对抗知识焦虑,从看懂这条开始
App 下载
大英百科诉OpenAI,拆解「模型权重」与「RAG」版权暗线
AI版权诉讼|RAG实时检索|模型权重|OpenAI|大英百科|公共政策|AI安全治理|社会人文|人工智能
当GPT-4能逐字默写出大英百科的条目时,一场针对AI全链路版权的围剿开始了。2026年3月,拥有258年历史的大英百科联合韦氏词典,把OpenAI告上了纽约联邦法院——这是AI版权诉讼史上第一次有人试图把训练数据抓取、模型记忆输出、实时检索整条生成链路“一锅端”。更关键的是,它把此前无人触及的「RAG实时检索」也拉进了战场。为什么这家老牌百科要孤注一掷?这背后藏着AI版权边界最核心的技术暗线。
模型权重:AI的“隐形记忆库”争议
你可以把大模型的训练过程想象成一个人读遍十万本书,然后把所有内容压缩成一本加密笔记——这本笔记就是「模型权重」,一堆记录着知识规律的数值参数。过去人们以为,这些参数只存储了“猫有四条腿”“巴黎是法国首都”这类抽象规律,直到斯坦福和耶鲁的研究团队做了个实验:他们用特定提示词,从主流大模型里提取出了《哈利·波特》原文,最高提取率达到96%。

这意味着,训练数据里的内容并没有完全被“消化”,有相当一部分被原封不动地“记”在了权重里。大英百科抓住了这一点:它旗下近10万篇由专业团队耗时数十年打磨的条目,被GPT-4完整“记住”,在特定提示下能逐字输出复制品。
不同国家的法院给出了完全相反的答案:德国慕尼黑法院在2025年的GEMA诉OpenAI案中认定,模型权重里的“记忆”就是版权法定义的“复制”;而英国高等法院在Getty Images诉Stability AI案中则认为,权重只是统计模式,不构成侵权复制品。这种分歧的本质,是传统版权法在面对AI“隐形记忆”时的规则空白。
RAG实时检索:AI的“开卷考试”闯了祸
如果说模型权重是AI的“闭卷记忆”,那「RAG实时检索」就是它的“开卷考试”——当用户提问时,AI会先实时搜索外部数据库的内容,再基于这些信息生成回答。这项技术原本是为了解决大模型“知识过时”“容易幻觉”的问题,却成了本次诉讼中最具突破性的指控点。
