
11 天前
11 天前
当你看着身边有人打一针司美格鲁肽就瘦了二十斤,自己却连体重秤的数字都纹丝不动时,别只怪自己管不住嘴——现在有了更硬核的解释:你的基因可能在拖后腿。UCLA的研究团队分析了近9.4万名洛杉矶居民的基因与健康数据,首次找到能预测GLP-1类减肥药疗效的遗传标记,甚至发现不同族裔对药物的反应差异,居然和2型糖尿病的遗传风险直接挂钩。这可不是实验室里的纸上谈兵,而是从真实世界的多元人群里挖出来的、能直接落地的精准医疗线索。为什么偏偏是洛杉矶?这个拥有36个细分族裔的城市,到底藏着什么秘密?
你可以把传统的基因研究想象成只在小麦田里找作物规律——过去90%的遗传数据都来自欧洲裔人群,得出的结论套在水稻、玉米田里自然不准。而洛杉矶,就是一块种满了全球作物的试验田:这里的居民来自五大洲36个细分族裔,从亚美尼亚裔到菲律宾裔,从德系犹太人到墨西哥裔,每一个群体都带着独特的遗传印记。

UCLA的ATLAS样本库就把这些印记和他们的电子健康记录绑在了一起——从确诊疾病的时间到每一次用药的反应,从血糖波动到体重变化,所有数据都来自同一个医疗系统,避免了不同医院诊疗标准不一带来的干扰。研究人员就像拿着放大镜在这块拼图上找规律,不仅重复验证了之前发现的多个基因与疾病的关联,更挖出了之前被欧洲样本掩盖的新线索:比如非洲裔人群里ANKZF1基因和外周血管疾病的关联,德系犹太人中EPG5基因和血脂的关系。
