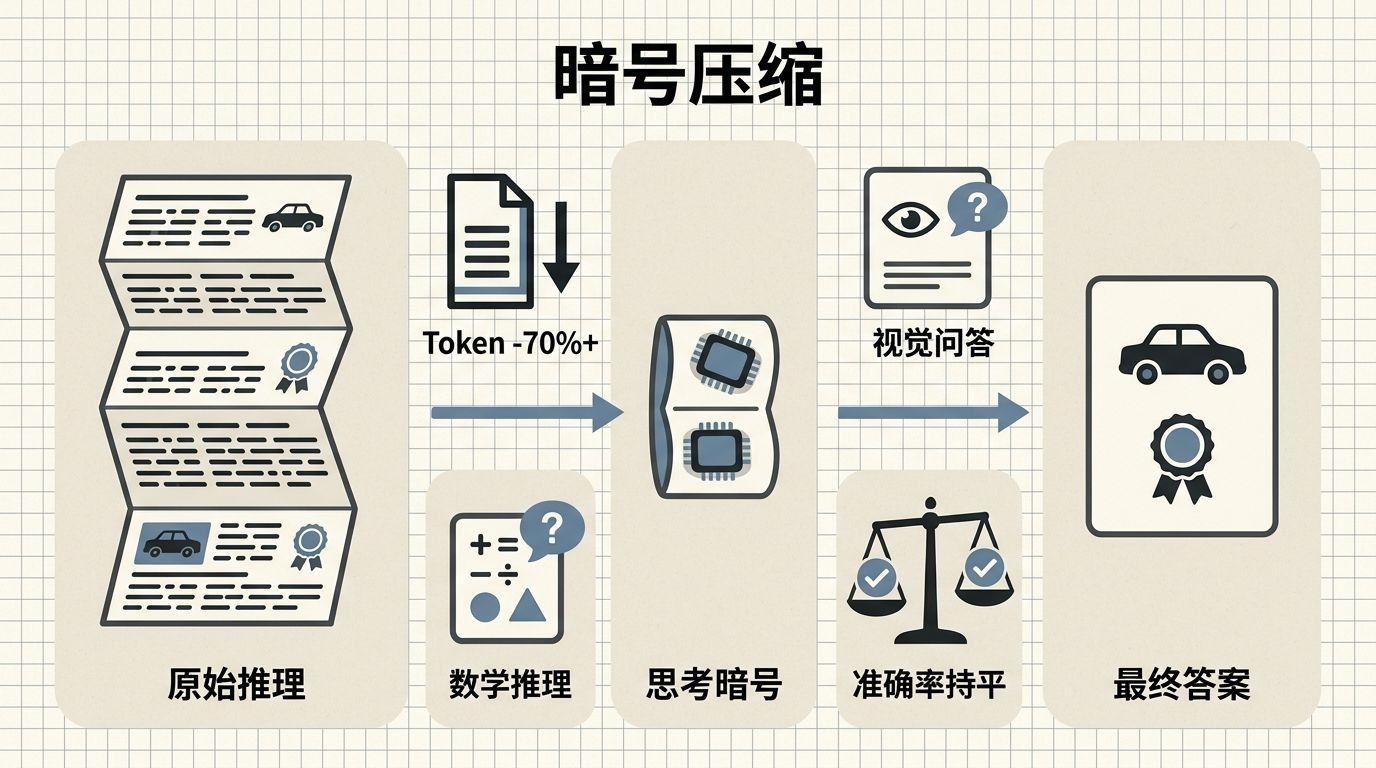
当你问AI“这张图里的车是什么品牌”,它会先啰嗦一大段:“这是一辆黑色汽车,车头有圆形蓝白标志,对应宝马品牌……”——就像把草稿纸全摊给你看。每多写一个字,背后的服务器就要多跑一轮计算,延迟、成本、能耗跟着往上跳。2026年,浙江大学联合团队把这些“草稿纸”压缩成了几个没人能看懂的抽象符号,AI在暗箱里完成推理,速度快了数倍,答案准确率还没降。这背后藏着一个反常识的问题:AI的思考,真的需要让人类看见吗?