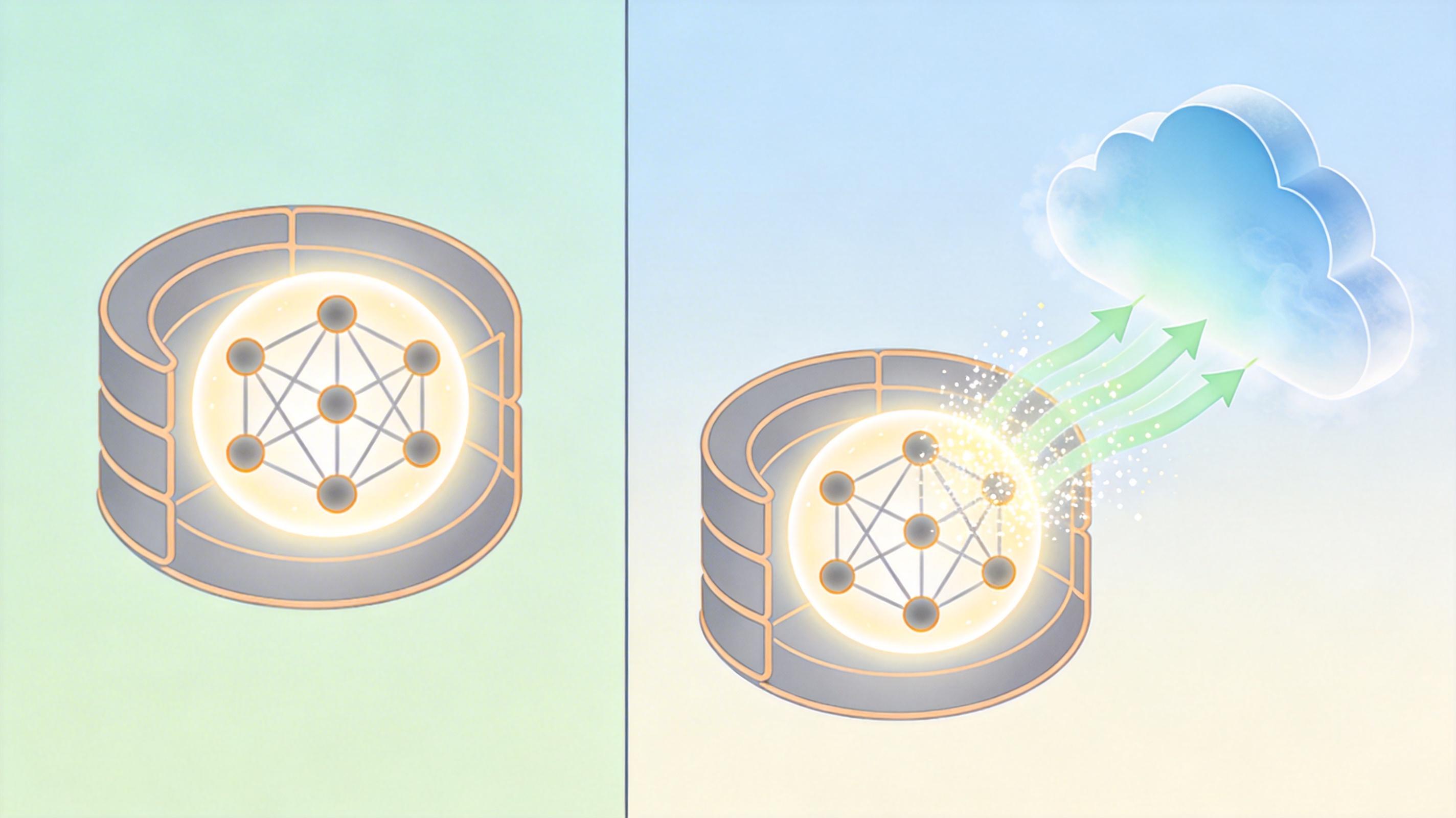
大英百科认为,哪怕它的内容没进入训练集,只要被ChatGPT的RAG系统实时调用,就算侵权。这是前所未有的逻辑:过去的版权争议只盯着“静态训练数据”,现在连AI“动态临时借读”的内容也要追责。
这背后的商业逻辑更直接:RAG生成的回答会直接替代用户访问大英百科官网的需求。根据统计,部分传统知识内容提供商的订阅用户因AI服务减少了5%-15%,流量和广告收入被直接分流。而AI公司则辩称,RAG只是引用信息,如同搜索引擎的摘要,属于合理使用。但目前没有任何国家的版权法明确界定,AI的“实时检索-生成”到底算不算侵权。
法律与技术的拉锯:谁来定义新规则
这场诉讼的核心,其实是知识产业的权力重构——拥有258年历史的大英百科,曾在纸质时代是人类知识的标准索引,却被维基百科冲击;好不容易转型数字订阅站稳脚跟,又遭遇AI的替代威胁。它的诉状更像是一种姿态:试图通过法律手段,重新划定知识权威在AI生态里的边界。
从技术角度看,AI公司并非没有应对方案:比如通过数据去重、正则化减少模型对版权内容的“记忆”,给RAG系统加上版权过滤机制,只调用获得授权的内容。但这些措施都会增加研发成本,甚至影响模型的回答质量。
美国版权局2025年的报告给出了一个折中方向:AI训练的“合理使用”要看是否具有“变革性”——如果AI只是原样输出内容,就不算变革性;但如果是用知识生成新的内容,就可能被认可。不过报告也强调,非法获取的训练数据,哪怕用于“变革性”训练,也不能适用合理使用。
当AI能逐字默写出人类积累了百年的知识,当它能实时调用任何公开内容生成回答,我们突然发现,传统版权法的“复制”“合理使用”这些概念,在AI面前变得模糊不清。这场诉讼的结果,不仅会决定OpenAI要赔多少钱,更会定义未来知识产业的游戏规则:是AI免费使用人类的知识成果,还是必须建立一套新的授权与分润体系?
知识的价值,从来不是存储,而是流转与创造。 或许最终的答案,不是让AI停止学习,而是找到一种方式,让AI的每一次“调用”,都能反哺知识的生产者——毕竟,没有了优质的知识源头,再聪明的AI也只是无源之水。