对抗知识焦虑,从看懂这条开始
App 下载
AI生图不再只给成品,直接给你RAW级素材
图像细节调整|AI摄影后期|RAW级线性图像|Adobe团队|南洋理工大学|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像细节调整|AI摄影后期|RAW级线性图像|Adobe团队|南洋理工大学|AIGC|人工智能
你有没有过这种遗憾?对着AI生成的夕阳海景,想把暗部的礁石拉亮,结果高光的天空直接糊成一片惨白;或是想把过曝的云层压暗,阴影里的沙滩却瞬间死黑。过去你只能怪AI“不懂摄影”——它输出的永远是像JPG一样被“焊死”的成品,没有给你留任何后期精修的余地。但2026年4月,南洋理工大学和Adobe的团队,把这种遗憾彻底变成了过去式:他们让AI第一次学会了直接生成和相机RAW原片同级的线性图像,你可以像专业摄影师那样,随便拉曝光、调白平衡,高光阴影的细节全在。这背后的突破,居然是偷师了摄影师用了几十年的老技巧。
要理解这个突破,得先搞懂两个核心概念:线性图像和sRGB图像。你平时在屏幕上看到的所有AI生图,都是sRGB图像——它就像餐厅里端上来的成品菜,已经经过调色、调味,看起来好看,但食材本身的原味和营养已经被加工过了。而线性图像,就是从相机传感器直接得到的“生食材”:每个像素的数值都和真实场景的光线强度成正比,没有经过任何压缩或调色,保留了从最暗阴影到最亮高光的所有细节。
