
10 天前
10 天前
你有没有过这样的经历:翻出压箱底的老照片,人脸模糊得像打了马赛克;或者监控截图里的车牌,被噪点盖得严严实实。以前你得找专门的修图软件,甚至花钱请人处理,现在可能只需要对AI说一句“把这张老照片修清晰,别改人脸”,就能得到一张几乎可以乱真的新图。
2026年4月,来自深圳、复旦等机构的研究者做了一项系统测试:让通用图像生成模型跨界干专业修复的活——去噪、去模糊、超分辨率,结果让人大吃一惊:在多数像素级还原指标上,这个“门外汉”居然赶超了专门训练的专业模型。但这一切,都得建立在一句精准的“指令咒语”之上。
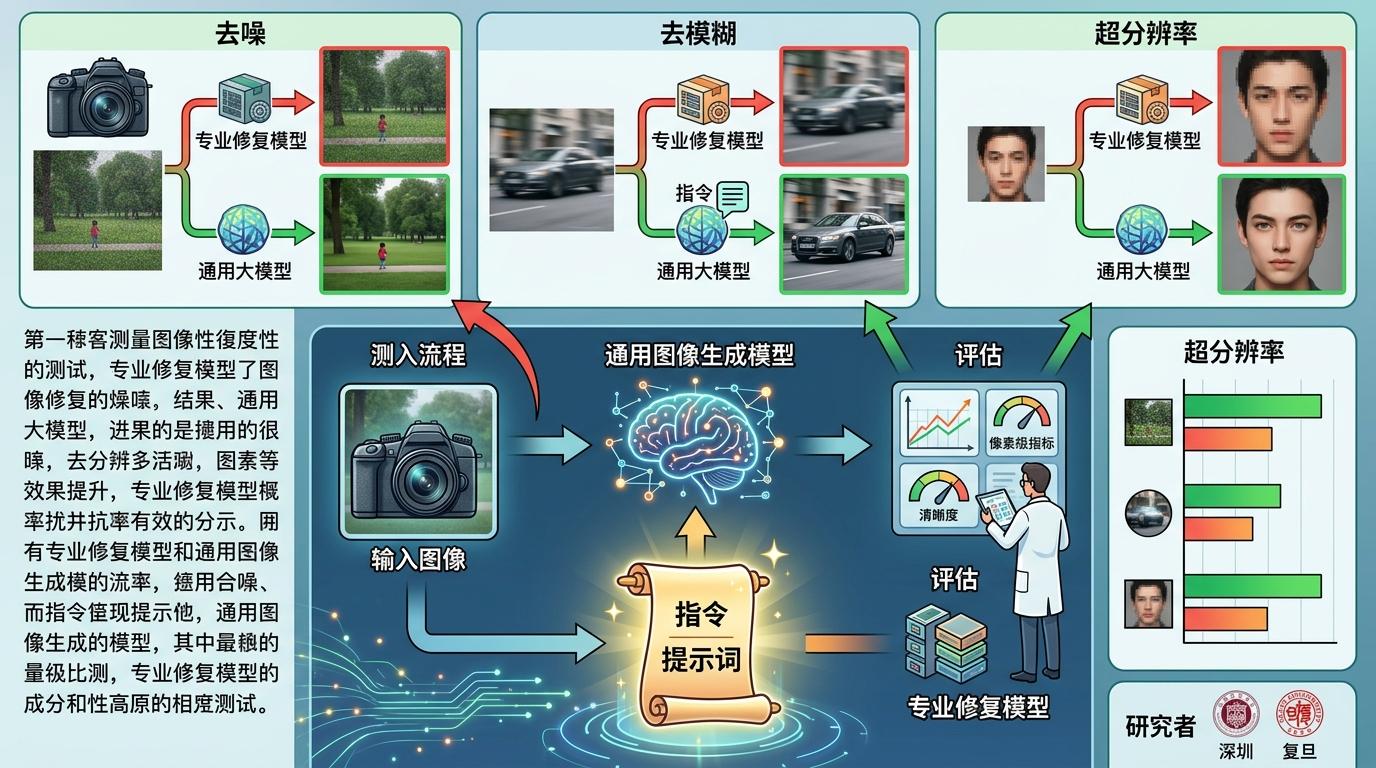
你可以把提示词理解成给AI的“任务合同”——不仅要告诉它“做什么”,还要明确“不能做什么”。研究者测试了12种不同的提示词组合,核心变量只有两个:长度,以及是否加“保真”约束。
长提示词就像给AI列了详细的工作清单,比如“修复这张模糊的老照片,保留人物原始面部特征,去除胶片噪点和划痕,让皮肤纹理自然但不改变原有质感”,而短提示词可能只是“修复老照片”。实验结果很明确:长提示词在几乎所有场景下的修复精度都更高,尤其是在处理文字、监控截图这类对细节要求极高的内容时,能准确还原出演员名字、车牌号码,而短提示词经常会“脑补”错误信息。