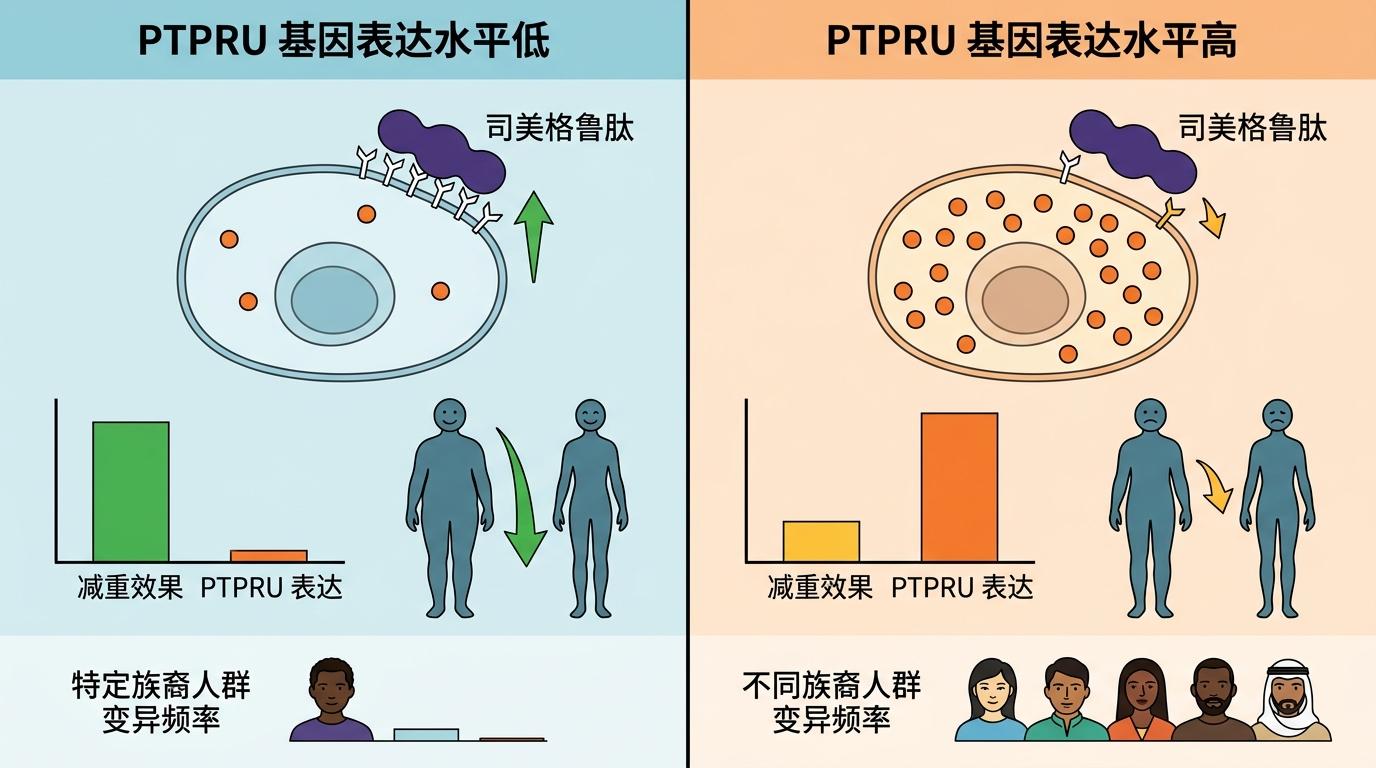
最关键的突破来自减肥药。他们发现,司美格鲁肽的疗效和一个叫PTPRU的基因直接相关——这个基因的表达水平越高,减重效果就越差。更有意思的是,这个基因的变异频率在不同族裔里不一样,这也解释了为什么有些群体用这款药见效慢。
多基因风险评分(PRS)是这次研究里的另一个主角——简单说,它就是把你全基因组里和某种疾病相关的变异都算一遍,得出一个你患这种病的风险值。就像给你的健康做了个遗传层面的信用评分。在ATLAS样本库的验证里,这个评分对1型糖尿病的预测准确率很高,意味着未来医生可以提前揪出那些高风险人群,早做干预。
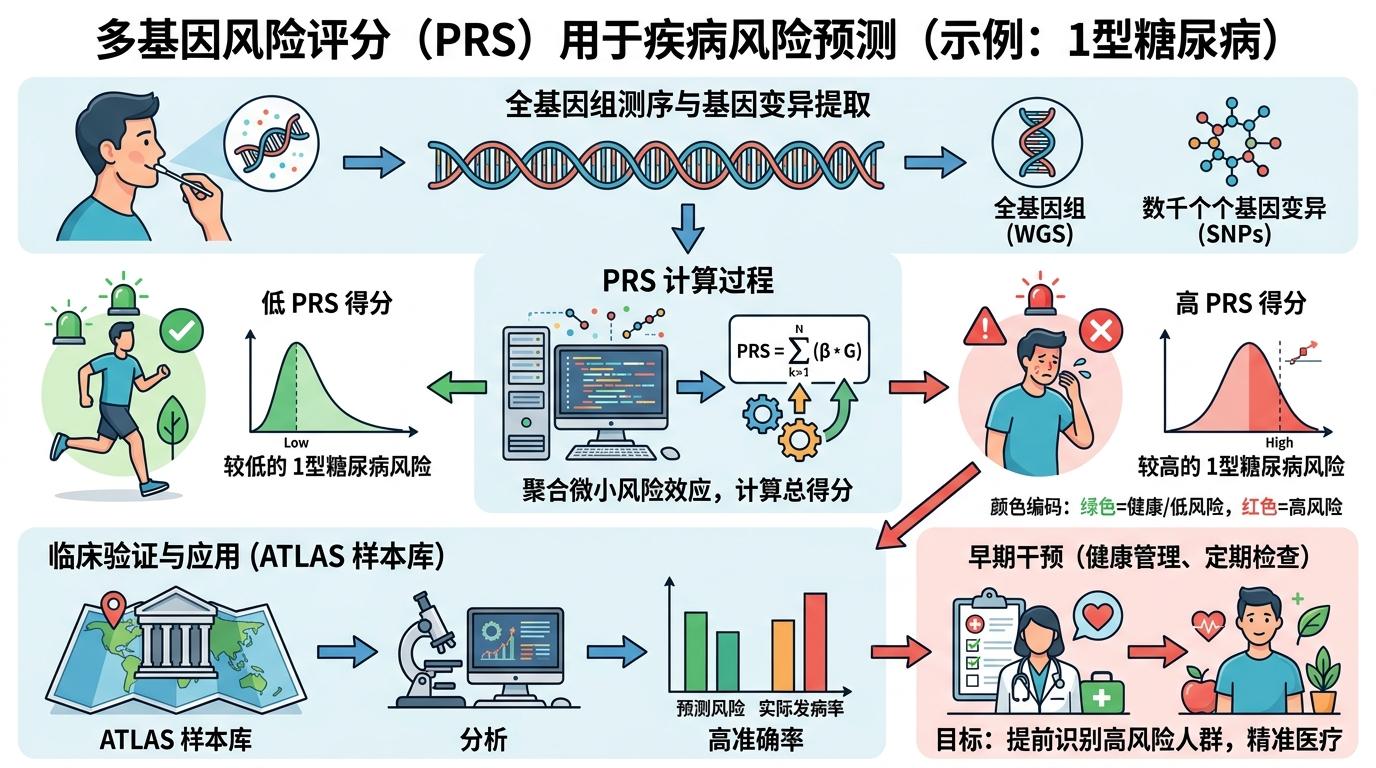
但这里藏着一个容易被忽略的问题:目前的多基因风险评分,在非欧洲裔人群里的准确率还是打了折扣。就像用校准过的尺子去量不同尺寸的东西,难免有误差。要解决这个问题,唯一的办法就是把更多非欧洲裔的基因数据放进“训练集”里,让评分模型学会识别不同人群的遗传特征。
更现实的挑战在诊室里。就算医生拿到了患者的基因报告,知道他对某款减肥药反应不好,又能怎么办?现在的药物研发还是以“通用型”为主,针对特定基因变异的定制药少之又少。而且基因检测的成本、医生对遗传信息的解读能力、患者的接受度,都是横在实验室和诊室之间的坎。毕竟,不是每个患者都能理解“你的PTPRU基因表达高,所以司美格鲁肽对你效果差”这种话。
