
17 天前
17 天前
给AI看一张“人拿着头盔”的照片,它大概率会说“人戴着头盔”——不是它看错了,是它太相信“戴头盔”这个语言里的常见搭配,反而忽略了眼前的真实画面。这种“睁眼说瞎话”的毛病,名叫对象幻觉,是多模态AI落地的最大信任障碍:它会凭空编出图里没有的东西,把红的说成蓝的,把“拿着”说成“戴着”,在医疗诊断、自动驾驶这些高风险场景里,足以酿成大错。过去人们要么花大成本重新训练模型,要么在图像上做手脚逼它“认错”,但都治标不治本。直到北航的研究团队拿出了AFTER——一种不用改模型、只在它“思考”时悄悄掰正思路的方法。
你可以把多模态AI想象成一个记性很好但不爱看题的学生:它背了几百万条“语言常识”——比如“人通常戴头盔”“猫喜欢在沙发上”,但面对眼前的题目(图像),它总忍不住直接默写背过的答案,根本不仔细看题。
这种毛病的根源,是语言先验压过了视觉证据。AI的多模态能力是从海量图文数据里学来的,但数据里的语言搭配规律比零散的视觉细节强得多:“戴头盔”在文本里出现的次数远多于“拿头盔”,AI就会默认这是“正确答案”。
之前的纠偏方法,要么是让AI重新做一遍“看图说话”的练习题(微调模型),成本高到离谱;要么是把图像模糊处理,逼AI“仔细看”——但这种“惩罚式”的方法,既没告诉AI什么是“正确答案”,也没法应对不同问题的不同偏见:问“车顶上有什么”和问“图里有几个人”,AI需要关注的细节完全不一样,用同一种方法纠错,自然效果有限。
AFTER的核心思路很简单:不用改AI的“记忆”,只在它“思考”的时候,用事实给它的思路装个导航。它分成两步走,精准解决了之前方法的两大痛点。