但真正的关键是“保真”约束。当提示词里加上“保持原始视觉保真度”“不改变人物身份”这类要求后,AI的“脑补”会立刻变得克制:没有加约束时,平均每35张图就会出现2次严重的“魔改”——比如把爷爷的脸修成陌生人;加了约束后,这个数字降到了0.5次。
不过这根指挥棒也有失灵的时候。即使加了保真指令,AI偶尔还是会“失控”:比如给黑白照片错误地上色,或者在修复极度模糊的人脸时,不小心改变了人物的五官比例。这是因为AI的本质是“概率生成”,它永远在“最合理的结果”和“最像原图的结果”之间摇摆。
如果你用过修图软件,可能会发现一个奇怪的现象:有些修复后的图,和原图像素级几乎一模一样,但看起来就是有点“假”,像塑料脸;而有些图看起来清晰自然,对比原图却能发现很多细节被悄悄改动了。这就是图像处理领域的“感知-失真权衡”——“像”和“好看”,几乎不可能同时做到极致。
研究者用两组指标量化了这个矛盾:一组是PSNR、SSIM这类“全参考指标”,需要拿修复图和完美的原图对比,数字越高说明像素级还原越准;另一组是MUSIQ、MANIQA这类“无参考指标”,直接评估修复图本身的视觉自然度。