但AI以前为什么不直接生成线性图像?核心卡在了VAE瓶颈——现在主流AI生图模型(比如Stable Diffusion、Flux)都靠VAE(变分自编码器)把图像压缩成小尺寸的“潜变量”来处理,就像用一个小杯子装水。线性图像的动态范围是sRGB的几十倍,相当于把一整缸水倒进小杯子,必然会溢出,导致高光和阴影的细节全丢。你可以试试用普通AI模型生成一张逆光照片,再把阴影拉亮,就能看到这种“糊掉”的效果——这不是AI画得不好,是VAE的小杯子根本装不下这么多光线信息。
南洋理工和Adobe的团队没有硬着头皮去做大VAE的“杯子”,而是偷师了摄影师的经典技巧——曝光包围。
你拍逆光风景时,会连续拍三张照片:一张欠曝(保留天空细节)、一张正常、一张过曝(保留地面阴影),然后合成一张HDR照片。这个团队让AI也这么干:不是直接生成一张线性图像,而是生成一组不同曝光的“包围图”——比如EV-4(极暗)、EV-2(较暗)、EV0(正常)、EV+2(极亮)。每张包围图的动态范围都和sRGB一样,刚好能装进VAE的“小杯子”里,不会溢出。
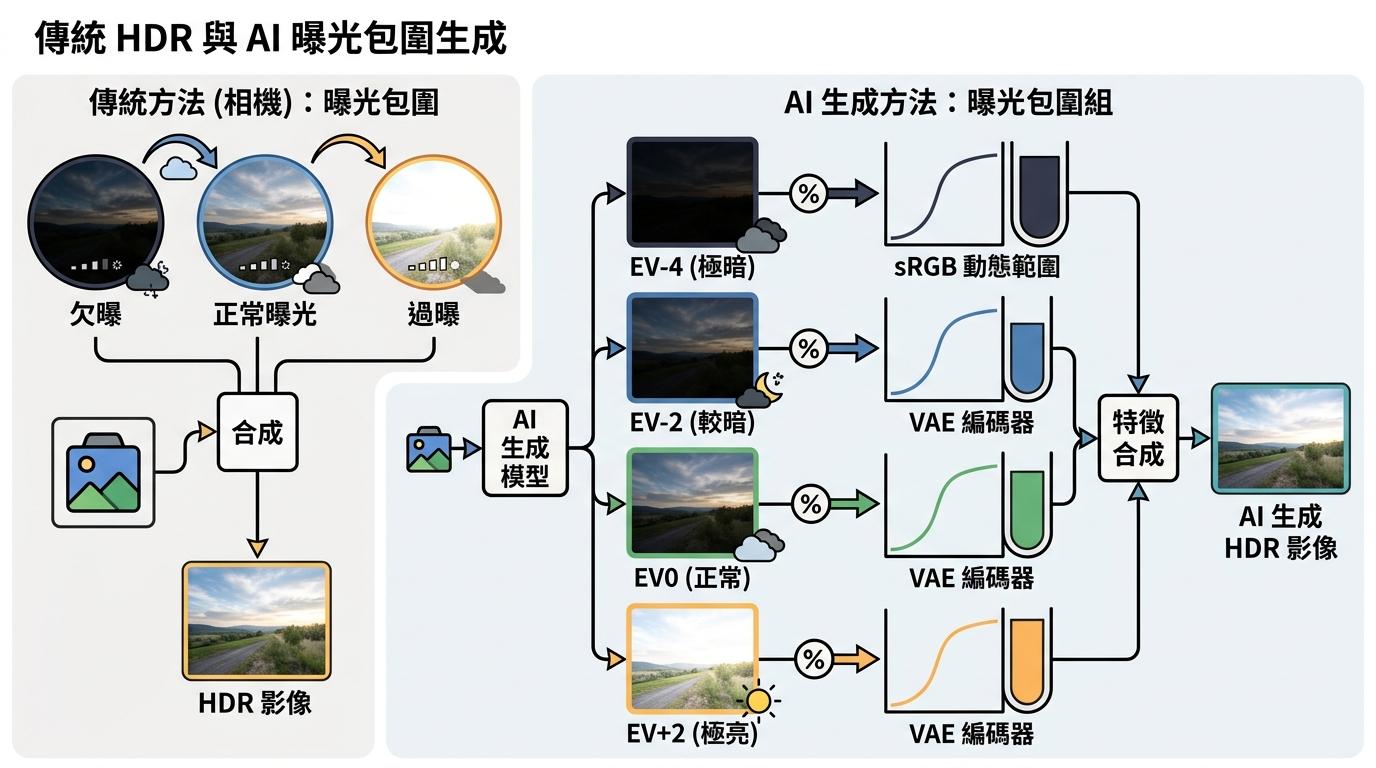
为了让这四张图的内容完全对齐,他们给模型加了两个关键机制:一是**曝光调制自注意力,让模型在生成每张图时都能“看到”其他三张图的内容,保证同一个物体在四张图里的位置、形状完全一致;二是3D旋转位置编码,给每个像素同时标记“在图像里的位置”和“属于哪张曝光图”,让模型不会把不同曝光的内容搞混。最后,他们还让模型同步预测一个辐亮度尺度**,相当于给这组包围图定一个“亮度基准”,确保合成后的线性图像符合真实场景的光线逻辑。
合成线性图像的过程更简单:从最亮的包围图开始,依次把暗包围图里未过曝的细节“贴”进去,用软掩码判断哪些区域有可用信息,最后拼成一张从最暗到最亮都有细节的完整线性图像——这个过程完全不需要额外训练,推理时就能自动完成。