第一步,用事实造个“正确思路模板”。研究团队从图像的真实标注里,抠出三类关键事实:图里有什么物体(类别事实)、每个物体的颜色数量(属性事实)、物体之间的位置关系(关系事实),再把这些零散的事实拼成一句通顺的“真话描述”——比如把“人、头盔、手持”拼成“一个人手里拿着头盔”。然后把这句真话喂给AI,记录下它“说真话”时的内部思考状态,再和它之前“说假话”的状态对比,算出一个“从假话掰到真话”的通用编辑向量。
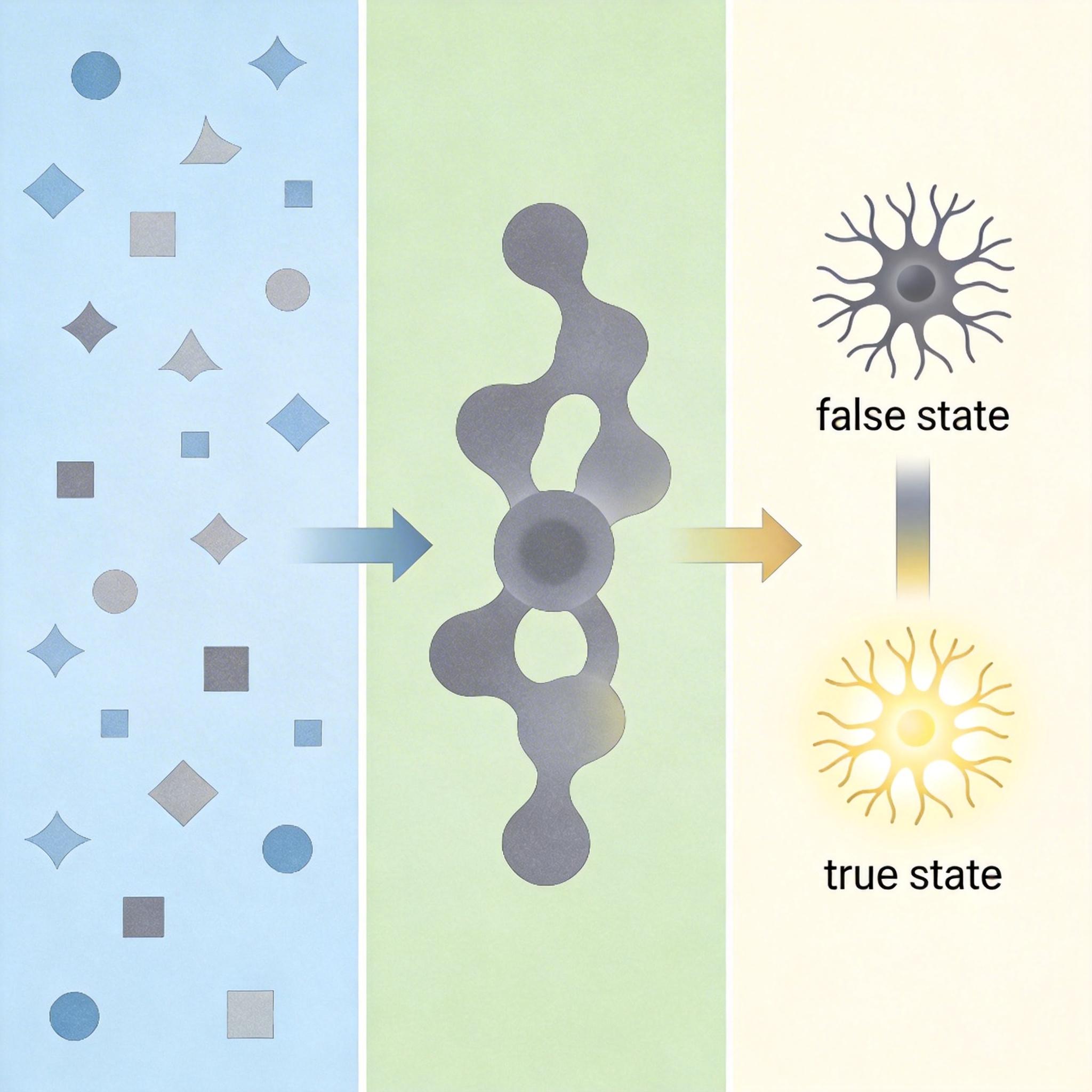
第二步,给不同问题定制“导航路线”。同一张图,问“人拿着什么”和问“人戴着什么”,AI的偏见完全不同。AFTER会先分析问题的关注点,从事实里抽出对应的部分——比如问“拿着什么”,就只关注“手持头盔”这个事实,再算出针对这个问题的专属偏移量,和通用编辑向量结合,精准掰正AI的思路。

直给补刀:整个过程不用微调AI的任何参数,只在推理时修改它的内部激活状态,相当于医生不用给病人做手术,只在他犯糊涂时轻轻拍醒他。
在三个主流多模态AI和三大标准测试集上,AFTER的表现超出预期:
更难得的是,它没让AI为了“说真话”牺牲回答的全面性。在AMBER生成式测试里,AI的回答覆盖度几乎没变,只是把里面的瞎话删掉了——就像那个爱默写的学生,终于学会了先看题再答题,既没丢分,也没漏题。
当然,它也有局限:目前只能用于开源AI,闭源模型因为看不到内部激活状态,没法用这套方法;在医疗这种专业领域,还需要专门的领域事实库来支撑,不然AI还是会说外行话。
当我们在追求AI的“聪明”时,往往忘了它最基础的要求:说真话。AFTER的价值,不在于它让AI变得更聪明,而在于它找到了一种低成本的方法,让AI“做回自己”——不是一个只会默写常识的机器,而是一个能看懂眼前世界的助手。
未来的AI,不该是一个背答案的优等生,而该是一个会看题的实干家。毕竟,在真实世界里,靠谱比聪明更重要。
点击充电,成为大圆镜下一个视频选题!