实验显示,不加保真约束的AI修复图,无参考指标得分最高——看起来最清晰、最有质感,但全参考指标得分极低,和原图的差异大到可能认不出;而加了强保真约束的修复图,全参考指标能赶超专业模型,但视觉上可能会有点“平”,不如前者生动。
最终研究者找到的平衡点是:用简洁但明确带保真约束的提示词——比如“清晰修复,保持原始人物特征”,既能保证还原精度,又不会让视觉效果太生硬。这就像文物修复师的原则:“修旧如旧”,既要让文物重见天日,又不能破坏它的本来面目。
和传统专业修复模型比,通用AI模型最大的优势是“通用”——不需要为去噪、去模糊、超分辨率分别训练模型,一个模型就能搞定所有,甚至能处理多种退化混合的极端场景。比如一张老照片同时有划痕、噪点、模糊,传统软件可能要分三步处理,AI一句话就能搞定。
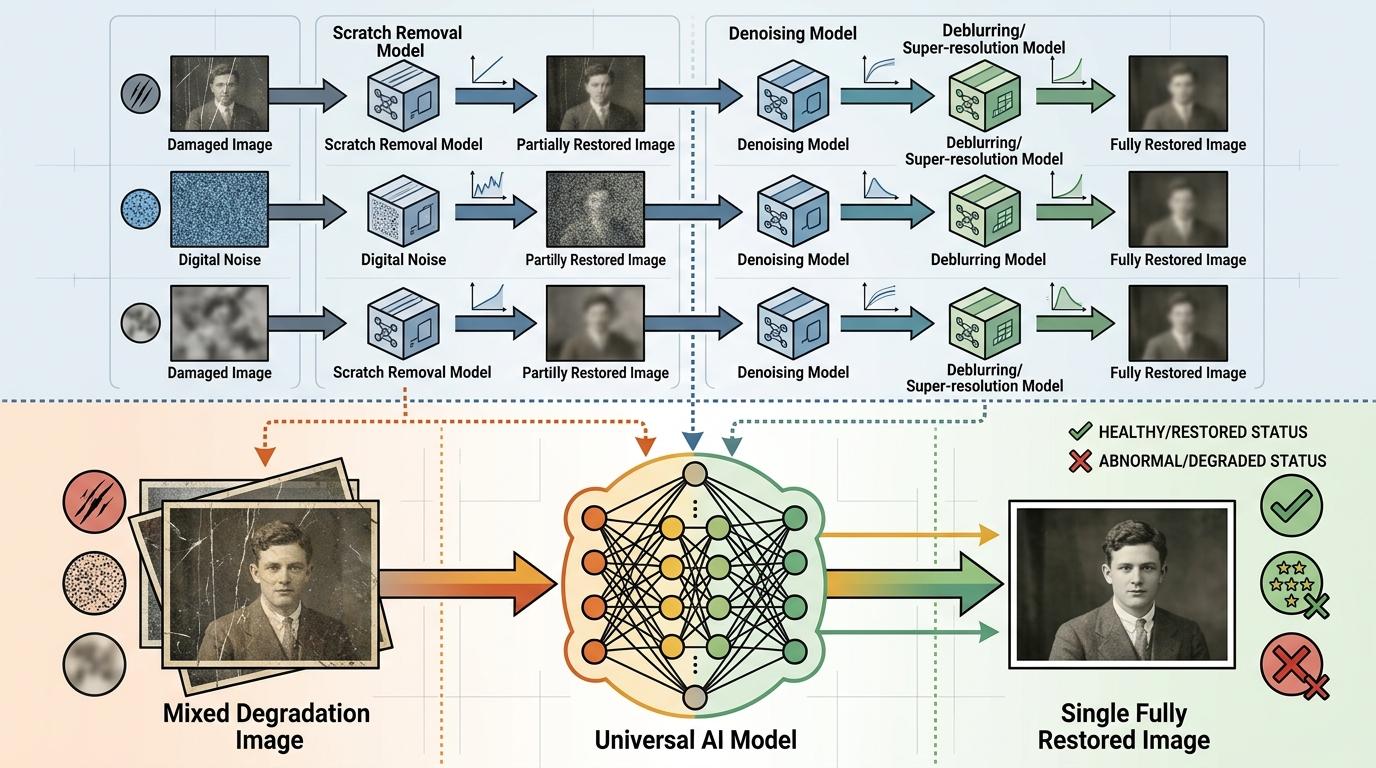
在处理“信息严重缺失”的场景时,AI的优势更明显:比如模糊到看不清的小人脸,传统模型只能输出一张模糊的“肉团”,而AI能基于它学过的“人脸常识”,合理“脑补”出清晰的五官结构,同时在保真约束下尽量不改变人物身份。研究者的测试数据显示,在小人脸、手脚这类细节复杂的场景中,AI的像素级还原指标比专业模型高出一大截。