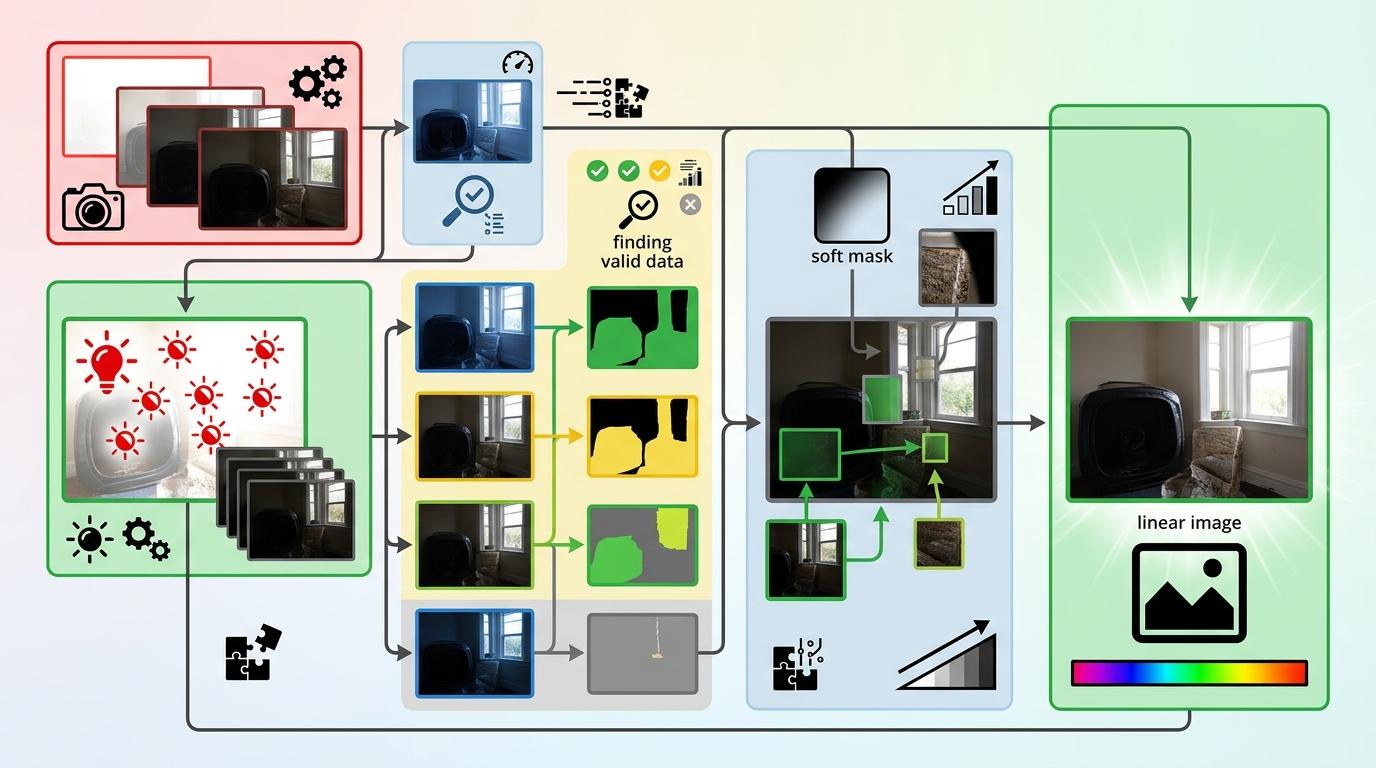
在Adobe FiveK数据集的测试中,这个方法的亮度比例(LS)指标达到了23.06,是所有对比模型里最高的——这个指标衡量的是图像最亮和最暗部分的亮度差,数值越高,动态范围越大。直观来看,其他模型生成的图像,拉亮阴影后高光会直接过曝;而这个方法生成的线性图像,拉亮阴影后,天空的云彩、水面的反光依然清晰。
但它也不是完美的:在极端光照条件下(比如纯黑背景下的强光物体),四张包围图之间可能会出现微小的亮度不一致;训练数据主要是日常摄影场景,对于显微镜、天文摄影这类特殊场景,泛化能力还有待验证;而且推理时要生成四张图,计算量是普通AI生图的四倍,消费级显卡上生成速度会慢不少。
不过这些问题都挡不住它的实用价值:生成的线性图像可以直接用FlowEdit做无微调编辑,用ControlNet做结构引导,甚至可以直接进行线性图像的修复——相当于AI给了你一个装满“原始素材”的工具箱,而不是一件已经做好的成品。
这不是AI生图的又一次“风格升级”,而是一次“逻辑回归”——它终于回到了摄影的本质:光线。以前AI是帮你画一幅“看起来像照片的画”,现在它是帮你生成“可以当照片用的素材”。
你可以想象一下未来的创作场景:在Photoshop里输入“夕阳下的海边,逆光,人物站在礁石上”,AI直接给你一张线性图像,你不用再担心高光过曝,不用再纠结阴影死黑,随便调曝光、改白平衡,怎么修都有细节。给创作者素材,比给成品更重要——这就是这个突破最珍贵的地方:它没有把AI变成一个“自动画画机”,而是把它变成了一个专业摄影师的得力助手。