你可以把大模型的链式思考(Chain-of-Thought,CoT)想象成学生做数学题——要把“先算乘除后算加减”“这里要通分”全写在卷子上,老师才给分。但对AI来说,每写一个字都是一次自回归解码,相当于每一步都要把前面所有内容再算一遍,1000个思考token的计算量,是直接输出答案的1000倍。
Heima框架做的,就是把这张写满草稿的纸,压缩成几个只有AI能懂的“思考暗号”(thinking tokens)。比如面对汽车品牌识别问题,它不再生成整段推理文本,而是输出<Thinking_of_Caption> <Thinking_of_Reasoning>这两个短token。这些token本身没有意义,但它们的隐空间编码里,藏着“黑色汽车”“蓝白圆形车标”“对应宝马”所有关键信息。
这不是简单偷懒。研究团队用了渐进式蒸馏的方法:先让AI完整写10次推理草稿,再慢慢把其中一段换成暗号,等AI适应了,再换一段,直到所有草稿都变成暗号。这个过程就像让学生从写全步骤,过渡到只写关键公式,最后只在草稿纸上画几个只有自己懂的标记,却能算出同样的结果。
把思考藏进暗箱,最大的质疑是:你怎么知道AI真的在思考,不是随便蒙了个答案?团队为此设计了一个“翻译器”——用纯文本大模型把这些抽象的思考暗号,重新解码成人类能看懂的推理文本。
实验结果有点出乎意料:这个翻译器不需要看原图,只凭问题和思考暗号,就能还原出和原始推理几乎一致的文本。比如看到<Thinking_of_Caption>,它能输出“这是一辆黑色汽车,车头有蓝白圆形标志”;看到<Thinking_of_Reasoning>,能输出“这个标志是宝马的品牌标识,所以答案是宝马”。这说明思考暗号里确实藏着完整的推理逻辑,不是空壳。
从信息论的角度看,思考暗号是原始推理文本的“压缩包”——虽然体积小了,但保留了和最终答案相关的所有关键信息。就像你把一部电影压缩成蓝光文件,虽然少了一些花絮,但核心剧情一点没丢。测试数据显示,Heima能把推理token数减少70%以上,在视觉问答、多模态数学推理等任务上,准确率和原始链式思考几乎持平,部分数据集甚至略有提升。
当然,它也不是万能的。在需要多路径探索的复杂推理任务中,单一的思考暗号不如完整文本灵活;而且翻译器的鲁棒性还不够,遇到极端压缩的暗号,偶尔会还原出逻辑不通的内容。
Heima的意义,不止是让AI少写几个字。它指向了大模型推理的一个核心矛盾:人类需要“看得见的思考”来信任AI,但AI本身的推理,根本不需要人类语言作为中间媒介。
过去几年,大模型的推理效率一直是落地的瓶颈。比如OpenAI的o1模型,为了提升复杂推理能力,生成的token数是普通模型的几十倍,测试一次的成本就要几千美元。而Heima这种隐式推理思路,相当于给AI开了个“内部思考通道”——不用再把思考翻译成人类语言,直接在模型的隐空间里完成推理,跳过了最耗时的自回归解码步骤。
这和硬件端的优化形成了互补。比如现在流行的推测解码,是用小模型先快速生成草稿,再让大模型验证;而Heima是从源头上减少了需要生成的内容。两者结合,能把大模型的推理效率提升一个数量级。对普通用户来说,这意味着AI的响应速度更快,成本更低;对企业来说,能让大模型在手机、边缘设备等低算力平台上也能流畅运行。
当我们要求AI用人类语言思考时,其实是把人类的认知习惯强加给了机器。就像让一个天生会用二进制计算的机器人,必须先把数字转换成汉字再计算,既低效又没必要。
Heima的尝试,本质上是让AI回归它本来的思考方式——用向量、隐空间和抽象编码,而不是人类的句子。未来的AI推理,可能会形成一种新的平衡:在需要信任和解释的场景,输出人类能懂的推理步骤;在追求效率的场景,就用暗箱里的思考暗号快速计算。
最好的思考,从来都不是写给别人看的。 对AI如此,对人类也是一样。