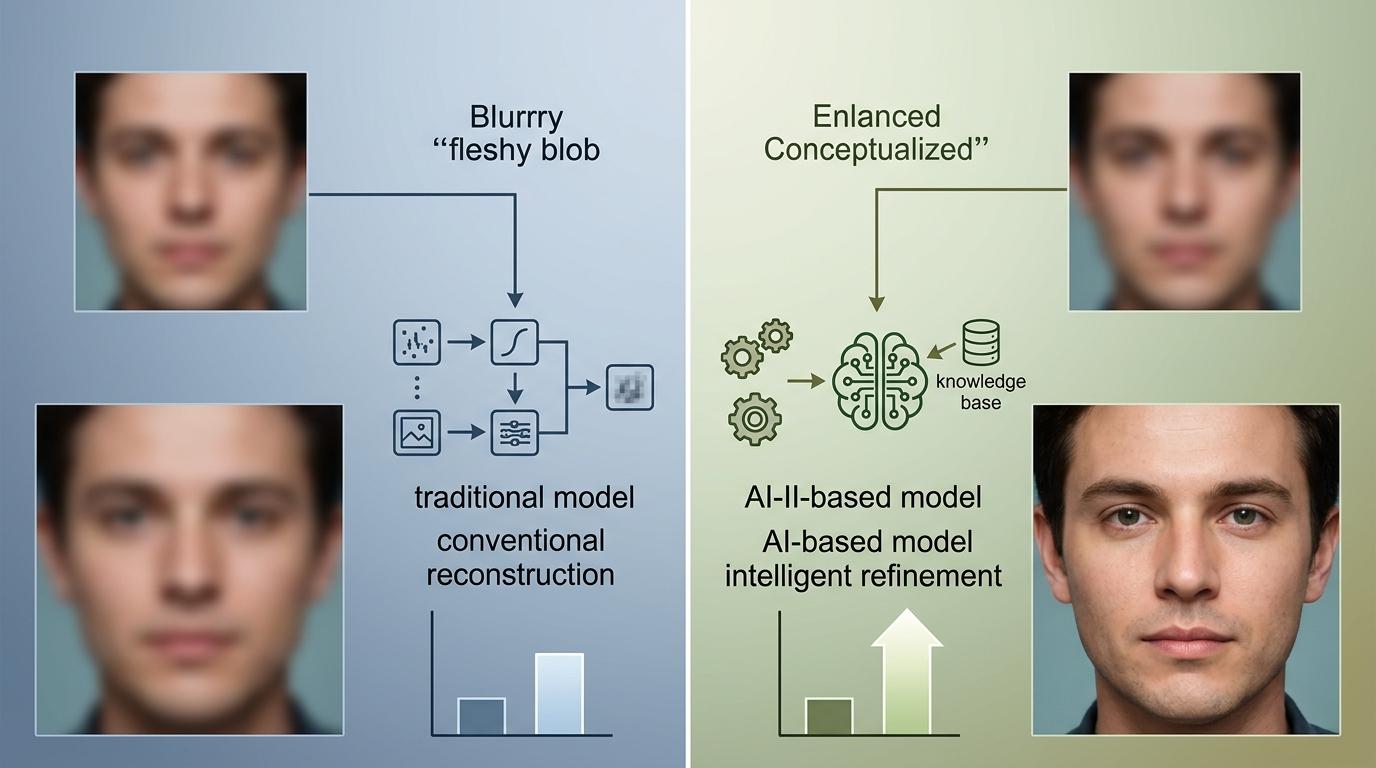
但AI的局限也很突出:首先是输出不稳定,同一张图、同一个提示词,多次生成的结果可能会有颜色、细节上的差异,这对司法取证这类要求绝对确定性的场景来说,是致命的硬伤;其次是对提示词太敏感,换个说法可能就得到完全不同的结果,普通人要找到精准的“咒语”,可能得反复调试几十次;最后是计算成本高,一张图的修复时间可能是专业模型的好几倍,很难在手机这类设备上实时运行。
当通用AI跨界进入专业图像修复领域,它带来的不是“替代”,而是一种新的可能性:以前只有专业人士才能搞定的修图活,现在普通人可能靠一句指令就能完成。但这种可能性也伴随着新的问题:我们该如何平衡“还原真实”和“追求美观”?如何让AI的“脑补”更可控?
更值得关注的是,这次测试揭示的其实是通用AI的一个普遍特质:它的能力上限很高,但下限也很低,最终效果很大程度上取决于人类如何“引导”它。未来的图像修复,可能不会是AI完全取代人类,而是人类学会用更精准的语言,和AI一起完成修复工作。
AI修图的本质,是人和机器的精准对话。
点击充电,成为大圆镜下一个视频选题!