当我们在说精准医疗的“公平性”时,不能只停留在技术层面,更要算伦理账。过去的基因研究里,少数族裔常常是被“采集”的对象,却很少能从研究成果里受益——比如某些药物的副作用在非欧洲裔人群里更高,但因为研究数据不足,说明书里根本没写。
ATLAS样本库的特别之处,在于它把患者从“实验对象”变成了“研究合作者”。研究团队会和社区沟通,解释研究的目的,甚至让社区代表参与到研究设计里。比如在招募拉丁裔参与者时,他们会用西班牙语做科普,在社区医院设招募点,而不是只在大学实验室里等患者上门。
但这还不够。未来的精准医疗,得让患者真正拥有自己的基因数据控制权——比如用区块链技术让患者决定谁能看自己的基因信息,比如让参与研究的群体能分享研究成果带来的商业利益。毕竟,这些基因数据不是实验室的“原材料”,而是每个参与者的“生命密码”,他们有权知道这些密码被用来做了什么,也有权从中受益。
当我们谈论精准医疗的未来时,想到的往往是科幻电影里的定制药、基因编辑手术,但UCLA的研究告诉我们,真正的未来,藏在那些被忽略的人群里。洛杉矶的36个族裔,就像36面镜子,照出了过去基因研究的盲区,也照出了精准医疗该走的路——不是为少数人定制高端医疗,而是让每个群体都能从研究里受益。
基因无国界,医疗该有温度。 未来十年,精准医疗的核心不是技术有多先进,而是我们能不能打破样本的偏见,把每个群体的遗传密码都放进拼图里。毕竟,健康的公平,才是精准医疗最该实现的目标。
点击充电,成为大圆镜下一个视频选题!